
Decoded©
-
SVM, quoi, comment, pourquoi ?
Bienvenue dans la première partie de cette mini-série dédiée aux SVM. Quand on pense Machine Learning, on pense généralement à des méthodes récentes, encore mal comprises, et utilisées empiriquement, à la manière d’un apprenti sorcier. En effet, que ce soit les algorithmes génétiques, les réseaux de neurones, le Boosting… on qualifie souvent ces algorithmes de […]
Lire la suite -
Gestion des problèmes de Classification déséquilibrée – Partie II
Comment geÌrer les probleÌ€mes de Classification deÌseÌquilibreÌe Partie II Les méthodes pour lutter contre le déséquilibre des données Après avoir détaillé les différents problèmes liés au déséquilibre des données et démontré que le choix de la bonne métrique de performance est essentiel pour l’évaluation de nos modèle, nous allons présenter une liste non-exhaustive des techniques […]
Lire la suite -
Agentforce par Salesforce : Qu’est-ce que c’est ? Comment ça fonctionne ?
Le secteur des CRM est passé à une vitesse supérieure avec Agentforce qui amène des capacités de type ChatGPT au secteur de la relation client. Au menu : la création d’agents de conversation spécialisés intégrant dans leurs réponses le mode opératoire de l’entreprise…
Lire la suite -
Oracle GoldenGate : Qu’est-ce que c’est ? Comment ça marche ?
Oracle Goldengate est une solution de réplication de données en temps réel proposée par le géant américain de l’informatique Oracle. Découvrez ses fonctionnalités, son architecture, ses cas d’usage et ses nombreux bénéfices pour les entreprises !
Lire la suite -
Séries temporelles : Daniel peux-tu nous en parler ?
Nouveau rendez-vous avec Daniel, le support technique des formations Liora. L’expert en data science qui accompagne les apprenants tout au long de leurs formations. Aujourd’hui, il nous parle des séries temporelles. Les séries temporelles constituent l’un des objets d’études les plus répandus de la science des données. Dans cet article, vous découvrirez les composantes principales d’une série temporelle.
Lire la suite -
Agents IA crypto : comment l’IA révolutionne les cryptomonnaies ?
Nous avons d’une part le domaine ultra dynamique des cryptomonnaies. Au dire de certains, il fourmille d’opportunités à saisir au vol. Et de l’autre, nous avons celui de l’intelligence artificielle avec ses capacités d’analyse disponibles à toute heure du jour ou de la nuit. En mariant les deux, aurions-nous le meilleur des deux mondes ?
Lire la suite -
Kibana : l’outil de visualisation des données indexées à Elasticsearch
Le back end est essentiel pour le développement web, mais aussi pour la Data. Dans cet article, nous allons partager avec vous tout ce qu’il faut savoir sur Kibana, notamment son fonctionnement dans Elasticsearch à travers ses fonctions les plus représentatives.
Lire la suite -
GPU : qu’est-ce que c’est et pourquoi l’utiliser en Data Science ?
Un GPU ou « Graphics Processing Unit » est le composant d’un ordinateur permettant l’affichage des images sur l’écran. Il s’agit de l’unité de traitement graphique.
Lire la suite -
SVM, quoi, comment, pourquoi ? Part.2
Bienvenue dans la seconde partie de ce dossier dédié au Support Vector Machine. Dans l’article précédent, nous avions détaillé le fonctionnement et les principaux défauts des Maximal Margin Classifier. Notre objectif maintenant est d’autoriser notre algorithme à réaliser un certain nombre d’erreurs lors du choix de la droite de séparation. On parle alors de « soft […]
Lire la suite -
Formation de Data Architect : compétences, salaire, formation
Le Data Architect est un professionnel chargé de concevoir l’architecture de données d’une entreprise. Il définit le système de collecte et de stockage des données, permettant aux Data Scientists de les analyser. Découvrez comment suivre une formation Data Architect pour exercer ce métier très recherché !
Lire la suite -
MLOps : Le DevOps appliqué aux projets de Machine Learning
Dans un précédent article, nous présentions la philosophie DevOps, et comment cette nouvelle approche permet une livraison de valeur plus rapide pour les entreprises au travers de l’unification des équipes de développement (Dev) et des opérations (Ops), qui travaillaient préalablement en silos. Dans cet article, nous allons nous intéresser à l’application de cette approche dans le cadre de problématiques de Machine Learning: on parle de MLOps.
Lire la suite -
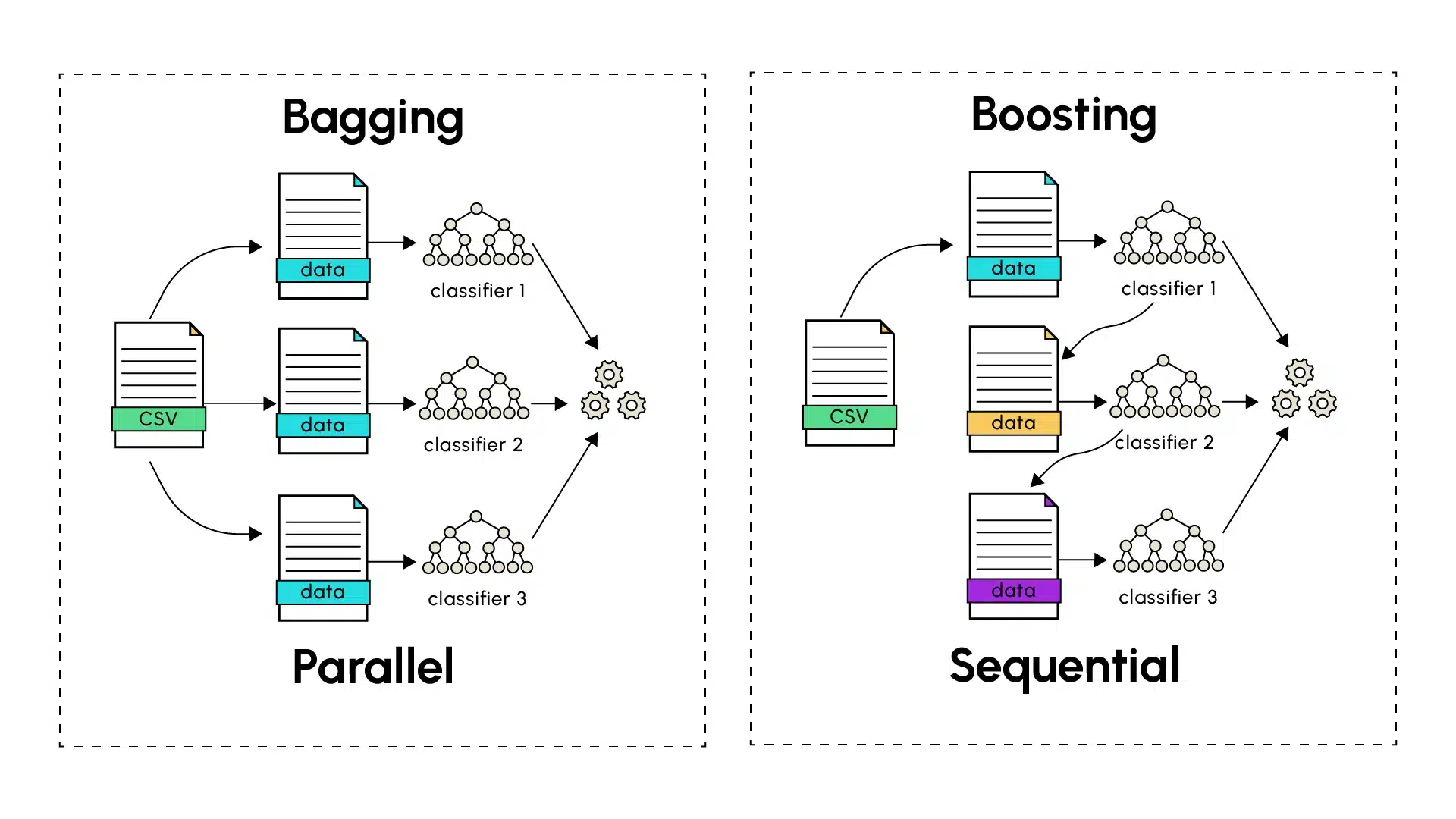
Bagging vs Boosting : Tout ce qu’il faut savoir
Lorsque l’apprentissage d’un modèle singulier peine à livrer de bonnes prédictions, les méthodes d’apprentissage d’ensemble apparaissent souvent comme une solution de choix. Les techniques d’ensemble les plus connues, le Bagging (Bootstrap Aggregating) et le Boosting, ont toutes toutes deux comme objectif d’améliorer la précision des prédictions faites lors de l’apprentissage automatique en combinant les résultats de modèles individuels, afin d’en extraire des prédictions finales plus robustes et précises.
Lire la suite






The newsletter of the future
Get a glimpse of the future straight to your inbox. Subscribe to discover tomorrow’s tech trends, exclusive tips, and offers just for our community.
