
Decoded©
-
Scatter Plot : Définition et Applications
La visualisation des données dans le monde de la data science est de nos jours au cœur de la pipeline du machine learning. La data visualization est ainsi l’une des étapes de la science des données, qui intervient juste après la collecte, le nettoyage et la normalisation des données. De nos jours, l’un des graphiques les plus utilisés est le scatter plot. Ce dernier nous permet d’analyser les données et voir les interactions entre les variables.
Lire la suite -
Music Tags Inspyrer, l’AI mélomane
Classification automatique du genre musical par un algorithme de Machine Learning L’Intelligence Artificielle commence à être bien connue pour ses capacités étonnantes et remarquables dans le domaine de la « vision par ordinateur » (classification d’images, reconnaissance faciale, …) ou le domaine du son avec la reconnaissance vocale. Qu’en est-il dans un domaine en apparence plus abstrait […]
Lire la suite -
Mushroom recognition : How computer vision can aid in the identification of species
Context One of the most widely used and oldest species identification techniques is « morphological identification », which identifies individuals by their anatomical characteristics. However, this technique has the disadvantage of not being always accurate since it depends on the observation and the identification protocol of the person who performs it. An alternative to this identification technique […]
Lire la suite -
Python Class : tout savoir sur les classes d’objets
Dans le cadre d’un projet de Data Science ou tout autre projet de programmation en Python, vous serez souvent amené à utiliser de nombreuses fonctions et variables créées par vos soins. Vous pouvez même avoir besoin de créer un script complet regroupant de nombreuses fonctions créées par vos soins dans le but de fluidifier votre projet. Ces fonctions peuvent remplir de nombreux rôles. Il peut s’agir de nettoyer un DataFrame, ou tout simplement d’entraîner un modèle de Machine Learning. La création de fonctions est très utile pour optimiser le code Python. Toutefois, il existe une autre méthode : l’utilisation d’une Python Class.
Lire la suite -
Data Leak ou fuite de données : comment s’en prémunir ?
Bien que les termes « violation de données » et « fuite de données » soient souvent utilisés de manière interchangeable, il s’agit de deux types d’exposition aux données distincts :
Lire la suite -
Informatica : l’éditeur de solutions pour la Data Science
Informatica est une société américaine de développement de logiciels créée en 1993. Son siège social se trouve à Redwood City, en Californie. Ses principaux produits incluent PowerCenter, Big Data Management, Informatica Data Quality et bien d’autres encore.
Lire la suite -
Construire des API avec différentes applications (Partie I)
Nous avons vu dans les trois précédents articles un premier exemple de programmation d’une API Web sous Flask, comment connecter une API Web à une base de donnée SqLite et comment programmer et documenter une API Web avec Python, Flask, Swagger et Connexion. Nous allons voir dans cet article et le prochain comment combiner ces éléments avec la gestion d’une base de données à l’aide de SQLAlchemy et Marshmallow.
Lire la suite -
L’Open Data, une mine d’or accessible à tous
L’Open Data correspond à l’ensemble des données publiées et collectées par les administrations publiques et les entreprises. Ces données sont généralement gratuites ou à très faible coût et sont facilement accessibles.
Lire la suite -
Construire des API avec différentes applications (Partie II)
Nous avons vu dans les quatre précédents articles un premier exemple de programmation d’une API Web sous Flask.
Lire la suite -
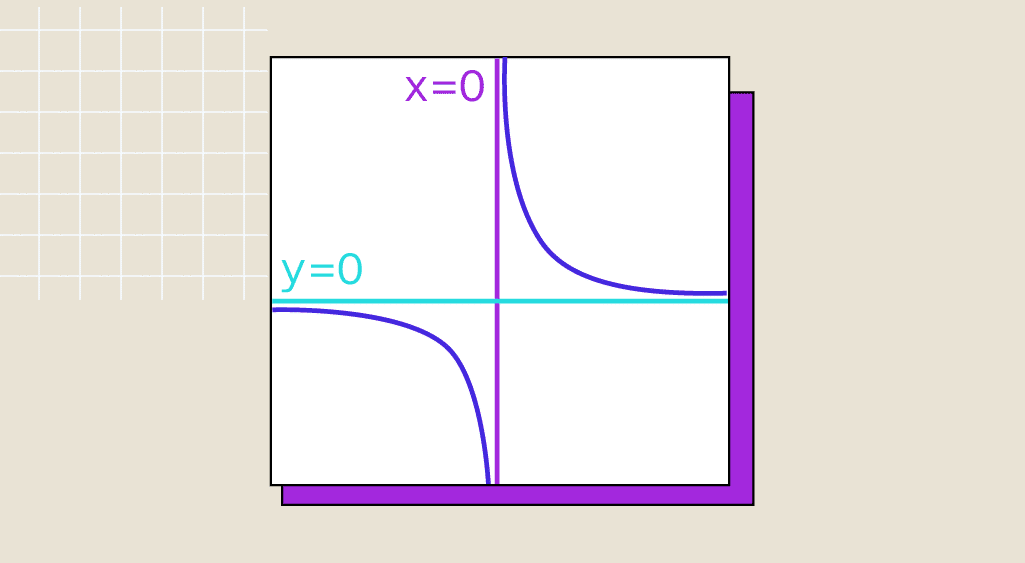
Limite d’une fonction : comment la déterminer ?
Toutes les disciplines scientifiques se basent sur les mathématiques et la data science n’y fait pas exception. Lorsque les problèmes à résoudre sont des problèmes d’optimisation, il est nécessaire de maîtriser ce qu’est la limite d’une fonction. Dans cet article, vous découvrirez comment déterminer la limite d’une fonction.
Lire la suite -
AttGAN : un outil de modification des attributs du visage
La modification des attributs du visage, aussi appelé Facial Attribute Editing, désigne l’ensemble des méthodes qui ont pour but de modifier un ou plusieurs attributs d’un visage donné. Avant l’arrivée du Deep Learning, cette tâche était fastidieuse car faite à la main pixel par pixel. Mais, depuis peu, de nouveaux algorithmes ont vu le jour et permettent d’automatiser cette cette modification. Nous allons ici étudier en détail le modèle AttGAN qui fait partie de ces algorithmes basés sur les réseaux de neurones. Cet algorithme prend en paramètre le visage que nous voulons modifier ainsi qu’un vecteur d’attribut binaire et renvoie le visage modifié avec les attributs voulus. Des exemples de son fonctionnement sont montrés ci-dessous :
Lire la suite -
Data Storytelling : passer des messages percutants avec la data
Le Data Storytelling, c’est l’art de faire passer des informations à travers une histoire, grâce aux données. Cette branche de la business intelligence est de plus en plus populaire et mise en avant pour son efficacité à transmettre un message.
Lire la suite





The newsletter of the future
Get a glimpse of the future straight to your inbox. Subscribe to discover tomorrow’s tech trends, exclusive tips, and offers just for our community.



