

Une intelligence artificielle ou IA, est un programme qui cherche à imiter l’intelligence humaine par le biais d’algorithmes de calcul. Sa création permet aux ordinateurs de réaliser des opérations et de penser comme un être humain. Depuis 2010, le développement de l’intelligence artificielle a été accéléré par le big data. Découvrez dans cet article tout ce qu’il y a à savoir sur l’intelligence artificielle.
Qu’est-ce que l’intelligence artificielle ?
Selon John McCarthy, l’un des pionniers du domaine, c’est « la science et l’ingénierie de la fabrication de machines intelligentes« . L’intelligence artificielle (IA) est un domaine de l’informatique qui cherche à créer des systèmes capables de réaliser des tâches qui nécessiteraient normalement l’intelligence humaine. Dans le cadre réglementaire européen, le Parlement européen définit l’IA comme tout outil utilisé par une machine capable de « reproduire des comportements liés aux humains, tels que le raisonnement, la planification et la créativité » — une définition qui sert également de socle à l’AI Act, le premier cadre juridique mondial encadrant les usages de l’intelligence artificielle.
L’IA est souvent considérée comme un concept vaste et multidimensionnel, difficile à définir précisément en raison de sa nature étendue et en constante évolution. Des technologies allant des simples algorithmes de recommandation utilisés par Netflix aux systèmes complexes de conduite autonome développés par des entreprises comme Tesla, en passant par le deep learning, sont tous considérés comme de l’IA, illustrant la diversité et l’évolution permanente du domaine.
D’où vient le terme intelligence artificielle ?
C’est en 1956 que le terme intelligence artificielle est prononcé pour la première fois, lors de la conférence « Dartmouth Summer Research Project on Artificial Intelligence » organisée par John McCarthy. Cette notion émerge dans la foulée des réflexions du mathématicien Alan Turing, qui s’interrogeait dès 1950 sur la capacité d’un ordinateur à « penser ». Beaucoup considèrent la conférence de Dartmouth comme la véritable naissance de l’intelligence artificielle en tant que discipline académique à part entière.
Depuis lors, le terme a connu une évolution sémantique considérable. En 1959, Arthur Samuel invente le terme de Machine Learning en travaillant chez IBM. En 1989, Yann Le Cun met au point le premier réseau de neurones capable de reconnaître des chiffres écrits à la main, ouvrant la voie au Deep Learning. En 1997, le système Deep Blue d’IBM triomphe du champion du monde d’échecs Gary Kasparov. Aujourd’hui, le terme désigne un spectre très large de technologies — des algorithmes de recommandation aux grands modèles de langage — dont les contours continuent d’évoluer au rythme des avancées technologiques.
Qui est le créateur de l’intelligence artificielle ?
L’intelligence artificielle n’est pas l’œuvre d’une seule personne, mais le fruit des travaux de plusieurs chercheurs et mathématiciens visionnaires. Son histoire débute en 1943, avec la publication de l’article « A Logical Calculus of Ideas Immanent in Nervous Activity » par Warren McCullough et Walter Pitts, qui présentent le premier modèle mathématique pour la création d’un réseau de neurones.
Les pionniers fondateurs de l’IA
- Warren McCullough & Walter Pitts (1943) — Premier modèle mathématique d’un réseau de neurones artificiels, posant les fondements théoriques de l’IA moderne.
- Alan Turing (1950) — Publie le célèbre Test de Turing, qui sert encore aujourd’hui à évaluer la capacité d’une machine à imiter l’intelligence humaine.
- Marvin Minsky & Dean Edmonds (1950) — Créent SNARC, le premier ordinateur à réseau de neurones.
- John McCarthy (1956) — Considéré comme le principal pionnier de l’intelligence artificielle, il prononce pour la première fois le terme lors de la conférence de Dartmouth.
- Arthur Samuel (1959) — Chercheur chez IBM, il invente le terme de Machine Learning.
- Yann Le Cun (1989) — Met au point le premier réseau de neurones capable de reconnaître des chiffres écrits à la main, invention à l’origine du Deep Learning.
Quelles sont les grandes étapes de l’histoire de l’IA ?
L’histoire de l’IA s’étend sur plusieurs décennies, ponctuée de grandes avancées, de périodes de stagnation — les fameux hivers de l’IA — et de révolutions technologiques qui ont progressivement conduit à l’ère des LLM et de l’IA générative.
1. Les prémices : les premiers modèles mathématiques (1940-1950)
L’histoire de l’intelligence artificielle débute en 1943 avec McCullough et Pitts. En 1950, Marvin Minsky et Dean Edmonds créent SNARC, le premier ordinateur à réseau de neurones, et Alan Turing publie le Test de Turing, posant les fondations de la discipline : répliquer ou simuler l’intelligence humaine dans les machines.
2. La naissance officielle du domaine (1956)
C’est en 1956 que le terme intelligence artificielle est prononcé pour la première fois lors de la conférence de Dartmouth. En 1959, Arthur Samuel invente le terme de Machine Learning chez IBM, ouvrant la voie à une nouvelle manière d’apprendre aux machines.
3. Premiers succès et hivers de l’IA (1960-1980)
Les décennies 1960 et 1970 voient l’émergence des premiers programmes d’IA prometteurs comme ELIZA ou Shakey. Cependant, la complexité de la création d’une véritable intelligence se heurte aux limites des ordinateurs de l’époque. Ces périodes de stagnation et de baisse des financements, connues sous le nom d’hivers de l’IA, ralentissent considérablement la recherche.
4. Renouveau et essor du Machine Learning (1980-2000)
Les années 1980 marquent un tournant avec les systèmes experts et l’essor du Machine Learning. En 1989, Yann LeCun ouvre la voie au Deep Learning. En 1997, Deep Blue d’IBM triomphe du champion du monde d’échecs Gary Kasparov : pour la première fois, la machine a vaincu l’Homme.
5. L’essor du Deep Learning et du Big Data (2010-2020)
À partir de 2010, la puissance de calcul, le Big Data et les avancées en Deep Learning alimentent une véritable révolution. Les systèmes d’IA atteignent des niveaux de performance inédits en vision par ordinateur, reconnaissance vocale et traitement du langage naturel (NLP).
6. L’ère des LLM et de l’IA générative (2020 à aujourd’hui)
Depuis le début des années 2020, l’IA entre dans une nouvelle ère dominée par les Large Language Models (LLM) et l’IA générative. Le lancement de ChatGPT en novembre 2022 marque un tournant grand public. Parallèlement, les agents IA — capables de planifier, raisonner et agir de manière autonome — ouvrent la voie à une IA encore plus performante, promettant de redéfinir durablement notre rapport au travail et à la technologie.
Comment fonctionne une intelligence artificielle ?
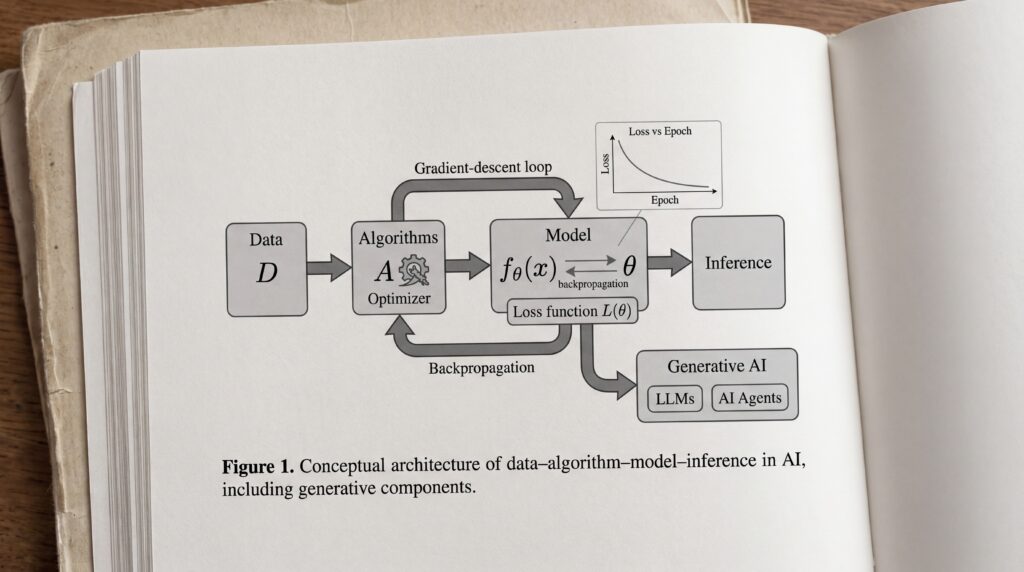
Le fonctionnement d’une intelligence artificielle repose sur quatre briques fondamentales : les données, les algorithmes, le modèle et l’inférence. Les systèmes d’IA se basent sur le machine learning et le deep learning pour s’améliorer en continu. Grâce à des réseaux neuronaux artificiels, une IA peut apprendre des relations entre les données d’entrée et les sorties attendues, ajuster ses paramètres internes via la backpropagation et améliorer sa précision.
Données, algorithmes et modèles
- Les données : matières premières de l’IA. La qualité et le volume de ces données sont directement déterminants pour les performances du système.
- L’algorithme : méthode de calcul qui définit les règles d’apprentissage et la manière dont le modèle identifie des schémas, corrige ses erreurs et ajuste ses paramètres via la descente de gradient.
- Le modèle : résultat de l’entraînement — une structure mathématique capable de généraliser sur de nouveaux exemples.
- L’inférence : phase durant laquelle un modèle déjà entraîné produit une prédiction ou une décision à partir de nouvelles données. Lorsque vous interrogez un chatbot ou qu’un algorithme classe une image, vous êtes dans une phase d’inférence.
IA générative, LLM et agents IA
IA générative et grands modèles de langage
L’IA générative est la technologie capable de produire du contenu — textes, réponses, images — à partir d’un contexte donné. Au cœur de ces systèmes se trouvent les LLM (Large Language Models) : des modèles spécialisés dans la compréhension et la génération de texte. Des exemples comme GPT et BERT illustrent la capacité de ces modèles pour des tâches allant de la génération de texte à la traduction automatique. C’est avec le lancement de modèles tels que GPT-3, DALL·E et ChatGPT au début des années 2020 que l’IA générative est devenue largement accessible.
Agents IA : l’autonomie au cœur de l’IA
La prochaine frontière est celle des agents IA : des programmes capables d’agir de manière autonome pour comprendre, planifier et exécuter des tâches complexes. Alimentés par des LLM, ils peuvent interagir avec des outils et d’autres modèles pour atteindre les objectifs de l’utilisateur — contrairement à un simple chatbot qui répond à une commande directe. Gartner a identifié l’IA agentique comme la première tendance technologique stratégique pour 2025, avec un marché mondial qui devrait croître à un taux annuel composé de 46,2 % entre 2025 et 2030.
Quels sont les types d’intelligence artificielle ?

Les chercheurs s’accordent pour discerner 3 grands types d’intelligence artificielle, classés selon leur niveau de capacité et leur degré d’autonomie cognitive.
| Type d’IA | Niveau de capacité | Statut actuel | Exemple |
|---|---|---|---|
| IA faible (Narrow AI) | Tâche unique et spécifique | Existante et très répandue | Recommandations Netflix, reconnaissance vocale |
| IA forte | Conscience et sentiments propres | Théorique, inexistante | Scénarios de science-fiction |
| IA générale (AGI) et super-intelligence | Toutes les tâches cognitives humaines, puis au-delà | Hypothétique, en recherche active | AGI : débat autour de GPT-4 ; Super-IA : concept futur |
IA faible (Narrow AI)
L’IA faible, aussi appelée IA étroite ou Narrow AI, est un système conçu pour réaliser une seule tâche de manière quasi parfaite. C’est le type d’IA le plus utilisé à ce jour. Les assistants vocaux comme Siri ou Alexa, les systèmes de recommandation de Netflix ou Spotify, la reconnaissance faciale, les filtres antispam ou encore les chatbots de service client en sont tous des exemples. Malgré ses avantages, des données d’entraînement de mauvaise qualité peuvent entraîner des résultats biaisés aux conséquences graves dans des applications sensibles comme l’approbation de prêts ou le recrutement.
IA forte
On parle d’IA forte lorsqu’un modèle désigne théoriquement un système doté d’une véritable vie intérieure : émotions, subjectivité, conscience de soi. Proche d’un scénario de science-fiction, les chercheurs pensent que l’IA forte est impossible à créer actuellement : la notion de conscience ne peut voir le jour dans des systèmes qui manipulent uniquement des symboles et des calculs.
IA générale (AGI) et super-intelligence
L’IA générale (AGI) est une intelligence artificielle capable de réaliser n’importe quelle tâche cognitive comme le ferait un humain. Toujours considérée comme hypothétique, certains scientifiques s’interrogent sur GPT-4 comme première forme d’AGI. Au-delà, la super-intelligence artificielle désigne une entité consciente d’elle-même, indépendante du contrôle humain et surpassant considérablement l’intelligence humaine. Ces concepts suscitent de vives inquiétudes éthiques, ce qui justifie des réglementations comme l’AI Act européen.
Quels sont les principaux modèles et architectures d’IA ?
Les modèles d’intelligence artificielle se déclinent en plusieurs familles techniques, chacune reposant sur des architectures et des principes distincts. Du Machine Learning classique aux grands modèles multimodaux, voici un panorama des principales architectures qui façonnent l’IA moderne.
Machine Learning
Le Machine Learning est un sous-domaine de l’IA qui permet aux systèmes de tirer des enseignements à partir de données et d’améliorer leurs performances sans être explicitement programmés pour chaque tâche. Les algorithmes de recommandation de Netflix ou Spotify, les filtres antispam et les modèles de scoring bancaire en sont des exemples concrets : dans chaque cas, le modèle a appris à partir de données historiques pour généraliser ses prédictions.
Deep Learning
Le Deep Learning est une forme avancée de Machine Learning utilisant des réseaux neuronaux profonds pour traiter d’énormes quantités de données. Contrairement au Machine Learning classique qui nécessite souvent une extraction manuelle des caractéristiques, le Deep Learning apprend de façon autonome des représentations hiérarchiques directement depuis les données brutes — un modèle peut ainsi distinguer un chat d’un chien sur une photo sans qu’un développeur ait défini ce qu’est une oreille ou un museau.
Réseaux de neurones (CNN, RNN, Transformers)
| Architecture | Principe clé | Applications typiques |
|---|---|---|
| CNN (Convolutional Neural Network) | Applique des filtres de convolution pour détecter des motifs locaux dans les données spatiales | Reconnaissance d’images, détection d’objets, vision par ordinateur, diagnostic médical par imagerie |
| RNN (Recurrent Neural Network) | Traite les données en séquence en conservant une mémoire des étapes précédentes | Traduction automatique, reconnaissance vocale, analyse de séries temporelles |
| Transformer | Repose sur un mécanisme d’attention qui pondère l’importance de chaque élément d’une séquence | Grands modèles de langage (GPT, BERT), traduction, résumé automatique, génération d’images |
Les Transformers, introduits en 2017 par Google avec l’article Attention Is All You Need, constituent aujourd’hui la base architecturale des modèles de langage les plus puissants comme GPT ou BERT, et s’étendent désormais bien au-delà du texte.
LLM et modèles multimodaux
Les Large Language Models (LLM) sont des réseaux Transformer entraînés sur des quantités massives de données textuelles, capables de comprendre et de générer du langage naturel de manière très fluide. La tendance la plus structurante est l’émergence des modèles multimodaux, capables de traiter simultanément texte, image, audio et vidéo. Des modèles comme GPT-4o ou Gemini peuvent analyser une image, répondre à des questions depuis un document scanné ou transcrire un fichier audio — percevant et générant de l’information de façon aussi diversifiée qu’un être humain.
Quelles sont les méthodes d’apprentissage d’une IA ?
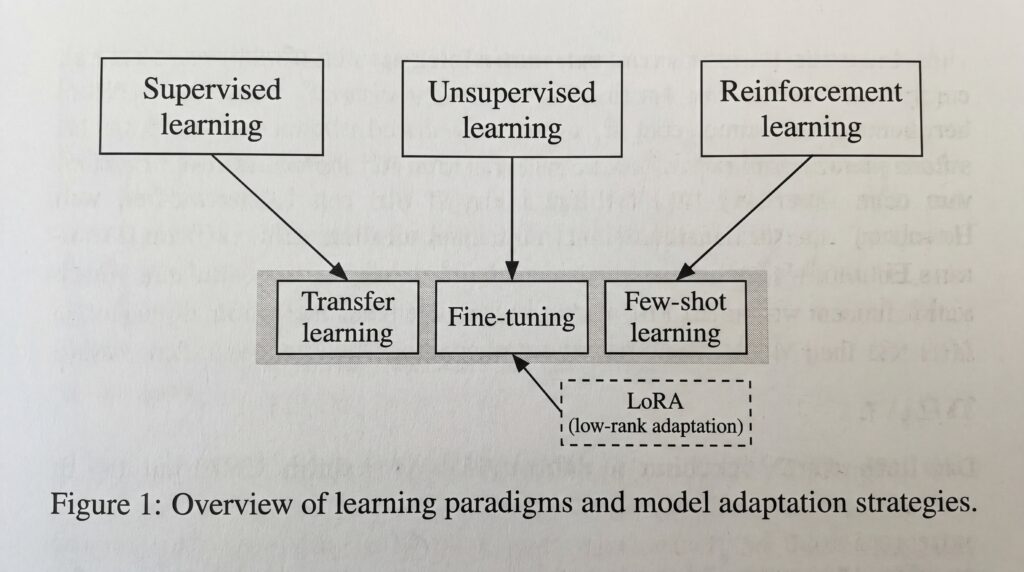
Les méthodes d’apprentissage varient en fonction des besoins, des données disponibles et des objectifs visés. De l’apprentissage classique sur données étiquetées aux techniques modernes utilisées pour adapter les grands modèles de langage (LLM), chaque approche répond à des problématiques spécifiques.
Apprentissage supervisé (supervised learning)
L’apprentissage supervisé est la méthode la plus courante : le modèle apprend à partir de données étiquetées, chaque donnée d’entrée étant associée à une sortie attendue. Un filtre anti-spam apprend à distinguer les e-mails légitimes grâce à des milliers d’exemples préalablement classifiés ; les algorithmes de classification d’images médicales et les modèles de prédiction financière reposent sur ce même paradigme.
Apprentissage non supervisé (unsupervised learning)
Dans l’apprentissage non supervisé, le modèle explore des données non étiquetées pour en extraire des motifs cachés, sans indication préalable. Les techniques de clustering et de réduction de dimensionnalité permettent de découvrir des groupes d’utilisateurs similaires dans le marketing, de détecter des anomalies financières ou de comprendre la structure de données complexes sans labels existants.
Apprentissage par renforcement (reinforcement learning)
L’apprentissage par renforcement est un paradigme où un agent apprend en interagissant avec un environnement et en recevant des récompenses ou des punitions selon ses actions. Le cas le plus célèbre est AlphaGo de DeepMind, qui a battu les meilleurs joueurs mondiaux au jeu de Go en 2016. Plus proche du quotidien, cette méthode est au cœur des systèmes de contrôle de robots et de l’entraînement des LLM via la technique RLHF (Reinforcement Learning from Human Feedback), utilisée notamment pour affiner ChatGPT.
Transfer learning, fine-tuning et few-shot learning
Avec l’essor des LLM, trois techniques complémentaires sont devenues incontournables. Le transfer learning réutilise un modèle pré-entraîné sur une tâche comme point de départ pour en apprendre une nouvelle. Le fine-tuning adapte ce modèle sur un dataset spécifique plus réduit pour des performances supérieures sur des domaines spécialisés. Le few-shot learning guide un modèle via le prompt avec seulement quelques exemples, sans modifier ses poids.
| Technique | Principe | Données nécessaires | Cas d’usage typique |
|---|---|---|---|
| Transfer learning | Réutiliser un modèle pré-entraîné comme base pour une nouvelle tâche connexe | Peu de données pour la nouvelle tâche | Adapter ResNet (vision) ou BERT (NLP) à un domaine spécifique |
| Fine-tuning | Continuer l’entraînement d’un modèle pré-entraîné sur un dataset spécifique | Quelques milliers d’exemples labellisés | Spécialiser GPT sur des données médicales, juridiques ou d’entreprise |
| Few-shot learning | Guider un modèle via le prompt avec quelques exemples en contexte, sans modifier ses poids | 2 à 10 exemples suffisent | Classifier des textes ou extraire des entités avec GPT-4 via prompting |
Ces trois techniques forment un continuum d’adaptation. En pratique, le few-shot learning ne requiert aucune modification du modèle et reste accessible via une simple API, tandis que le fine-tuning offre des performances supérieures sur des domaines très spécialisés mais exige des données labellisées et une infrastructure de calcul adaptée. Des techniques comme LoRA permettent aujourd’hui d’affiner uniquement un sous-ensemble réduit de paramètres.
Comment entraîner et déployer une intelligence artificielle ?
Créer une IA performante est un cycle de vie complet qui va de la collecte des données jusqu’à la surveillance en production :
- Collecte et préparation des données
- Entraînement et optimisation du modèle
- Déploiement, MLOps et monitoring
Collecte et préparation des données
La qualité des données conditionne directement la qualité du modèle : un jeu de données biaisé ou incomplet produira inévitablement des prédictions inexactes. Les principales étapes sont :
- Identification des sources : bases de données internes, API, fichiers plats, données web ou capteurs.
- Nettoyage et dédoublonnage : suppression des valeurs manquantes, correction des anomalies et harmonisation des formats.
- Étiquetage (annotation) : en apprentissage supervisé, chaque donnée doit être associée à une sortie attendue.
- Feature engineering : sélection et transformation des variables pertinentes.
- Découpage train/validation/test : séparation du jeu de données pour entraîner, ajuster et évaluer le modèle de façon indépendante.
Entraînement et optimisation du modèle
Le modèle est nourri avec les données pour en extraire des motifs. Les erreurs de prédictions sont analysées via des fonctions de coût, et le modèle ajuste ses poids internes par descente de gradient. L’optimisation passe notamment par le réglage fin des hyperparamètres — taux d’apprentissage, taille de lot, nombre d’époques — qui influencent directement la capacité à généraliser et à éviter le surapprentissage. Des techniques comme la validation croisée k-fold, la recherche par grille et l’optimisation bayésienne permettent de déterminer les meilleurs réglages.
Déploiement, MLOps et monitoring
Un modèle bien entraîné ne crée de valeur réelle qu’une fois déployé en production. Le MLOps (Machine Learning Operations) désigne l’ensemble des pratiques permettant d’industrialiser, automatiser et superviser les modèles en production. Une fois déployé via une API, le modèle doit être surveillé en continu pour détecter le data drift — la dérive progressive des données réelles par rapport aux données d’entraînement — qui peut dégrader silencieusement les performances. Un bon pipeline MLOps garantit reproductibilité, collaboration et stabilité en production.
Comment évaluer la performance d’une IA ?
Pour mesurer objectivement ce qu’une IA sait faire, chercheurs et ingénieurs s’appuient sur des métriques — indicateurs chiffrés qui quantifient la qualité des prédictions — et sur des benchmarks, jeux de tests standardisés permettant de comparer les modèles sur des tâches précises.
Les métriques clés
| Métrique | Ce qu’elle mesure | Quand l’utiliser |
|---|---|---|
| Accuracy | Pourcentage de prédictions correctes | Classification de texte, réponse à des questions |
| Score F1 | Équilibre entre précision et rappel | Données déséquilibrées, prédictions catégorielles |
| Perplexité | Capacité d’un LLM à prédire un échantillon de texte | Évaluation des grands modèles de langage |
| Score BLEU | Qualité de la traduction entre deux langues | Tâches de traduction automatique |
Les benchmarks de référence
| Benchmark | Domaine évalué | Description |
|---|---|---|
| ImageNet (ILSVRC) | Vision par ordinateur | Principal catalyseur de la révolution du deep learning : évalue des modèles sur plus de 1,4 million d’images réparties en 1 000 catégories d’objets. |
| GLUE / SuperGLUE | Compréhension du langage naturel | Collection de tâches NLU incluant question-réponse, analyse des sentiments et inférence textuelle. Introduit en 2018, il est rapidement devenu un standard avant d’être surpassé par les modèles. |
| MMLU | Connaissances générales et raisonnement (LLM) | 16 000 questions à choix multiples couvrant 57 disciplines académiques, testant mémorisation factuelle et raisonnement. Incontournable dans les rapports techniques sur les LLM. |
Aucun benchmark unique ne doit être utilisé seul : un modèle peut obtenir 85 % sur le MMLU mais s’avérer inutilisable pour un cas d’usage précis. La meilleure approche combine plusieurs métriques et benchmarks, complétés par une évaluation humaine des aspects qualitatifs.
Quelles infrastructures et quels coûts pour l’IA ?
GPU et TPU : les moteurs du calcul IA
Entraîner une IA requiert des processeurs spécialisés capables d’effectuer des millions de milliards d’opérations mathématiques en parallèle. Les GPU (Graphics Processing Units), notamment les séries A100 et H100 de NVIDIA, sont les chevaux de bataille de l’IA — NVIDIA détient environ 80 % du marché des GPU dédiés à l’IA en 2024. Face aux GPU, Google a développé ses TPU (Tensor Processing Units), des puces spécialisées ML consommant 60 à 65 % d’énergie en moins que des configurations GPU équivalentes, mais moins polyvalentes.
Le supercalculateur Jean Zay
En France, la recherche publique en IA s’appuie sur le supercalculateur Jean Zay du CNRS/IDRIS, dont la puissance atteint 125,9 pétaflops après son extension de juillet 2024 (1 456 GPU NVIDIA H100). Il permet désormais d’entraîner un modèle complet sur 400 GPU en deux semaines, contre quatre mois en 2022. Jean Zay a notamment servi à entraîner BLOOM, le premier grand modèle de langage open source du consortium BigScience, et valorise sa chaleur émise pour chauffer environ 1 500 foyers.
Le coût d’entraînement et l’empreinte énergétique
L’entraînement des grands modèles représente un investissement colossal : environ 100 millions de dollars pour GPT-4 et 191 millions pour Gemini 1. Certains modèles en cours d’entraînement atteignent déjà un milliard de dollars. Sur le plan énergétique, l’entraînement de GPT-3 a consommé environ 1 287 MWh et émis plus de 500 tonnes de CO₂. La consommation hydrique est un autre enjeu : poser 20 à 50 questions à GPT-3 consommait l’équivalent d’une bouteille d’eau de 50 cl pour refroidir les serveurs. Pour répondre à ces besoins, Microsoft a signé en 2024 un accord pour réactiver le réacteur de la centrale nucléaire de Three Mile Island.
| Élément | Caractéristiques clés | Données chiffrées |
|---|---|---|
| GPU NVIDIA H100 | Puce de référence pour l’entraînement IA, 4x plus rapide que l’A100 | 30 000 – 40 000 $ / unité · 700 W TDP |
| TPU Google (v6e) | Puce spécialisée ML, très efficiente énergétiquement | ~300 W TDP · jusqu’à 4x meilleur coût/perf. vs H100 sur certains workloads |
| Jean Zay (France) | Supercalculateur national IA du CNRS/IDRIS — 1 456 GPU H100 | 125,9 PFlop/s · formation d’un modèle en 2 semaines (vs 4 mois en 2022) |
| Entraînement GPT-3 | 175 milliards de paramètres | ~1 287 MWh · ~502 t CO₂ |
| Entraînement GPT-4 | Modèle multimodal d’OpenAI (2023) | ~100 M$ · 10 000 – 30 000 MWh estimés |
| Entraînement Gemini 1 | Modèle fondation de Google | ~191 M$ |
| Modèles futurs (2025-2027) | Prochaine génération de LLMs avancés | 1 à 100 milliards $ estimés |
Open source vs propriétaire : quel écosystème pour l’IA ?
Le développement de l’IA repose sur deux grands écosystèmes : l’open source, où codes, poids et architectures sont accessibles à tous, et le propriétaire, où les modèles restent sous contrôle exclusif de leurs créateurs.
Les frameworks : PyTorch vs TensorFlow
TensorFlow (Google) et PyTorch (Meta) sont les deux frameworks open source les plus utilisés. PyTorch se distingue par sa flexibilité et ses graphes dynamiques, idéaux pour la recherche et le prototypage rapide. TensorFlow offre un écosystème mature orienté production avec des outils comme TF Serving et TFX, plus adapté au déploiement à grande échelle.
Modèles ouverts vs modèles propriétaires
Les modèles propriétaires comme GPT ou Gemini offrent les meilleures performances brutes, mais impliquent des coûts d’utilisation et des considérations liées à la confidentialité des données. Les modèles open source — LLaMA de Meta, Mistral — offrent flexibilité, confidentialité et avantages en termes de coûts. Grâce à des techniques d’entraînement améliorées et des architectures optimisées, des modèles comme LLaMA 3 et Mistral sont désormais comparables à GPT-4 dans de nombreuses tâches. Les modèles propriétaires conservent toutefois un avantage sur les tâches multimodales et les longs contextes.












