

SQL est un langage de programmation permettant de manipuler les bases de données. Découvrez tout ce que vous devez savoir à son sujet : fonctionnement, cas d’usage, méthodes d’apprentissage…
SQL ou « Structured Query Language » est un langage de programmation permettant de manipuler les données et les systèmes de bases de données relationnelles. Ce langage permet principalement de communiquer avec les bases de données afin de gérer les données qu’elles contiennent.
Il permet notamment de stocker, de manipuler et de retrouver ces données. Il est aussi possible d’effectuer des requêtes, de mettre à jour les données, de les réorganiser, ou encore de créer et de modifier le schéma et la structure d’un système de base de données et de contrôler l’accès à ses données.
Qu’est-ce que SQL ?
SQL, pour Structured Query Language, est un langage déclaratif standardisé (ANSI/ISO) qui permet de manipuler les données et les systèmes de bases de données relationnelles. Il sert à communiquer avec une base afin de définir la structure des données (tables, schémas), effectuer des requêtes, mettre à jour ou réorganiser les informations, et contrôler les droits d’accès. Les données sont organisées en lignes et en colonnes au sein de tables, et l’on décrit en SQL le résultat attendu, sans préciser pas à pas comment l’obtenir.
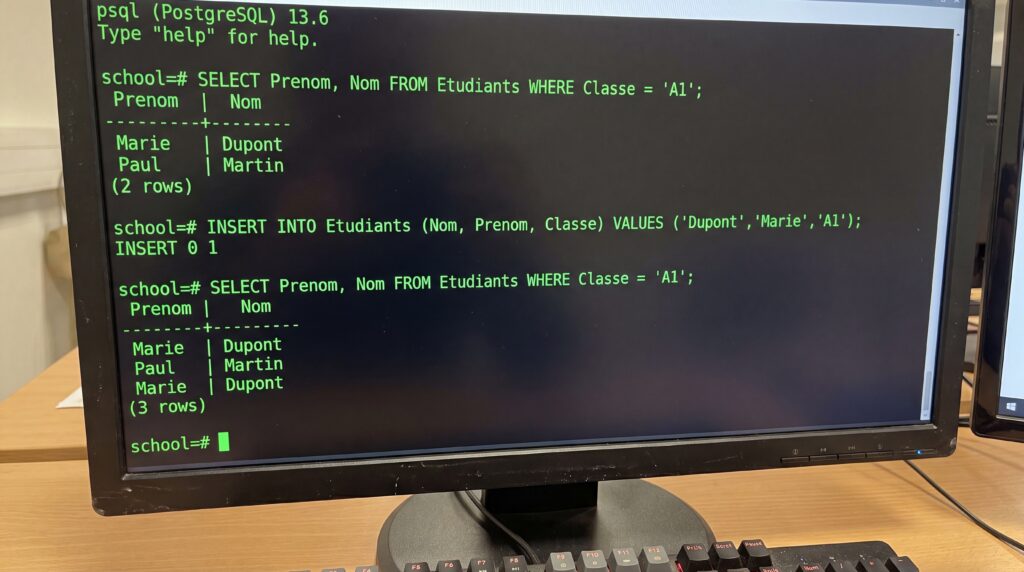
Exemple concret pour débuter : dans une base « École » contenant une table Etudiants (Nom, Prenom, Classe), on peut afficher les élèves de la classe A1 avec SELECT Prenom, Nom FROM Etudiants WHERE Classe = 'A1';, ou ajouter un élève avec INSERT INTO Etudiants (Nom, Prenom, Classe) VALUES ('Dupont','Marie','A1');. Ces requêtes montrent comment SQL permet de retrouver et de modifier des informations de façon simple et lisible.
L’histoire de SQL
À la fin des années 1960, chez IBM, Edgar F. Codd formalise le modèle relationnel (article publié en 1970), qui pose les bases des tableaux reliés par des clés. Au milieu des années 1970, IBM lance System R pour démontrer ce modèle et tester un langage de requêtes de haut niveau.
En 1974, Donald D. Chamberlin et Raymond F. Boyce (IBM) conçoivent SEQUEL (Structured English Query Language), qui deviendra ensuite SQL à la suite d’une simplification du nom. Le langage s’impose rapidement comme moyen standard de dialoguer avec les bases relationnelles.
Les premières implémentations et tests arrivent à la fin des années 1970. Oracle commercialise en 1979 l’un des premiers SGBDR reposant sur SQL. IBM lance SQL/DS en 1981 puis DB2 en 1983. D’autres acteurs majeurs émergent à la même période, comme Ingres, Sybase et, plus tard, Microsoft SQL Server et les systèmes open source MySQL et PostgreSQL.
Voici les jalons clés qui ont façonné SQL, de sa naissance à ses principales évolutions de norme :
- 1970 : publication de l’article fondateur d’Edgar F. Codd sur le modèle relationnel.
- 1974, 1976 : création de SEQUEL chez IBM, renommé ensuite SQL ; expérimentation dans System R.
- 1979 : première offre commerciale largement diffusée avec Oracle.
- 1981, 1983 : sorties d’IBM SQL/DS puis DB2.
- 1986 : normalisation ANSI du langage.
- 1987 : normalisation ISO (début d’un cycle de révisions régulières).
- 1992 : SQL-92 consolide la syntaxe et la portabilité entre SGBDR.
- 1999 : SQL:1999 introduit des apports majeurs (types et fonctions définis par l’utilisateur, déclencheurs, requêtes récursives).
- 2003 : SQL:2003 ajoute les fenêtres analytiques (clause OVER), l’XML et la commande MERGE.
- 2011 : SQL:2011 standardise les données temporelles (time period, versioning).
- 2016 : SQL:2016 intègre le support JSON au standard.
- Aujourd’hui : coexistence de la norme et de dialectes spécifiques (par exemple T-SQL pour Microsoft, PL/SQL pour Oracle, PL/pgSQL pour PostgreSQL), et large adoption sur site comme dans le cloud.
Comment fonctionne SQL ?
SQL, pour Structured Query Language, est un langage déclaratif utilisé pour interagir avec des bases de données relationnelles. Il permet de créer des structures de données, d’insérer ou de mettre à jour des enregistrements et surtout d’exprimer des requêtes pour retrouver rapidement l’information. Dans l’usage, les applications sont écrites en langages comme Python, PHP ou Java, tandis que la base de données comprend SQL, qui sert d’interface commune pour manipuler les données et le schéma.
Modèle relationnel : pourquoi est-il central ?
Le modèle relationnel organise les données en tables liées entre elles. Cette représentation simple, mais rigoureuse, permet d’assurer l’intégrité des informations et de formuler des requêtes puissantes.
- Tables : chaque table modélise un type d’entité (par exemple, Étudiants).
- Lignes : aussi appelées enregistrements, elles représentent des instances de l’entité (un étudiant).
- Colonnes : ou attributs, elles décrivent les propriétés (nom, âge, classe).
- Clé primaire : identifiant unique et non nul d’une ligne, souvent indexé pour accélérer les recherches.
- Clé étrangère : colonne faisant référence à la clé primaire d’une autre table, base des relations et de l’intégrité référentielle.
- Relations : un-à-un, un-à-plusieurs, plusieurs-à-plusieurs (cette dernière via une table d’association).
- Contraintes et types : NOT NULL, UNIQUE, CHECK, ainsi que le typage (INTEGER, VARCHAR, DATE…) qui garantissent la qualité des données.
- Index : structures facultatives accélérant les lectures sur des colonnes recherchées ou jointes fréquemment.
Concrètement, SQL permet de créer et de manipuler ces tables, d’écrire des requêtes comme SELECT pour extraire des données, UPDATE pour les modifier ou DELETE pour les supprimer, comme illustré dans les exemples plus bas de l’article.
Architecture client-serveur : comment circule une requête ?
Dans la plupart des SGBD, une requête suit un “chemin” logique. Les noms de composants varient selon MySQL, PostgreSQL, SQL Server ou Oracle, mais le déroulé reste comparable.
- Envoi depuis le client : l’application ou l’outil SQL transmet la requête au serveur de base de données.
- Analyse par le parseur : vérification de la syntaxe et de la cohérence sémantique, contrôle des droits et transformation interne de la requête.
- Optimisation : l’optimiseur évalue différentes stratégies d’exécution en s’appuyant sur les statistiques et les index disponibles, puis choisit le plan le plus efficace.
- Exécution : l’exécuteur applique le plan choisi. Il orchestre les lectures et écritures, effectue les jointures, applique les filtres et les agrégations.
- Moteur de stockage : gestion de l’accès physique aux données (fichiers, tampons mémoire, journal de transactions) et garantie des propriétés ACID pour la fiabilité des mises à jour.
- Retour des résultats : le serveur renvoie les lignes ou l’accusé de réussite de la commande au client.
Ce pipeline explique pourquoi la qualité du schéma, la présence d’index pertinents et des statistiques à jour influencent directement les performances d’une requête.
Optimiseur et plan d’exécution
L’optimiseur construit un plan d’exécution : une “recette” détaillant comment accéder aux tables, dans quel ordre joindre les données, quels index utiliser et s’il faut lire une table entièrement ou via un parcours indexé. Ce plan est essentiel pour comprendre et améliorer les performances.
Exemple d’interprétation : pour une sélection filtrée sur une colonne indexée, le plan privilégiera souvent un index range scan plutôt qu’une lecture complète de la table. Pour une jointure entre Étudiants et Inscriptions, il pourra choisir une jointure par hachage ou imbriquée selon le volume estimé, la sélectivité des filtres et les index disponibles. Les commandes d’inspection comme EXPLAIN ou EXPLAIN ANALYZE (selon le SGBD) affichent ce plan pour guider l’optimisation.
Les commandes SQL
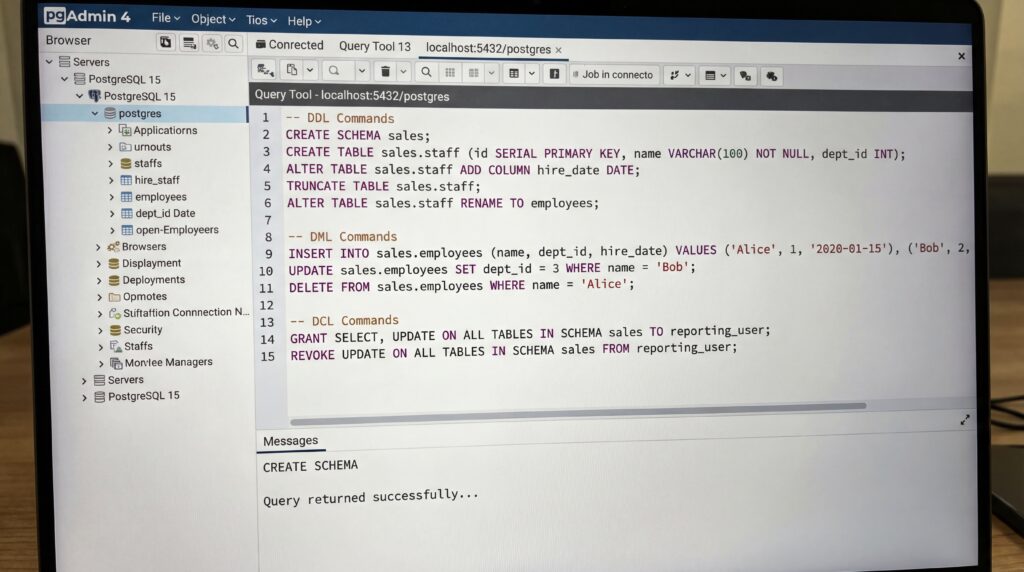
Le langage SQL se structure en cinq familles complémentaires, selon la tâche à accomplir : définir le schéma, manipuler les données, interroger, administrer les droits et contrôler les transactions. Voici la classification complète : Data Definition Language (DDL), Data Manipulation Language (DML), Data Query Language (DQL), Data Control Language (DCL) et Transaction Control Language (TCL).
- DDL : création et modification du schéma (tables, vues, contraintes, index). Principales commandes : CREATE, ALTER, DROP, TRUNCATE, RENAME.
- DML : modification des données. Principales commandes : INSERT, UPDATE, DELETE, et MERGE quand disponible.
- DQL : interrogation des données avec SELECT et ses clauses.
- DCL : gestion des privilèges. Principales commandes : GRANT, REVOKE.
- TCL : contrôle des transactions. Principales commandes : BEGIN/START TRANSACTION, COMMIT, ROLLBACK.
Que permet le DDL (CREATE, ALTER, DROP) ?
Le DDL sert à définir et faire évoluer la structure d’une base : créer ou supprimer des objets (bases, schémas, tables, vues), modifier une table avec ALTER TABLE (colonnes, contraintes), gérer les index (CREATE/DROP INDEX) et vider rapidement une table avec TRUNCATE sans toucher à sa structure.
Exemple : créer une table, l’altérer, indexer une colonne, purger son contenu puis supprimer l’index.
Que permet le DML (INSERT, UPDATE, DELETE, MERGE) ?
Le DML permet d’insérer, de mettre à jour et de supprimer des lignes. Lorsque le SGBD le propose, MERGE facilite les opérations de synchronisation : mise à jour si la ligne existe, insertion sinon.
Exemple : synchroniser une table cible avec des données sources (syntaxe générique, peut varier selon le SGBD).
Que permet le DQL (SELECT) ?
Le DQL regroupe l’interrogation des données avec SELECT. Cette instruction est déclarative : on exprime le résultat attendu en combinant des clauses.
- FROM : tables ou vues ciblées, jointures éventuelles.
- WHERE : filtres sur les lignes.
- GROUP BY : agrégation par groupe.
- HAVING : filtres appliqués après agrégation.
- ORDER BY : tri des résultats.
À quoi sert le DCL (GRANT, REVOKE) ?
Le DCL gère la sécurité au niveau SQL : attribution et retrait de privilèges sur les objets. On peut contrôler précisément qui lit, insère, modifie ou supprime des données.
Exemple : donner puis retirer un droit de lecture sur une table.
À quoi sert le TCL (BEGIN, COMMIT, ROLLBACK) ?
Le TCL encadre les transactions qui garantissent les propriétés ACID (atomicité, cohérence, isolation, durabilité). Il permet de grouper plusieurs opérations en une unité logique et de choisir un niveau d’isolation adapté (par exemple : Read Committed, Repeatable Read, Serializable, selon le SGBD).
- BEGIN ou START TRANSACTION : démarre une transaction.
- COMMIT : valide définitivement les modifications.
- ROLLBACK : annule les modifications non validées.
Quelles sont les contraintes et types de données en SQL ?
Le schéma d’une base relationnelle repose sur deux piliers indissociables : le typage des colonnes et l’intégrité des données. Choisir un type adapté réduit les erreurs et améliore les performances, tandis que les contraintes garantissent la cohérence des lignes et des relations entre tables. Vous trouverez ci-dessous un tour d’horizon pratique, utile dès la conception d’un modèle.
- Typage des colonnes : numérique, texte, date/heure, booléen, JSON, géospatiaux selon les SGBD.
- Valeur spéciale NULL : signification, tests avec IS NULL, fonctions utiles comme COALESCE.
- Contraintes d’intégrité : PRIMARY KEY, FOREIGN KEY, UNIQUE, CHECK, NOT NULL, avec exemples concrets.
Quels types de données utiliser ?
Le SQL standard définit des familles de types, et chaque SGBD ajoute ses spécificités. Visez la sémantique la plus simple possible, puis affinez selon le moteur choisi (PostgreSQL, MySQL, SQL Server, Oracle, SQLite).
| Catégorie | Types courants | Exemples d’usage | Particularités selon SGBD |
|---|---|---|---|
| Numérique | INTEGER, BIGINT, DECIMAL(p,s), NUMERIC, REAL, DOUBLE | Identifiants, montants, mesures | Privilégiez DECIMAL/NUMERIC pour les montants. Les tailles d’entiers peuvent varier selon le moteur. |
| Texte | CHAR(n), VARCHAR(n), TEXT | Noms, descriptions | La gestion des collations et de la casse dépend du SGBD. TEXT non limité en longueur selon moteur. |
| Date/heure | DATE, TIME, TIMESTAMP, TIMESTAMP WITH TIME ZONE | Dates d’inscription, événements | Vérifiez le support du fuseau (TIMESTAMP WITH TIME ZONE) et les fonctions de manipulation. |
| Booléen | BOOLEAN | Indicateurs vrai/faux | PostgreSQL a BOOLEAN natif; MySQL mappe souvent BOOLEAN vers TINYINT(1); SQL Server utilise BIT. |
| JSON | JSON, JSONB | Données semi-structurées | PostgreSQL: JSON/JSONB natifs; MySQL: JSON natif; SQL Server: stockage texte + fonctions JSON; SQLite: texte + fonctions. |
| Géospatiaux | GEOMETRY, GEOGRAPHY | Points, polylignes, polygones | PostgreSQL via PostGIS, MySQL Spatial natif, SQL Server geometry/geography, SQLite via SpatiaLite. |
Astuce conception : définissez les types et contraintes avec le DDL lors des CREATE/ALTER TABLE. Un typage précis simplifie ensuite vos requêtes DML.
NULL : que signifie-t-il ?
NULL ne signifie ni 0 ni chaîne vide, il signifie « valeur inconnue ou absente ». Le SQL applique une logique à trois valeurs (vrai, faux, inconnu) : une comparaison avec NULL ne renvoie pas vrai, elle renvoie inconnu. Il faut donc tester NULL explicitement.
Tests et fonctions utiles :
- IS NULL / IS NOT NULL pour filtrer les valeurs manquantes.
- COALESCE(expr1, expr2, …) renvoie la première expression non NULL, pratique pour fournir une valeur de repli.
- COUNT(colonne) ignore les NULL, alors que COUNT(*) compte toutes les lignes.
Exemples sur la table Etudiants créée plus haut :
Bonnes pratiques : évitez de stocker des NULL « facilités » quand une contrainte métier impose la présence d’une information, préférez NOT NULL avec une valeur par défaut ou une table dédiée si la donnée est optionnelle.
Quelles contraintes pour assurer l’intégrité ?
Les contraintes inscrivent les règles métier dans la base. Elles protègent vos données contre les doublons, les références orphelines et les valeurs invalides.
- PRIMARY KEY : identifie de manière unique chaque ligne d’une table. Elle est implicite NOT NULL et UNIQUE.
- FOREIGN KEY : garantit l’intégrité référentielle en imposant que la valeur existe dans la table référencée.
- UNIQUE : empêche les doublons sur une ou plusieurs colonnes. Selon les moteurs, les lignes NULL peuvent être autorisées.
- CHECK : impose une condition logique sur une colonne ou un groupe de colonnes.
- NOT NULL : interdit la valeur NULL.
Exemple complet, en reprenant la base Ecole et la table Etudiants, et en ajoutant une table Classes pour illustrer l’intégrité référentielle :
Explications :
- PRIMARY KEY sur Classes.Code : chaque classe possède un identifiant unique.
- CHECK sur Niveau et Age : contrôle de validité sur des bornes plausibles.
- UNIQUE sur (Nom, Prenom) pour éviter les doublons parfaits dans l’exemple simple (en pratique, ajoutez une date de naissance ou un identifiant national).
- FOREIGN KEY Etudiants.Classe vers Classes.Code : empêche d’affecter une classe inexistante, bloque la suppression d’une classe encore utilisée, et répercute une mise à jour du code.
Pour créer ces objets et leurs contraintes, on utilise les commandes CREATE/ALTER TABLE du DDL. Les contrôles s’appliquent ensuite automatiquement à chaque INSERT/UPDATE DML, ce qui fiabilise la base indépendamment des applications clientes.
Comment écrire une requête SELECT efficace ?

La commande SELECT permet de trouver ou d’extraire des données depuis une base relationnelle. Pour des requêtes lisibles et rapides, structurez-les dans l’ordre logique suivant : SELECT (colonnes et alias), FROM (tables et jointures), WHERE (filtrage ligne à ligne), GROUP BY/HAVING (agrégation et filtrage sur agrégats), ORDER BY (tri), puis pagination (LIMIT/OFFSET ou OFFSET … FETCH). Bonnes pratiques : sélectionnez des colonnes explicites plutôt que SELECT *, filtrez tôt avec WHERE, évitez d’appliquer des fonctions sur les colonnes filtrées si un index existe, et limitez le volume retourné.
Comment filtrer avec WHERE ?
- Opérateurs de comparaison :
=,<>,<,>,<=,>=,IS NULL,IS NOT NULL. - Combinaisons logiques :
NOT,AND,OR. Priorité par défaut :NOT>AND>OR. Utilisez des parenthèses pour lever toute ambiguïté. - Tranches de valeurs :
BETWEEN a AND b(bornes inclusives). - Listes :
IN (...)et son inverseNOT IN (...). - Recherche de motif :
LIKEavec%(plusieurs caractères) et_(un caractère).
Exemples sur la table Etudiants (créée plus haut) :
Astuce performance : lorsqu’un index existe sur une colonne, évitez d’englober cette colonne dans une fonction côté gauche de la condition (WHERE UPPER(Nom) = 'DUPONT') car cela peut empêcher l’index d’être utilisé. Préférez des colonnes « brutes » et, si besoin, des colonnes dérivées indexées.
Comment trier et paginer ?
ORDER BY trie le résultat sur une ou plusieurs colonnes, avec ASC ou DESC. La pagination dépend du SGBD :
Conséquences sur les performances : trier sur une colonne non indexée coûte cher, surtout avec un OFFSET élevé. Pour de très grandes tables, préférez une pagination dite « keyset » qui s’appuie sur une clé triée plutôt que sur un simple OFFSET.
Comment agréger des données (GROUP BY, HAVING) ?
Les fonctions d’agrégation les plus courantes sont COUNT(), SUM(), AVG(), MIN(), MAX(). GROUP BY regroupe les lignes par valeur commune, HAVING filtre après agrégation. Rappelez-vous : toute colonne sélectionnée qui n’est pas agrégée doit figurer dans le GROUP BY.
Bon réflexe : mettez dans WHERE tous les filtres qui ne dépendent pas d’une agrégation, réservez HAVING aux conditions portant sur des résultats agrégés.
Quand utiliser DISTINCT ?
DISTINCT déduplique les lignes du jeu de résultats projeté. Utilisez-le pour obtenir des valeurs uniques sur la ou les colonnes sélectionnées, en gardant à l’esprit qu’il s’applique à la combinaison complète des colonnes du SELECT. Il a un coût, surtout sur de gros volumes.
Évitez les abus : si des doublons proviennent d’une jointure, corrigez la jointure ou utilisez EXISTS plutôt qu’un DISTINCT systématique. Lorsque vous agrègez déjà, GROUP BY remplace souvent utilement DISTINCT selon le besoin.
Qu’est-ce qu’une jointure SQL et quand l’utiliser ?
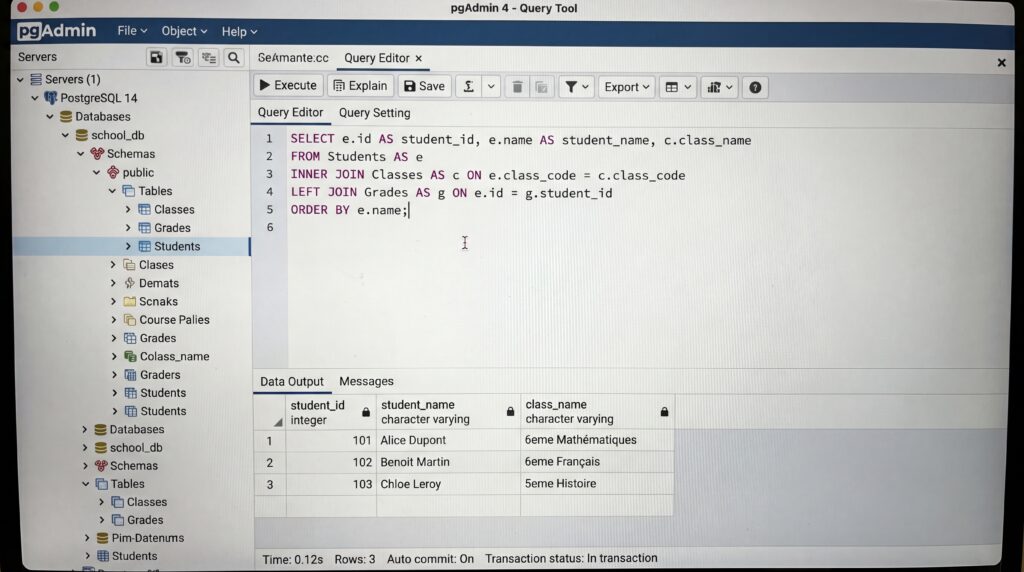
Une jointure SQL combine des lignes de plusieurs tables selon une relation logique, le plus souvent une clé primaire liée à une clé étrangère. On l’utilise dès que l’information recherchée est répartie dans des tables différentes, par exemple pour afficher des étudiants avec le libellé de leur classe. Dans les commandes SQL de base, JOIN sert à relier des tables afin d’interroger ou de récupérer des données de façon cohérente.
Exemple de schéma simple dans la continuité de l’exemple “École” :
Question fréquente : “afficher chaque étudiant avec l’intitulé de sa classe”. Réponse : effectuer une jointure entre Etudiants et Classes sur le code de classe.
Quelle différence entre INNER et OUTER JOIN ?
INNER JOIN ne renvoie que les lignes qui correspondent des deux côtés (intersection). OUTER JOIN conserve aussi les lignes sans correspondance d’un côté (LEFT ou RIGHT) ou des deux côtés (FULL), les colonnes manquantes étant nulles. L’INNER est idéal pour “n’afficher que ce qui matche”, les OUTER servent à auditer les manques ou à produire des listes complètes enrichies quand l’information liée est optionnelle.
Comparaison rapide sur nos tables “École”.
Bonnes pratiques : privilégier LEFT JOIN pour exprimer “tout à gauche, enrichi si possible”, plus lisible qu’un RIGHT JOIN dans la plupart des requêtes. Le FULL OUTER JOIN est utile pour dresser des états de complétude. Selon les SGBD, sa disponibilité varie, d’où des alternatives possibles avec UNION de jointures gauche et droite.
CROSS et NATURAL JOIN : dans quels cas ?
CROSS JOIN produit le produit cartésien : chaque ligne de la table A combinée à chaque ligne de la table B. C’est rare en production car le volume explose, mais utile pour générer des grilles de référence (par exemple combiner une table “Jours” et une table “Créneaux” pour planifier des cours). À manier avec précaution, surtout sans clause WHERE.
NATURAL JOIN relie automatiquement deux tables en utilisant toutes les colonnes de même nom. Cela semble pratique, mais c’est risqué : une nouvelle colonne homonyme ajoutée plus tard changera silencieusement le résultat. Préférez des jointures explicites (ON ou USING) pour garder la maîtrise.
ON vs USING : que choisir ?
USING est concis et lisible quand la ou les colonnes de jointure portent exactement le même nom dans les deux tables. Le moteur fusionne alors cette colonne dans le résultat (une seule occurrence). ON est plus général : il accepte des noms différents, des conditions multiples, des expressions et des non-équijointures. Côté portabilité, ON est supporté partout, y compris SQL Server, tandis que USING n’est pas reconnu par SQL Server (disponible notamment sur PostgreSQL, MySQL, Oracle).
Exemples :
En pratique : adoptez USING pour les jointures d’égalité simples à noms identiques (gain de clarté), et conservez ON dès que la condition s’écarte de ce cas, ou quand vous ciblez une compatibilité maximale entre SGBD.
Quelles opérations d’ensemble existent en SQL ?
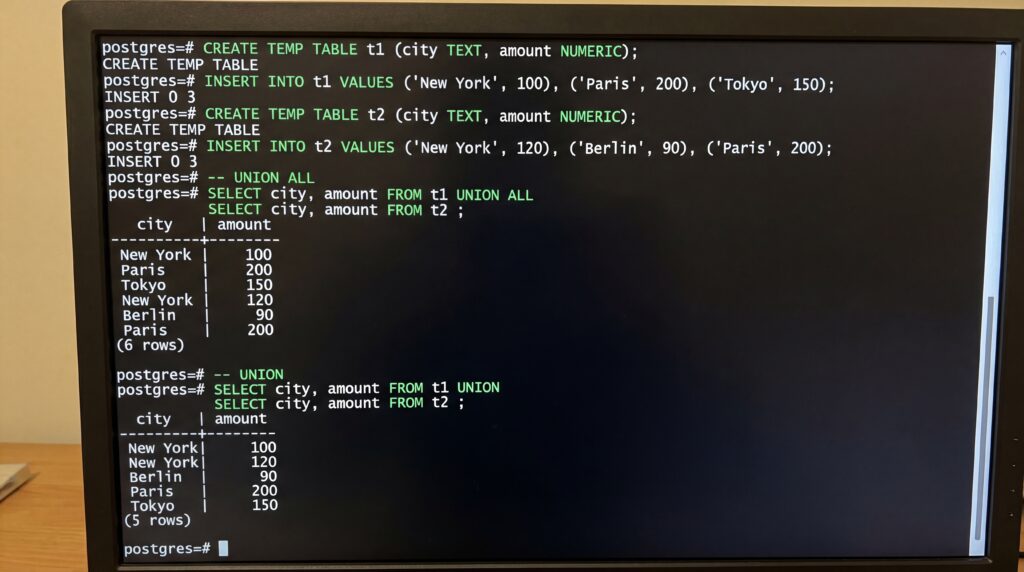
Pour combiner les résultats de plusieurs requêtes SELECT ayant la même structure, SQL propose des opérations d’ensemble. Les requêtes doivent retourner le même nombre de colonnes, dans le même ordre, avec des types compatibles, et les noms de colonnes du résultat final proviennent en général de la première requête. Par défaut, les doublons sont supprimés, mais l’option ALL permet de les conserver. L’ordre d’évaluation peut nécessiter des parenthèses, en particulier lorsque plusieurs opérateurs sont enchaînés. ([postgresql.org](https://www.postgresql.org/docs/15/queries-union.html))
- UNION et UNION ALL : fusionnent deux ensembles de lignes. UNION élimine les doublons, UNION ALL les conserve. ([postgresql.org](https://www.postgresql.org/docs/15/queries-union.html))
- INTERSECT : renvoie uniquement les lignes communes aux deux résultats. Par défaut, les doublons sont supprimés, INTERSECT ALL les conserve. ([postgresql.org](https://www.postgresql.org/docs/15/queries-union.html))
- EXCEPT ou MINUS : renvoie les lignes du premier résultat qui n’apparaissent pas dans le second. Oracle accepte MINUS et EXCEPT, EXCEPT étant synonyme de MINUS selon la documentation récente. ([docs.oracle.com](https://docs.oracle.com/en/database/oracle/oracle-database/23/sqlrf/The-UNION-ALL-INTERSECT-MINUS-Operators.html))
UNION ou UNION ALL ?
UNION supprime les doublons comme le ferait DISTINCT, ce qui implique un travail supplémentaire du moteur (tri ou hachage) pour identifier les lignes uniques. UNION ALL concatène simplement les résultats sans déduplication. Lorsque vous n’avez pas besoin d’unicité, UNION ALL est plus performant et préserve la multiplicité utile à certaines analyses (par exemple, additionner des volumes issus de deux périodes), tandis que UNION garantit un ensemble distinct lorsque l’unicité logique est requise. ([postgresql.org](https://www.postgresql.org/docs/15/queries-union.html))
Conséquences pratiques : utilisez UNION ALL par défaut si vous contrôlez déjà l’unicité en amont ou si les doublons ont du sens métier. Basculez sur UNION quand l’unicité est nécessaire pour la justesse fonctionnelle du résultat. ([postgresql.org](https://www.postgresql.org/docs/15/queries-union.html))
INTERSECT et EXCEPT/MINUS
Sémantique : INTERSECT retourne l’intersection de deux jeux de résultats, EXCEPT la différence directionnelle entre le premier et le second, et MINUS est l’équivalent historique d’EXCEPT dans Oracle. Dans de nombreux systèmes, INTERSECT a une précédence plus forte que UNION et EXCEPT, d’où l’intérêt d’utiliser des parenthèses pour lever toute ambiguïté. ([postgresql.org](https://www.postgresql.org/docs/15/queries-union.html))
- PostgreSQL : prend en charge UNION/INTERSECT/EXCEPT et leurs variantes ALL, avec la précédence propre à INTERSECT documentée. ([postgresql.org](https://www.postgresql.org/docs/15/queries-union.html))
- SQL Server : prend en charge INTERSECT et EXCEPT, avec les mêmes règles de compatibilité de colonnes et de types. ([learn.microsoft.com](https://learn.microsoft.com/en-us/sql/t-sql/language-elements/set-operators-except-and-intersect-transact-sql?view=sql-server-ver17))
- SQLite : prend en charge UNION, INTERSECT et EXCEPT dans les SELECT composés. ([sqlite.org](https://www.sqlite.org/datatype3.html))
- Oracle Database : historiquement MINUS et INTERSECT, et EXCEPT est aujourd’hui un synonyme officiel de MINUS dans la documentation récente. ([docs.oracle.com](https://docs.oracle.com/en/database/oracle/oracle-database/23/sqlrf/The-UNION-ALL-INTERSECT-MINUS-Operators.html))
- MySQL : UNION depuis longtemps, et support d’INTERSECT et d’EXCEPT ajouté à partir de MySQL 8.0.31, avec la même précédence où INTERSECT est évalué avant UNION ou EXCEPT. ([dev.mysql.com](https://dev.mysql.com/doc/refman/8.0/en/set-operations.html?ff=nopfpls))
Comment formuler des requêtes SQL avancées ?

Pour traiter des cas complexes, combinez trois leviers complémentaires : les sous-requêtes (notamment corrélées) pour exprimer des conditions dépendant de chaque ligne, les CTE (WITH) pour clarifier et factoriser les étapes, et les fonctions de fenêtre (OVER, PARTITION BY) pour calculer classements, cumuls et fenêtres mobiles sans regrouper ni perdre le détail.
- Restez déclaratif : découpez la logique en étapes lisibles, testables.
- Privilégiez les CTE pour réutiliser un même sous-résultat plutôt que dupliquer une sous-requête.
- Utilisez EXISTS pour tester l’existence, évitez SELECT * et filtrez tôt dans la requête.
- Préférez les fonctions de fenêtre pour comparer une ligne à son groupe (moyenne par classe, rang, cumul) sans sous-requêtes coûteuses.
- Mesurez avant d’optimiser : expliquez vos plans d’exécution (EXPLAIN) et adaptez index et jointures.
Sous-requêtes corrélées : quand s’en servir ?
Cas concret (reprise de l’exemple École/Etudiants) : afficher les étudiants dont l’âge est supérieur à la moyenne de leur classe. La sous-requête fait référence à la ligne courante e, ce qui la rend corrélée.
Comparaison et alternatives plus performantes : selon le SGBD et le volume, une sous-requête corrélée peut être recalculée pour chaque ligne. Deux alternatives courantes : 1) calculer la moyenne une fois par groupe avec une fonction de fenêtre, puis filtrer ; 2) la factoriser dans une CTE et joindre.
CTE (WITH) : pourquoi les préférer ?
Les CTE améliorent la lisibilité, évitent la duplication d’une même sous-requête et servent de point d’ancrage aux analyses en plusieurs étapes. Elles peuvent être récursives pour naviguer dans une hiérarchie. En pratique, elles facilitent la revue de code et l’optimisation étape par étape.
Exemple récursif : parcourir une arborescence de groupes scolaires ou de matières à prérequis. La CTE se rappelle elle‑même pour déplier la hiérarchie.
Astuce : enchaînez plusieurs CTE nommées pour séparer extraction, nettoyage, agrégation et mise en forme finale. Selon le SGBD, certaines CTE sont matérialisées ou réécrites par l’optimiseur, d’où l’intérêt de vérifier le plan d’exécution.
Fonctions de fenêtre (OVER, PARTITION BY) : pour quoi faire ?
Les fonctions de fenêtre calculent des valeurs « par groupe et par ordre » sans regrouper les lignes. Idéal pour des classements, des cumuls progressifs et des moyennes glissantes.
Bonnes pratiques : définissez toujours ORDER BY dans OVER pour des calculs temporels, contrôlez la fenêtre (ROWS vs RANGE), et combinez les fenêtres à des filtres finaux plutôt que des GROUP BY lorsque vous devez conserver le détail ligne à ligne.
Comment fonctionnent les transactions en SQL ?
En SQL, une transaction regroupe plusieurs instructions en une seule unité de travail qui réussit ou échoue dans son ensemble. Elle s’appuie sur le TCL (Transaction Control Language) qui fournit les commandes pour démarrer, valider ou annuler ces modifications. Les transactions sont essentielles pour garantir l’intégrité des données quand plusieurs utilisateurs accèdent simultanément à la base.
Qu’est-ce que l’ACID et les niveaux d’isolation ?
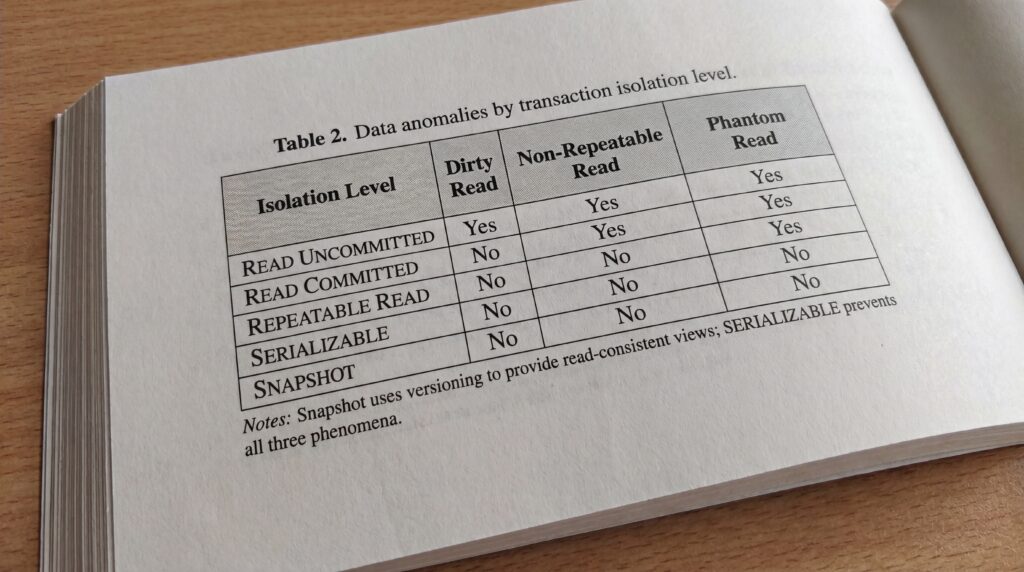
Une transaction fiable respecte les propriétés ACID : Atomicité (tout ou rien), Cohérence (les contraintes restent vraies), Isolation (les transactions concurrentes ne se perturbent pas), Durabilité (les effets validés survivent aux pannes). L’isolation se règle par des niveaux qui contrôlent les phénomènes indésirables suivants : dirty read (lecture de données non validées), non-repeatable read (une même ligne lue deux fois renvoie des valeurs différentes), phantom read (de nouvelles lignes apparaissent lors d’une seconde lecture d’un ensemble).
| Niveau d’isolation | Dirty reads | Lectures non répétables | Lectures fantômes | Usage typique |
|---|---|---|---|---|
| READ COMMITTED | Non | Possible | Possible | Bon compromis pour la plupart des lectures et écritures courantes. |
| REPEATABLE READ | Non | Non | Possible | Utile pour des lectures cohérentes sur les mêmes lignes pendant toute la transaction. |
| SERIALIZABLE | Non | Non | Non | Isolation maximale, équivalente à une exécution séquentielle. Plus coûteuse en concurrence. |
Remarque : certains SGBD proposent une isolation « snapshot » qui offre des lectures cohérentes sans verrouiller les lignes lues, ce qui réduit les blocages au prix d’une gestion de versions.
BEGIN/COMMIT/ROLLBACK : quand les utiliser ?
- Commencez une transaction (
BEGINouSTART TRANSACTION) pour regrouper des opérations atomiques qui doivent toutes réussir ensemble (par exemple, débiter puis créditer). - Gardez vos transactions courtes : préparez les données et les vérifications en amont, puis exécutez les écritures le plus vite possible.
- Choisissez le niveau d’isolation minimal garantissant la justesse fonctionnelle afin de limiter la contention.
- Validez avec
COMMITdès que possible pour libérer les verrous et versions. - En cas d’erreur, annulez avec
ROLLBACK. Utilisez desSAVEPOINTpour revenir partiellement en arrière dans des scénarios complexes. - Évitez les entrées utilisateur ou appels distants au milieu d’une transaction pour ne pas la faire durer inutilement.
- Consignez et surveillez les échecs de validation, puis réessayez quand c’est pertinent côté application.
Exemple simplifié d’un virement entre deux comptes :
En cas d’anomalie détectée après la première mise à jour, un ROLLBACK annule entièrement la transaction, ce qui évite les états incohérents.
Verrous et concurrence : que surveiller ?
Les SGBD coordonnent les accès concurrents via des verrous ou des mécanismes multiversions. Une mauvaise utilisation des transactions peut entraîner des blocages, des contentions ou des délais d’attente.
- Bloquages et contentions : de longues transactions retiennent des verrous qui ralentissent les autres. Astuce : validez tôt, indexez les colonnes filtrées, lisez et écrivez dans un ordre déterministe.
- Deadlocks (verrous morts) : deux transactions se bloquent mutuellement. Astuce : accédez aux ressources toujours dans le même ordre, réduisez la taille des lots, implémentez une stratégie de réessai côté application.
- Timeouts : une opération attend trop longtemps un verrou. Astuce : définissez des délais raisonnables, journalisez les requêtes bloquantes, ajustez l’isolation si une cohérence plus souple suffit.
- Escalade de verrous : le SGBD peut regrouper des verrous fins en verrous plus larges. Astuce : traitez par petits lots, utilisez des indexes sélectifs pour limiter le nombre de lignes touchées.
- Lectures concurrentes : privilégiez des stratégies qui réduisent la contention (par exemple, lectures cohérentes par version quand le SGBD le permet) pour les rapports et analyses.
Comment optimiser ses requêtes SQL ?

Gagner en performance repose sur trois piliers complémentaires : une indexation adaptée au modèle de données, une écriture de requêtes « sargable » (recherches exploitables par les index), et la lecture des plans d’exécution avec EXPLAIN/ANALYZE pour mesurer l’impact réel des changements. Avant toute modification, mesurez, optimisez, puis remesurez.
- Mesurer systématiquement avec EXPLAIN puis EXPLAIN ANALYZE pour comparer estimation et temps réel.
- Indexer les colonnes utilisées dans WHERE, JOIN, ORDER BY et GROUP BY, en tenant compte de leur sélectivité (plus elles filtrent, plus l’index est utile).
- Réécrire les prédicats pour qu’ils restent sargables : colonne opérateur valeur, éviter les fonctions sur les colonnes filtrées et les jokers en tête de motif.
- Réduire les données manipulées : sélectionner uniquement les colonnes nécessaires, paginer, filtrer tôt, préférer des agrégations ciblées.
- Veiller à la cohérence des types et des collations entre colonnes jointes ou comparées.
- Actualiser les statistiques de la base pour aider l’optimiseur.
Quels index créer et quand ?
La plupart des SGBD utilisent par défaut des index B-tree, polyvalents pour l’égalité, les intervalles et le tri. Les index hash sont efficaces pour les égalités pures, tandis que les index bitmap excellent sur des colonnes à faible cardinalité dans des charges analytiques. Choisissez les colonnes à indexer selon leur sélectivité et leur rôle dans les filtres, jointures et tris. Sur plusieurs colonnes, l’ordre dans un index composé suit la règle du leftmost prefix (le préfixe le plus à gauche conditionne l’exploitation de l’index).
| Type d’index | Cas d’usage recommandé | Atouts | Limites / À éviter |
|---|---|---|---|
| B-tree (simple) | Égalité et intervalles, tris, colonnes très sélectives (id, email, date d’événement, clés étrangères) | Polyvalent, utilisé par défaut, exploitable pour ORDER BY et BETWEEN | Peu utile si la colonne a très peu de valeurs distinctes et des requêtes peu filtrantes |
| B-tree composé | Filtres et tris fréquents sur plusieurs colonnes, jointures multi-colonnes | Peut « couvrir » une requête si les colonnes projetées sont incluses | Respecter le préfixe, sur-indexer pénalise les écritures et l’espace |
| Hash | Comparaisons d’égalité pures sur une colonne (par exemple clé de recherche exacte) | Accès très rapide pour l’égalité | Pas d’ordres ni d’intervalles, utilité limitée si les requêtes trient ou font des plages |
| Bitmap | Colonnes à faible cardinalité en analytique (entrepôts de données), combinaisons de filtres | Très efficace pour combiner des prédicats multiples | Coût d’écriture élevé, généralement déconseillé en OLTP |
| Index partiel / filtré | Filtrer une portion « chaude » des données (par exemple lignes actives) | Moins d’espace, meilleures performances ciblées | Nécessite des prédicats stables et bien choisis |
Bonnes pratiques : indexer les clés étrangères, placer en tête des index composés la colonne la plus sélective et la plus souvent utilisée en filtre, éviter de multiplier les index redondants, et préférer un index qui couvre la requête lorsque c’est pertinent.
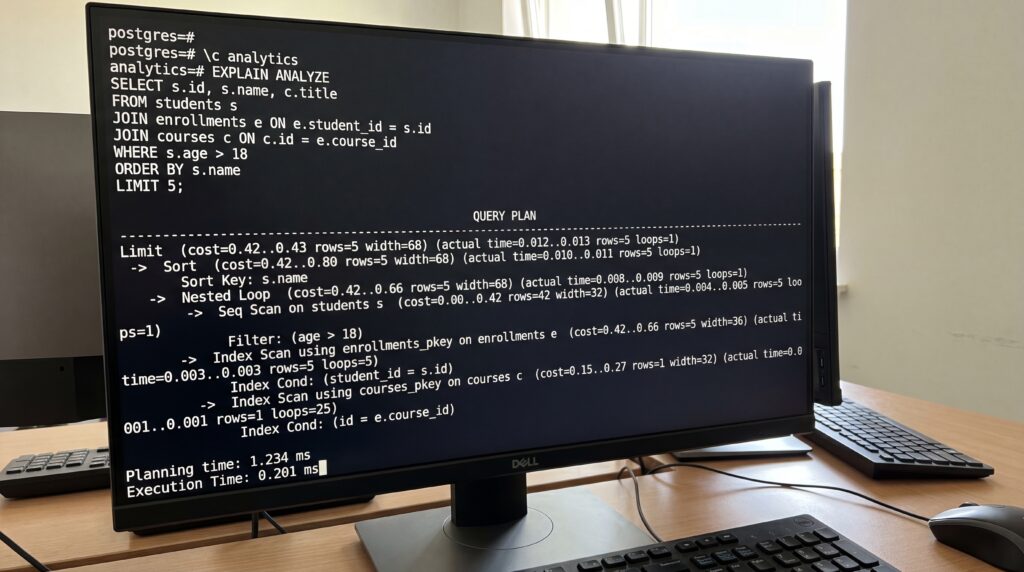
EXPLAIN/ANALYZE : comment lire un plan d’exécution ?
EXPLAIN affiche le plan estimé choisi par l’optimiseur : coût estimé, lignes attendues, chemins d’accès. EXPLAIN ANALYZE exécute réellement la requête et ajoute le temps par nœud, les lignes réellement lues, ainsi que d’éventuelles réexécutions. Comparez toujours estimations et réalité : un écart important signale souvent des statistiques obsolètes, un mauvais choix de jointure, ou un prédicat non sargable.
Principaux nœuds et chemins d’accès à reconnaître :
- Seq Scan (lecture séquentielle de table) : volumineux et coûteux si la requête est très filtrante.
- Index Scan / Index Seek : utilisation d’un index pour filtrer, bien pour égalités et plages.
- Bitmap Index Scan / Bitmap Heap Scan : utile quand plusieurs prédicats combinés réduisent fortement le jeu de résultats.
- Nested Loop : performant si la table externe retourne peu de lignes et que la table interne est bien indexée.
- Hash Join : efficace sur grands volumes pour égalités, attention à la mémoire de hachage.
- Merge Join : très bon si les deux entrées sont déjà triées sur la clé de jointure.
Exemple de lecture : une requête qui filtre sur Nom et Prenom bénéficiera d’un index composé (Nom, Prenom) qui produira un Index Seek. Si le plan montre un Seq Scan avec beaucoup de lignes lues et un tri explicite pour ORDER BY Age DESC, créez un index B-tree adapté (par exemple (Nom, Prenom, Age) si le tri et le filtre coexistent souvent) ou séparez les usages selon les requêtes dominantes.
Anti-patterns fréquents à éviter
- SELECT * dans les parcours applicatifs : plus d’I/O et de réseau, empêche d’exploiter des index couvrants et fragilise le contrat de schéma.
- Fonctions sur colonnes indexées (
LOWER(email),DATE(created_at)) dans les filtres : l’index ne peut plus servir. Préférer un prédicat équivalent sargable (plage de dates, normalisation en écriture, colonne calculée indexée). - OR multiples et LIKE ‘%motif’ non sargables : remplacés au besoin par
UNION ALLde requêtes sargables, index adaptés, ou moteur de recherche plein texte pour les motifs complexes. - N+1 requêtes depuis l’application : multitude d’allers-retours base, remplacer par une jointure unique ou un
IN/EXISTSbien indexé, voire une agrégation côté SGBD.
Conséquences typiques : scans complets, contention I/O, surcharge CPU pour les tris et hachages, plans instables et latences en cascade côté application. Une fois les anti-patterns supprimés, validez toujours avec EXPLAIN/ANALYZE.
À quoi servent vues, procédures et triggers ?

Au-delà des requêtes DDL, DML et DCL déjà vues, les SGBD proposent trois mécanismes pour structurer la logique et rapprocher la « logique métier » des données : les vues (et vues matérialisées), les fonctions et procédures stockées, et les triggers (déclencheurs). Bien utilisés, ils simplifient les requêtes, renforcent la sécurité et fiabilisent les traitements transactionnels.
Quand créer une vue (ou vue matérialisée) ?
Une vue est une table virtuelle définie par une requête SELECT. Elle sert à simplifier l’accès à des jointures ou agrégations répétitives et à limiter l’exposition des colonnes/lignes sensibles. Couplée aux droits d’accès (GRANT / REVOKE), elle devient un excellent outil de sécurisation sans dupliquer les données.
- Simplifier des requêtes complexes : encapsuler une jointure entre Etudiants, Inscriptions et Cours dans
vue_suivi_etudiantspour éviter de réécrire la même requête. - Stabiliser un contrat d’accès : offrir une « API SQL » stable aux analystes, même si le schéma physique évolue.
- Renforcer la sécurité : n’exposer que les colonnes nécessaires, filtrer par service ou périmètre géographique, puis attribuer les droits au niveau de la vue.
Une vue matérialisée stocke physiquement le résultat pour accélérer des lectures coûteuses (agrégations quotidiennes, tableaux de bord). Elle convient lorsque la fraîcheur peut être maîtrisée via un rafraîchissement planifié ou incrémental. En contrepartie, elle introduit un coût de maintenance et un risque d’obsolescence si le rafraîchissement est trop espacé.
En pratique : utilisez une vue logique pour la simplicité et la sécurité applicative, et une vue matérialisée pour la performance analytique lorsque le temps de réponse est critique et que des mises à jour périodiques sont acceptables.
Fonctions et procédures stockées : quels usages ?
Les fonctions et procédures stockées encapsulent des traitements côté base, au plus près des données, avec atomicité et contrôle transactionnel. Selon le SGBD, elles sont écrites dans un dialecte dédié (par exemple PL/pgSQL, PL/SQL, T‑SQL).
- Encapsuler des règles métier : calculer un prix, appliquer des remises, générer un identifiant métier.
- Valider des entrées : contrôler formats, référentiels et contraintes avancées avant
INSERT/UPDATE. - Automatiser des lots : import journalier, clôture mensuelle, réconciliation entre tables.
- Garantir la cohérence : exécuter plusieurs opérations dans une même transaction pour réussir ou échouer ensemble.
Exemple métier : une procédure valider_commande vérifie le stock, réserve les quantités, enregistre le paiement et écrit une ligne d’audit. Si l’une des étapes échoue, la transaction est annulée, évitant les états partiels.
Bonnes pratiques : isoler une logique claire et réutilisable, journaliser les erreurs, documenter les paramètres et effets de bord, et mesurer les impacts de performance lors de charges importantes.
Triggers : cas d’usage et précautions
Un trigger se déclenche automatiquement avant ou après un INSERT, UPDATE ou DELETE. Il sert à appliquer des règles transverses sans dépendre de l’application cliente.
- Audit et traçabilité : historiser les changements dans une table audit_log avec l’utilisateur, l’horodatage et l’ancienne/nouvelle valeur.
- Dérivations automatiques : maintenir un total dénormalisé, calculer un champ dérivé, remplir une date de mise à jour.
- Contraintes avancées : interdire des modifications dans certaines fenêtres temporelles, implémenter des règles que les contraintes déclaratives ne couvrent pas.
Précautions : les triggers peuvent complexifier le système et créer des effets de bord difficiles à diagnostiquer. Évitez les chaînes de triggers, limitez le code exécuté, documentez le comportement, et surveillez l’impact sur les opérations en masse. Lorsque c’est possible, préférez une contrainte native, une colonne générée ou une procédure explicite plus lisible.
Cas concret : un trigger AFTER UPDATE sur Etudiants écrit automatiquement dans historique_classe lorsque la colonne Classe change. Bénéfice, l’historique est maintenu quel que soit le client SQL. Risque, une mise à jour massive peut subir un surcoût non anticipé si le trigger réalise des requêtes additionnelles par ligne.
Qu’est-ce que l’injection SQL et comment s’en protéger ?

L’injection SQL est une technique d’attaque qui consiste à insérer des fragments de code SQL malveillant dans des champs de saisie ou des paramètres d’URL afin de manipuler une requête. Résultat possible : lecture d’informations sensibles, modification ou suppression de données, contournement d’authentification. Ce risque apparaît surtout lorsque les requêtes sont construites par concaténation de chaînes sans contrôle ni paramétrage.
Volet sécurité indispensable : adoptez une défense en profondeur. Combinez des requêtes paramétrées, une gestion stricte des privilèges, des contrôles d’entrée, une journalisation exploitable et un stockage sécurisé des secrets.
- Utiliser des requêtes préparées avec paramètres obligatoires, éviter toute concaténation dynamique.
- Valider les entrées côté serveur avec des listes blanches, refuser ce qui ne correspond pas au format attendu.
- Échapper les valeurs uniquement en ultime recours, préférer les placeholders fournis par le pilote ou l’ORM.
- Appliquer le principe du moindre privilège avec GRANT et REVOKE pour limiter l’impact d’une compromission.
- Activer la journalisation des requêtes anormales et des erreurs, sans divulguer de détails techniques à l’utilisateur.
- Gérer les secrets de connexion via un coffre-fort de secrets, activer TLS pour les connexions à la base.
- Maintenir SGBD, pilotes et ORM à jour, tester régulièrement avec des outils d’analyse et des tests de sécurité.
Requêtes paramétrées et ORM : quelles bonnes pratiques ?
Préparez systématiquement vos requêtes et passez les valeurs en paramètres. Évitez les chaînes interpolées et la construction dynamique d’objets SQL. Dans un ORM, utilisez les méthodes de filtrage officielles plutôt que du SQL brut. Les placeholders diffèrent selon les pilotes (par exemple ?, %s, :nom), mais l’idée reste la même : la requête est compilée une fois, puis les valeurs sont liées sans jamais être interprétées comme du code.
Exemples :
Avec un ORM, préférez les filtres typés. Exemple conceptuel : Etudiant.objects.filter(nom=nom_saisi, age__gt=18). L’ORM génère des requêtes paramétrées et se charge d’échapper correctement les valeurs.
Comment gérer les privilèges (GRANT/REVOKE) ?
- Principe du moindre privilège : un compte applicatif ne doit disposer que des droits nécessaires (souvent
SELECT, parfoisINSERT/UPDATEsur des tables ciblées). - Rôles : regroupez les permissions dans des rôles lisibles, puis assignez ces rôles aux comptes. Cela simplifie l’audit et la révocation.
- Séparation des responsabilités : distinguer les comptes d’administration, d’exploitation et d’application. Un compte applicatif ne doit pas créer ni supprimer des tables.
- Révocation rapide : retirez immédiatement les droits non utilisés avec
REVOKE, révisez périodiquement les accès.
Exemple générique :
Pour aller plus loin, combinez les rôles par zones fonctionnelles, limitez l’accès par schéma et définissez des privilèges par défaut sécurisés pour les objets nouvellement créés.
Audit, masquage et bonnes pratiques
- Journalisation : activez l’audit des connexions, des échecs d’authentification et des requêtes critiques. Centralisez et corrélez les logs.
- Masquage : masquez les champs sensibles dans les environnements de test. Utilisez des vues ou des fonctions pour tronquer ou anonymiser.
- Secrets management : stockez identifiants et clés dans un coffre-fort, mettez en place la rotation périodique et l’accès par identité de machine.
- Chiffrement : activez le chiffrement en transit et, si possible, au repos pour les sauvegardes et les volumes.
- Erreurs sobres : renvoyez des messages d’erreur génériques côté client, loguez le détail côté serveur.
Un procédé simple de masquage consiste à exposer une vue dédiée aux usages non productifs. Exemple conceptuel :
Enfin, couplez ces mesures à une hygiène de développement rigoureuse : revues de code focalisées sur la construction des requêtes, tests de sécurité automatisés, données de test non sensibles et politiques de sauvegarde vérifiées.
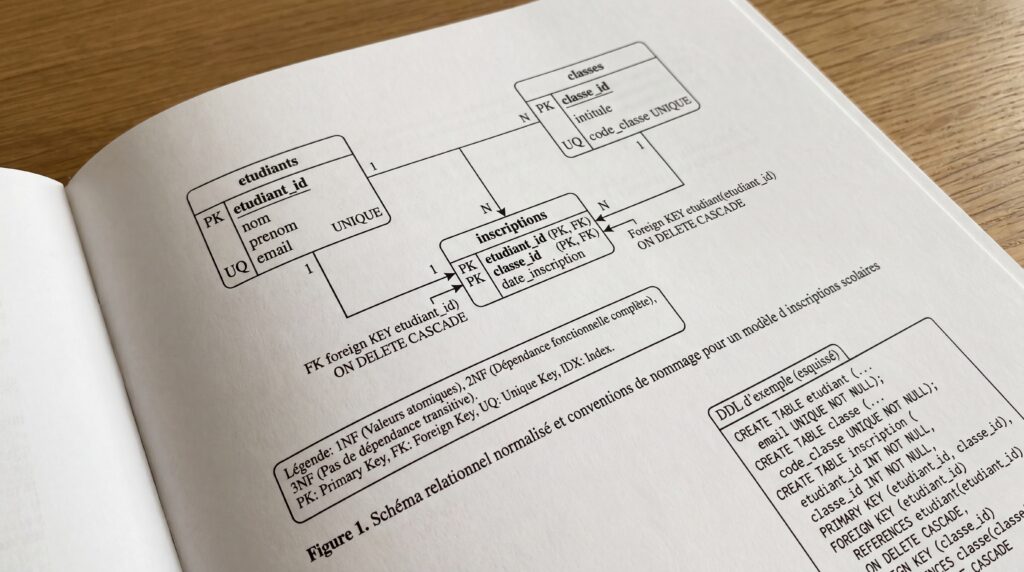
Comment modéliser une base relationnelle ?
Modéliser, c’est transformer un besoin métier en tables, colonnes et relations lisibles. L’objectif, obtenir un schéma cohérent, performant et simple à faire évoluer. En SQL, vous décrivez ce schéma avec le DDL, puis vous exploitez les données avec le DML. Par exemple, l’extrait déjà vu de la table Etudiants avec ID INT AUTO_INCREMENT PRIMARY KEY illustre la base, mais un modèle robuste va plus loin : clés, relations, contraintes, index et conventions.
- Partir des entités métier et de leurs attributs, puis identifier les relations une à plusieurs et plusieurs à plusieurs.
- Appliquer la normalisation jusqu’au bon niveau pour limiter la redondance et les erreurs.
- Choisir des clés primaires adaptées, définir les clés étrangères et l’unicité fonctionnelle.
- Ajouter les index utiles aux jointures et aux filtres les plus fréquents.
- Définir des contraintes de domaine et de présence, documenter clairement les règles.
- Adopter des conventions de nommage stables pour les tables, colonnes, clés et index.
Pourquoi normaliser (1NF, 2NF, 3NF) ?
La normalisation organise les données pour réduire la redondance et prévenir les anomalies. En 1NF, chaque colonne contient des valeurs atomiques et chaque ligne est unique. En 2NF, tout attribut non clé dépend de la totalité de la clé primaire si celle-ci est composée. En 3NF, aucun attribut non clé ne dépend d’un autre attribut non clé. Résultat, un modèle plus compact, des mises à jour plus fiables et des jointures prévisibles.
Sans normalisation, vous multipliez les anomalies. Insertion, impossible d’ajouter une classe si aucun étudiant n’y est encore inscrit. Mise à jour, changer le nom d’une classe oblige à corriger des dizaines de lignes. Suppression, retirer le dernier étudiant efface aussi l’information sur la classe. La solution, séparer par exemple Etudiants, Classes et une table d’association Inscriptions pour refléter correctement les relations et éviter ces incohérences.
Clés primaires, étrangères et index : quels choix ?
Clé primaire, naturelle ou de substitution. Une clé naturelle provient du métier, par exemple un code ISO pays. Elle favorise la lisibilité mais peut évoluer et alourdir les index si la valeur est longue. Une clé de substitution, souvent un entier auto-incrémenté ou un identifiant généré, est stable, courte et performante, mais impose de garantir l’unicité fonctionnelle par des contraintes dédiées. Dans tous les cas, une clé primaire est unique et indexée, et chaque relation se matérialise par une clé étrangère référant la clé primaire d’une autre table. Indexer les colonnes de clés étrangères accélère les jointures et les suppressions en cascade, surtout sur de grands volumes.
Cas concret avec l’exemple scolaire. Table Etudiants avec etudiant_id en clé de substitution, table Classes avec classe_id en clé de substitution et une contrainte d’unicité sur code_classe qui est la clé naturelle métier. Table Inscriptions pour le lien plusieurs à plusieurs, avec une clé primaire composée (etudiant_id, classe_id) ou un identifiant technique plus une contrainte d’unicité sur le couple. Ajouter des index sur etudiant_id et classe_id dans Inscriptions optimise les jointures courantes. Pour d’autres tables, appliquer des contraintes UNIQUE sur des attributs métiers stables, par exemple email ou code_produit, et des CHECK pour les règles de domaine.
Schémas et conventions de nommage
- Noms de tables et de colonnes en
snake_case, sans accents ni espaces, évitez les mots réservés. - Noms explicites et singuliers pour les tables d’entités, par exemple
etudiant,classe, et noms relationnels pour les tables d’association, par exempleinscription. - Clés primaires homogènes, par exemple
etudiant_id,classe_id, plutôt que desidgénériques selon les contextes. - Clés étrangères nommées sur le modèle
<table_cible>_id, par exempleclasse_iddansinscription. - Contraintes et index nommés, par exemple
pk_etudiant,fk_inscription_classe,uq_classe_code,idx_inscription_etudiant_id, pour faciliter le diagnostic. - Types de données portables, privilégiez les standards SQL quand c’est possible, testez le schéma sur plusieurs SGBD si la portabilité est un objectif.
En pratique, documentez les choix et appliquez-les partout : nommage, règles d’intégrité, politiques de suppression ou de mise à jour en cascade, indexation prévue pour les requêtes critiques. Cette discipline réduit la dette technique et améliore la maintenabilité, quelle que soit la base utilisée, MySQL, PostgreSQL, SQL Server ou Oracle.
Exemples d’utilisation des instructions SQL
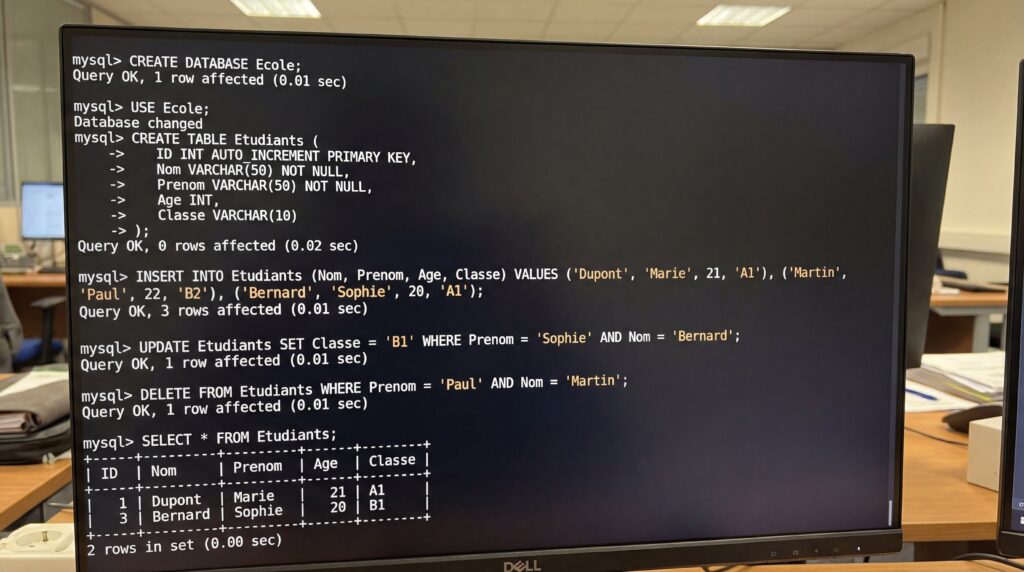
Voici des modèles prêts à l’emploi pour les opérations courantes. Copiez, adaptez et exécutez-les dans votre SGBD préféré.
Comment créer une base de données (CREATE DATABASE) ?
Exemple minimal, puis options fréquentes selon les systèmes.
- Options utiles selon le SGBD : jeu de caractères et collation, propriétaire, emplacement de stockage, chiffrement.
- Exécutez ensuite la sélection de la base pour travailler dessus.
Comment créer une table (CREATE TABLE) ?
Types, contraintes et clés, sur une table d’exemple Etudiants.
- Contraintes fréquentes : NOT NULL, DEFAULT, UNIQUE, CHECK, PRIMARY KEY, FOREIGN KEY.
- Pensez à nommer explicitement vos contraintes pour en faciliter la maintenance.
Comment insérer des données (INSERT INTO) ?
Insertion simple, multi-lignes et par requête.
Comment mettre à jour des données (UPDATE) ?
La clause WHERE est indispensable pour éviter de modifier toute la table. Exemple et retour d’informations.
Conséquence d’un UPDATE sans WHERE : toutes les lignes sont modifiées. Testez toujours la condition avec un SELECT avant exécution.
Comment supprimer des données (DELETE) ?
Suppression ciblée et différence avec TRUNCATE.
DELETE respecte la condition WHERE et enregistre les suppressions ligne par ligne. TRUNCATE est plus rapide, sans clause WHERE, et peut nécessiter des droits DDL.
Comment rechercher des informations (SELECT) ?
Projection de colonnes, filtres de base, tri et limitation.
Bon réflexe : limitez le nombre de colonnes et de lignes retournées pour gagner en performance et lisibilité.
Comment joindre des tables (JOIN) ?
Exemple pratique avec une table Notes liée à Etudiants par la clé étrangère Notes.EtudiantID → Etudiants.ID.
Utilisez INNER pour l’intersection, LEFT pour conserver tous les enregistrements de la table de gauche et compléter quand des correspondances existent.
Comment agréger avec GROUP BY/HAVING ?
Comptages par groupe avec filtre d’agrégats.
HAVING filtre après agrégation, alors que WHERE filtre les lignes avant regroupement.
Comment démarrer et valider une transaction ?
- Démarrer la transaction.
- Effectuer plusieurs opérations cohérentes.
- Valider si tout est correct, sinon annuler.
Les transactions garantissent l’atomicité : toutes les opérations réussissent ensemble, ou aucune n’est appliquée.
Quand créer un index ou une vue ?
Pour accélérer les recherches fréquentes sur une colonne filtrante, créez un index ciblé. Pour simplifier une requête complexe et sécuriser l’accès, créez une vue.
Mesurez l’effet d’un index avec les outils d’explication de plan (EXPLAIN, EXPLAIN ANALYZE) et supprimez les index inutilisés pour éviter le surcoût en écriture.
Il ne s’agit là que d’exemples essentiels pour bien démarrer. Adaptez la syntaxe à votre SGBD et testez chaque requête sur un échantillon avant de la lancer en production.
À quoi sert le langage SQL ?

Le langage SQL est utilisé dans tous les domaines où les bases de données sont exploitées, pour gérer des transactions, analyser l’historique, produire des rapports, intégrer des sources hétérogènes et alimenter des cas d’usage data. Dans la finance, par exemple, des applications de banking et de paiement stockent et interrogent des transactions. Les plateformes de streaming manipulent d’immenses catalogues, et les réseaux sociaux enregistrent profils, publications et interactions tout en personnalisant l’expérience utilisateur.
- OLTP (traitement de transactions en ligne) : applications opérationnelles temps réel comme e‑commerce, paiements, ERP ou CRM. Exigences typiques : cohérence des transactions, faible latence et forte concurrence d’accès. SQL sert à écrire et sécuriser les opérations courantes (INSERT, UPDATE, DELETE, COMMIT, ROLLBACK, droits via GRANT/REVOKE).
- OLAP et entrepôts de données : analyses sur de grands volumes historiques dans des entrepôts et data marts. SQL est utilisé pour agréger, joindre et explorer les données (SELECT, JOIN, GROUP BY, fonctions fenêtrées) en vue d’indicateurs, d’explorations ad hoc et de scénarios décisionnels.
- Reporting et Business Intelligence : création de tableaux de bord et d’états opérationnels ou réglementaires. Les vues, vues matérialisées et filtres d’accès permettent d’exposer des jeux de données fiables à des outils de BI en self‑service tout en maîtrisant la sécurité.
- Intégration de données (ETL/ELT) : ingestion, nettoyage, normalisation et consolidation de sources multiples. Selon les systèmes, on utilise des opérations de chargement en masse, des requêtes de transformation (INSERT INTO … SELECT), des upserts ou MERGE, et des contraintes d’intégrité pour fiabiliser les pipelines.
- Data science et IA : extraction de jeux d’entraînement, création de features par agrégations et fenêtres, constitution de feature stores, puis consommation depuis des notebooks ou applications analystes. SQL accélère l’exploration, la préparation et la mise à disposition de données de qualité pour les modèles.
Qu’est-ce que le NoSQL ?
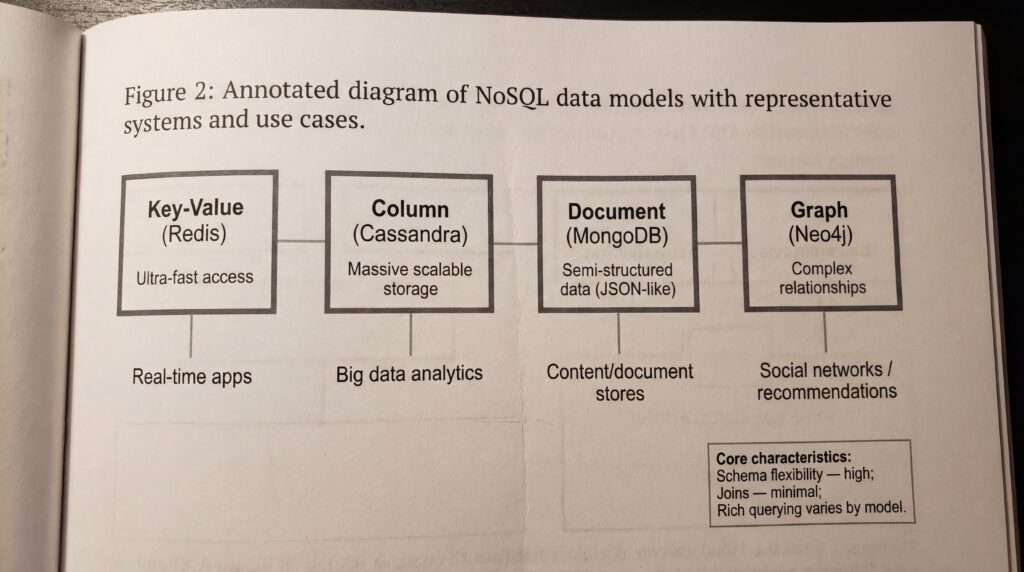
Le terme NoSQL désigne une famille de bases de données non relationnelles qui s’écartent du modèle tables et schéma fixe. Elles stockent les informations dans des structures variées, acceptent des schémas flexibles et sont pensées pour la distribution et l’évolutivité horizontale.
On les adopte lorsque la rapidité, la souplesse de modèle ou la montée en charge massive priment, par exemple pour le temps réel, le big data ou les réseaux sociaux. Exemples représentatifs : magasins clés‑valeurs comme Redis, bases à colonnes larges comme Cassandra, bases de documents comme MongoDB et bases de graphes comme Neo4j.
Quelle est la différence entre SQL et NoSQL ?
SQL est un langage conçu pour gérer des bases de données relationnelles structurées, où les informations sont organisées en tables selon un schéma prédéfini. Par contre, NoSQL est conçu pour traiter des données non structurées ou semi-structurées, offrant une plus grande souplesse grâce à des modèles tels que les documents, les clés-valeurs ou encore les graphes.
SQL est parfait pour les applications qui exigent des transactions sûres et des relations complexes, tandis que NoSQL se concentre sur l’évolutivité horizontale et la vitesse pour gérer de grandes quantités de données diverses. Le choix dépend des exigences du projet (structure des données, niveau de cohérence attendu, volume et variabilité, besoin de débit et de faible latence).
| Critère | SQL (relationnel) | NoSQL (non relationnel) |
|---|---|---|
| Modèle de données | Tables, lignes, colonnes, schéma fixe, normalisation et relations via clés primaires/étrangères | Modèles variés : clé-valeur, documents, colonnes, graphes, schéma flexible |
| Langage et requêtes | SQL déclaratif standard, jointures puissantes, agrégations riches | APIs et langages propres à chaque moteur, jointures limitées ou absentes selon le type |
| Cohérence et transactions | ACID, cohérence forte, transactions complexes | Souvent BASE et cohérence éventuelle, options de cohérence configurables selon le moteur |
| Performances | Excellentes pour les requêtes complexes et relations riches, latence stable | Débit très élevé et faible latence pour accès clé ou flux massifs, requêtes analytiques complexes moins naturelles selon le modèle |
| Scalabilité | Principalement verticale, sharding possible mais plus complexe | Horizontalement native (partitionnement, répartition de charge) pour monter en charge |
| Disponibilité | Réplication et haute disponibilité selon SGBDR, priorité à la cohérence | Accent sur disponibilité et tolérance au partitionnement selon les choix CAP |
| Exemples | PostgreSQL, MySQL, SQL Server, Oracle | MongoDB, Cassandra, Redis, Neo4j |
Quelles différences de structure, performances et scalabilité ?
Structure : les bases SQL imposent un schéma fixe et des relations explicites, idéal pour garantir l’intégrité des données et des jointures fiables. Les bases NoSQL acceptent un schéma flexible, ce qui accélère l’évolution du modèle et l’ingestion de données hétérogènes.
Performances : SQL excelle pour des requêtes ad hoc complexes, des agrégations et des jointures multi‑tables avec une cohérence stricte. NoSQL privilégie le débit (throughput) et la faible latence sur des accès simples ou des charges d’écriture élevées, avec une cohérence souvent éventuelle.
Scalabilité : en SQL, on scale surtout verticalement (machines plus puissantes) et l’horizontal demande une architecture soignée. En NoSQL, la scalabilité horizontale par partitionnement et réplication est native pour absorber croissance et pics de trafic.
Quels cas d’usage typiques ?
- Quand choisir SQL : systèmes financiers et comptables, e‑commerce transactionnel, ERP et CRM, réservations, conformité et audit, entrepôts de données relationnels avec fortes contraintes d’intégrité.
- Quand choisir NoSQL : profils et sessions utilisateur à grande échelle, catalogues produits très variables, event streaming et IoT, messagerie et temps réel, moteurs de recommandation, caches applicatifs, données en graphe (réseaux sociaux).
- Approches polyglottes : combiner le meilleur des deux mondes selon le besoin. Exemple concret :
- Commandes, paiements, stocks en SQL pour bénéficier des transactions ACID.
- Catalogue produit en base de documents pour un schéma flexible.
- Sessions et cache en clé‑valeur pour une latence minimale.
- Relations complexes (par exemple suggestions d’amis) en base de graphes.
Quels sont les systèmes de bases de données SQL les plus populaires ?
Un système de base de données (SGBD) est un programme permettant de travailler avec une base de données via une interface et des outils dédiés. Il simplifie le quotidien des équipes en automatisant des tâches récurrentes (sauvegardes, réplication, supervision) et en proposant des assistants de modélisation et d’administration.
Voici un panorama comparatif, orienté pratique, des quatre SGBD relationnels les plus utilisés en production : Oracle Database, MySQL, Microsoft SQL Server et PostgreSQL.
SGBD Atouts clés Idéal pour Licence Outils et écosystème Oracle Database Robustesse, haute disponibilité, sécurité avancée Applications critiques, data warehousing à grande échelle Commercial Suite Oracle, RAC, Data Guard, APEX MySQL Simplicité, très répandu sur le web, InnoDB transactionnel Applications web LAMP/LEMP, micro‑services Open source (GPL) + offres commerciales MySQL Shell, Workbench, écosystème LAMP Microsoft SQL Server Intégration Microsoft, outils BI natifs SI Windows/Azure, reporting et analyse Commercial (Express/Developer gratuites) SSMS, Azure Data Studio, SSIS/SSAS/SSRS PostgreSQL Respect des standards, extensible, types avancés Produits data‑driven, géospatial, JSON Open source (licence PostgreSQL) psql, pgAdmin, extensions (PostGIS, etc.) Oracle Database : pour quels usages ?
L’un des SGBD les plus déployés à l’échelle mondiale est Oracle Database. Ce système SQL équipe de nombreuses industries, notamment pour le Data Warehousing et le traitement de transactions en ligne.
- Robustesse entreprise : performances stables, ACID, partitionnement, compression, chiffrement.
- Haute disponibilité : clustering et bascule (RAC, Data Guard) pour les charges 24/7.
- Gouvernance et sécurité : contrôle d’accès fin, masquage, audit.
- Outils intégrés : gestion des sauvegardes, supervision, automatisation.
Cas concret : une banque opérant plusieurs pays consolide en temps réel paiements et risques sur un entrepôt de données volumineux, avec exigence de continuité de service, reprise après incident et chiffrement des données sensibles.
MySQL : points forts et limites ?
Un autre système populaire est MySQL, proposé en open source et gratuitement pour les individus et les entreprises. Les petites entreprises et les startups l’apprécient particulièrement, et de nombreuses applications Open Source l’utilisent.
- Simplicité et adoption web : s’intègre facilement aux piles LAMP/LEMP.
- InnoDB par défaut : transactions, intégrité référentielle, row-level locking.
- Réplication : options maître‑réplique, groupe, et failover outillage.
- Variantes : écosystèmes proches comme MariaDB pour certains besoins.
- Limites connues : moins de fonctionnalités avancées que PostgreSQL/Oracle pour requêtes analytiques complexes, certaines extensions propriétaires.
En contraste : pour des modèles de données riches, des joints complexes et des types avancés, PostgreSQL est souvent préféré. Pour des sites web à fort trafic avec schémas simples, MySQL reste un excellent choix.
SQL Server : écosystème et outils ?
Microsoft propose son propre SGBD SQL Server. Très intégré à l’écosystème Microsoft, il équipe des applications métiers sur Windows et s’exécute aussi sous Linux et dans Azure.
- Intégration Microsoft : Active Directory, .NET, Power BI, Azure.
- Outils d’administration : SSMS et Azure Data Studio.
- BI/ETL natifs : SSIS, SSAS, SSRS.
- Dialecte : T‑SQL, procédures stockées et fonctions fenêtre riches.
Explication : dans un environnement déjà outillé Microsoft (Azure, Power Platform, Excel), SQL Server réduit les frictions de déploiement, centralise BI et ETL et offre un cycle de vie homogène des données.
PostgreSQL : pourquoi le choisir ?
Enfin, PostgreSQL est un grand concurrent de MySQL. Ce SGBD open source, compatible avec macOS, Windows et Linux, met l’accent sur le respect de la syntaxe SQL standard et facilite l’extensibilité.
- Standards et fiabilité : conformité élevée aux standards, MVCC, transactions complexes.
- Types avancés :
JSONB, tableaux, plages,hstore, CTE récursifs, fenêtres. - Extensibilité : extensions comme PostGIS pour le géospatial, full‑text search, FDW pour accéder à d’autres sources.
- Licences permissives : idéale pour produits distribués et environnement multi‑cloud.
Données et preuves d’usage : PostgreSQL est souvent retenu pour des plateformes produits où schémas évoluent, où l’on combine données relationnelles, JSON et géospatiales, tout en gardant des garanties ACID solides.
Quelles différences pratiques entre ces SGBD ?
Critère Oracle MySQL SQL Server PostgreSQL Licence Commerciale GPL + offres commerciales Commerciale (Express/Developer gratuites) Open source permissive Plateformes Linux/Unix/Windows, cloud Oracle Linux/Windows/macOS, clouds variés Windows, Linux, Azure Linux/Windows/macOS, multi‑cloud Outils natifs Suite Oracle, AWR, RMAN Workbench, Shell SSMS, Azure Data Studio, SSIS/SSAS/SSRS psql, pgAdmin, extensions Dialectes SQL PL/SQL MySQL SQL T‑SQL SQL standard + extensions Types/Extensions Objets, part., options avancées Types courants, JSON Types usuels, analyses BI JSONB, PostGIS, FDW, plages HA/Clustering RAC, Data Guard Réplication, Group Replication Always On, réplication Streaming, Patroni, etc. Cas typiques Critique, ERP, entrepôt très large Web, SaaS simples à moyens SI Microsoft, BI/ETL intégrés Produits data‑riches, géospatial À retenir : le choix dépend surtout de vos contraintes (licence, compétences internes, écosystème) et de vos exigences (disponibilité, fonctions analytiques, types de données). Les dialectes ont de petites divergences de syntaxe : par exemple, la limitation de résultats se fait par
LIMITen MySQL/PostgreSQL, parTOPouOFFSET FETCHen SQL Server, et parFETCH FIRSTen Oracle. Planifiez ces différences si vous migrez ou ciblez la portabilité.Quels outils SQL utiliser ?
Au-delà du choix du SGBD (PostgreSQL, MySQL, SQL Server, Oracle), le quotidien se joue avec des outils qui facilitent l’écriture de requêtes, l’administration et l’intégration au code. Voici une vue d’ensemble, sans tomber dans l’exhaustivité produit.
- Clients et IDE SQL : interfaces graphiques ou en ligne de commande pour interroger, explorer les schémas et gérer les connexions.
- Migration et sauvegarde : export logique (dump), sauvegardes natives, réplication, et outils de migration versionnée.
- Automatisation et CI/CD : exécution de scripts SQL dans les pipelines, vérifications de schéma et tests de régression.
- Intégration applicative : pilotes, requêtes paramétrées, ORMs pour accélérer le développement tout en maîtrisant les performances.
Quels clients/IDEs privilégier ?
- psql (PostgreSQL) : client en ligne de commande, rapide, scriptable, idéal pour l’automatisation et le dépannage.
- DBeaver : IDE multi‑SGBD, pratique si vous travaillez avec plusieurs moteurs, exploration de schémas, éditeur SQL, vues ER.
- MySQL Workbench : l’environnement graphique de référence pour MySQL/MariaDB (requêtes, modélisation, administration).
- SQL Server Management Studio (SSMS) : la boîte à outils complète pour Microsoft SQL Server (requêtes, sécurité, sauvegardes).
Choisissez selon votre SGBD, votre OS et vos usages : un client CLI pour les scripts et opérations rapides, un IDE graphique pour l’exploration et la modélisation. En contexte multi‑bases, DBeaver apporte une vue unifiée. Sur un moteur unique, l’outil natif du SGBD reste souvent le plus abouti.
Quels outils de migration et sauvegarde ?
- Dump/restore : export logique du schéma et des données, compressible et portable, idéal pour clones de dev, migrations simples et reprises après incident.
- Sauvegardes natives : mécanismes du SGBD pour des sauvegardes cohérentes en ligne, restauration à un instant T, rotation des journaux.
- Réplication : synchrone ou asynchrone pour haute disponibilité, bascule et migrations avec interruption minimale.
- Migrations versionnées : scripts de schéma et de données gérés dans le contrôle de version, exécutés par des outils comme Flyway ou Liquibase pour tracer, valider et rejouer les changements.
Bonnes pratiques : gardez vos scripts de migration dans le dépôt applicatif, appliquez‑les via la CI/CD, testez régulièrement la restauration, chiffrez et externalisez les sauvegardes (règle 3‑2‑1), planifiez une fenêtre de maintenance, préparez un plan de retour arrière et surveillez le temps d’exécution avant passage en production.
ORMs et intégration applicative : utiles ou pas ?
Atouts : un ORM accélère le développement (modèles, CRUD), renforce la sécurité par des requêtes paramétrées et facilite la portabilité entre moteurs. Limites : risque de SQL sous‑optimal, problèmes de type N+1, difficulté à exploiter des fonctionnalités spécifiques du SGBD. En pratique, adoptez une approche hybride : ORM pour la majorité des opérations, et SQL natif paramétré (ou vues/procédures) pour les rapports, agrégations lourdes et requêtes de performance critique.
Exemple d’approche pragmatique : l’application utilise l’ORM pour créer et mettre à jour les enregistrements du quotidien, mais s’appuie sur une requête SQL paramétrée revue avec
EXPLAINpour le tableau de bord mensuel. L’important : toujours lier les paramètres côté client pour éviter l’injection SQL, et journaliser les requêtes lentes pour guider l’optimisation.Comment apprendre le langage SQL ?
Pour progresser vite et durablement en SQL, suivez un parcours simple, orienté pratique : comprenez les bases, entraînez-vous tous les jours, puis livrez de petits projets concrets avec relectures. Voici un plan d’action prêt à l’emploi.
- Découvrir les fondamentaux via un cours d’introduction et la documentation officielle.
- Pratiquer chaque jour sur des plateformes interactives et des sandboxes.
- Installer un environnement local pour exécuter vos requêtes hors ligne.
- Réaliser des mini-projets à partir de jeux de données publics.
- Adopter des pratiques d’équipe : style guide, tests, et code review SQL.
Par où commencer (cours, docs, sandboxes) ?
Il existe une large variété d’options pour apprendre SQL. Commencez par un cours structuré, gardez la documentation officielle sous la main, puis alternez entre exercices guidés et expérimentation libre dans une sandbox.
- Ressources officielles (références à garder ouvertes) : Documentation PostgreSQL, MySQL Reference Manual, Microsoft SQL Server docs, Oracle Database docs, SQLite docs.
- Cours et plateformes interactives : SQL.sh (cours et fiches pratiques), OpenClassrooms (parcours débutant), W3Schools SQL, SQLBolt.
- Sandboxes en ligne : DB Fiddle, SQL Fiddle, SQLite Online pour tester des requêtes sans rien installer.
- Environnements locaux : installez un SGBD et un outil client graphique ou un IDE léger. Par exemple PostgreSQL + pgAdmin, MySQL + MySQL Workbench, SQL Server Developer + Azure Data Studio, ou un client universel comme DBeaver.
Si vous êtes confronté à un problème ou une difficulté durant votre apprentissage ou votre utilisation de SQL, vous pouvez aussi vous tourner vers des communautés en ligne pour demander de l’aide et étoffer votre expertise. Vous pourrez trouver le soutien de programmeurs expérimentés sur des plateformes comme Stack Overflow, Quora, Reddit ou StackExchange.
Exercices, mini-projets et datasets publics
La pratique régulière est la clé. Alternez exercices ciblés et mini-projets pour consolider vos acquis et développer votre autonomie d’analyse.
- Exercices guidés : séries d’exercices sur SQL.sh, quiz et TP sur OpenClassrooms, et ateliers pratiques sur W3Schools.
- Datasets publics : Kaggle Datasets, data.gouv.fr, Paris Open Data, NYC Open Data, IMDb Datasets.
- Idées de mini-projets : tableau de bord de ventes fictives, analyse d’avis de films, suivi de commandes et retards, exploration d’un catalogue de produits avec jointures et agrégations, top N et fenêtres temporelles.
Cas concret : 1) Choisissez un dataset Kaggle, 2) modélisez rapidement 2 à 4 tables cibles, 3) chargez-les dans SQLite ou PostgreSQL, 4) rédigez 10 à 15 requêtes couvrant SELECT, JOIN, GROUP BY, HAVING, fenêtres et sous-requêtes, 5) documentez vos choix et résultats, 6) partagez le projet sur GitHub pour recueillir des retours.
Quelques semaines suffisent pour apprendre les bases de SQL si vous avez déjà des notions de programmation et connaissez d’autres langages. La meilleure façon d’accélérer votre apprentissage est de travailler sur des projets concrets : entraînez-vous chaque jour, et vous progresserez rapidement.
Pratiques d’équipe et code review SQL
- Style guide : mots clés en majuscules, noms en
snake_case, alias explicites, CTE pour découper une requête longue, commentaires brefs et utiles. - Lisibilité : éviter
SELECT *en production, limiter la profondeur des sous-requêtes, indenter de façon cohérente, nommer clairement les agrégations. - Tests et sécurité : valider les filtres avec des jeux d’échantillons, utiliser des transactions pour les mises à jour sensibles, vérifier le traitement des valeurs NULL, appliquer le principe du moindre privilège.
- Performance : analyser les plans avec
EXPLAINou équivalent, contrôler l’usage des index, traquer les jointures cartésiennes, poser desLIMITen phase d’exploration. - Code review : adopter une checklist commune (lisibilité, exactitude métier, gestion des doublons, cohérence des types, performance), décrire l’intention de la requête et les cas limites dans la PR, fournir un échantillon de résultats attendu.
Envie d’un accompagnement structuré et de retours d’experts sur vos projets SQL ? Découvrez notre formation SQL ou notre formation de Data Engineer.



