
Tous ses articles
-
L’apprentissage continu (continual learning) : Qu’est-ce que c’est ?
L’apprentissage continu ouvre des nouvelles perspectives dans l’ère de l’intelligence artificielle en constante évolution. Cette approche permet aux modèles de s’adapter progressivement aux nouvelles données sans perdre les connaissances préalablement acquises. Flexibles et résilients, les systèmes d’apprentissage continu évoluent harmonieusement avec les changements du monde réel. Cet article explore les principes clés de l’apprentissage continu, ses applications ainsi que les défis et solutions face à l’avenir dynamique des données.
Lire la suite -
Prompt Crafting : Comment faire de bons prompts IA ?
Le Prompt Crafting est un terme désignant la construction de prompts pour interagir avec l’intelligence artificielle générative. Découvrez tout ce qu’il faut savoir sur cette discipline, et comment devenir un véritable maître !
Lire la suite -
Prompt Engineering Certification : pourquoi et comment devenir expert en IA générative ?
Une certification de Prompt Engineering permet d’acquérir et de démontrer une expertise professionnelle dans le domaine en plein essor de l’IA générative. Découvrez pourquoi et comment obtenir un tel titre, et quels sont les meilleurs !
Lire la suite -
Data Lakehouse : Qu’est-ce que c’est ? À quoi sert-il ?
Afin d’optimiser leur gestion et leur analyse de données, les entreprises utilisent généralement deux solutions de Data Science, le data lake et le data warehouse. Ces deux technologies offrent de nombreuses possibilités d’analyse et de sauvegarde des données. Pour autant, un nouveau système offre la possibilité de fusionner les points forts de ces deux méthodes en un seul logiciel, le data lakehouse.
Lire la suite -
StyleGAN, le générateur de visages humains qui n’existent pas
I – Introduction Si vous vous êtes tenu informé des innovations dans le domaine du Deep Learning en 2019, vous avez sans doute entendu parler de StyleGAN le réseau antagoniste génératif développé par des chercheurs de chez Nvidia en fin 2018. Cet algorithme s’est fait connaître du grand public en février 2019, alors qu’il venait […]
Lire la suite -
Anaconda Navigator : Simplifier la navigation entre outils Python
Particulièrement populaire auprès des data scientists, Anaconda Navigator se présente comme un gestionnaire d’environnement open source. Alors de quoi s’agit-il exactement ? Quelles sont ses fonctionnalités ? Comment installer cet outil ? C’est ce que nous allons voir dans cet article.
Lire la suite -
IA France : top 10 des start-ups françaises en IA
Depuis mars 2018 et le « rapport Villani » sur l’état de l’intelligence artificielle en France, le gouvernement a un objectif en tête : faire des start-ups françaises les leaders de l’intelligence artificielle. Si les Etats-Unis et la Chine semblent avoir un temps d’avance, la France possède des start-ups prometteuses dans le domaine de l’intelligence artificielle. Nous allons donc faire un tour d’horizon de li IA en France par le biais des 10 meilleures start-ups en matière d’intelligence artificielle dans l’hexagone.
Lire la suite -
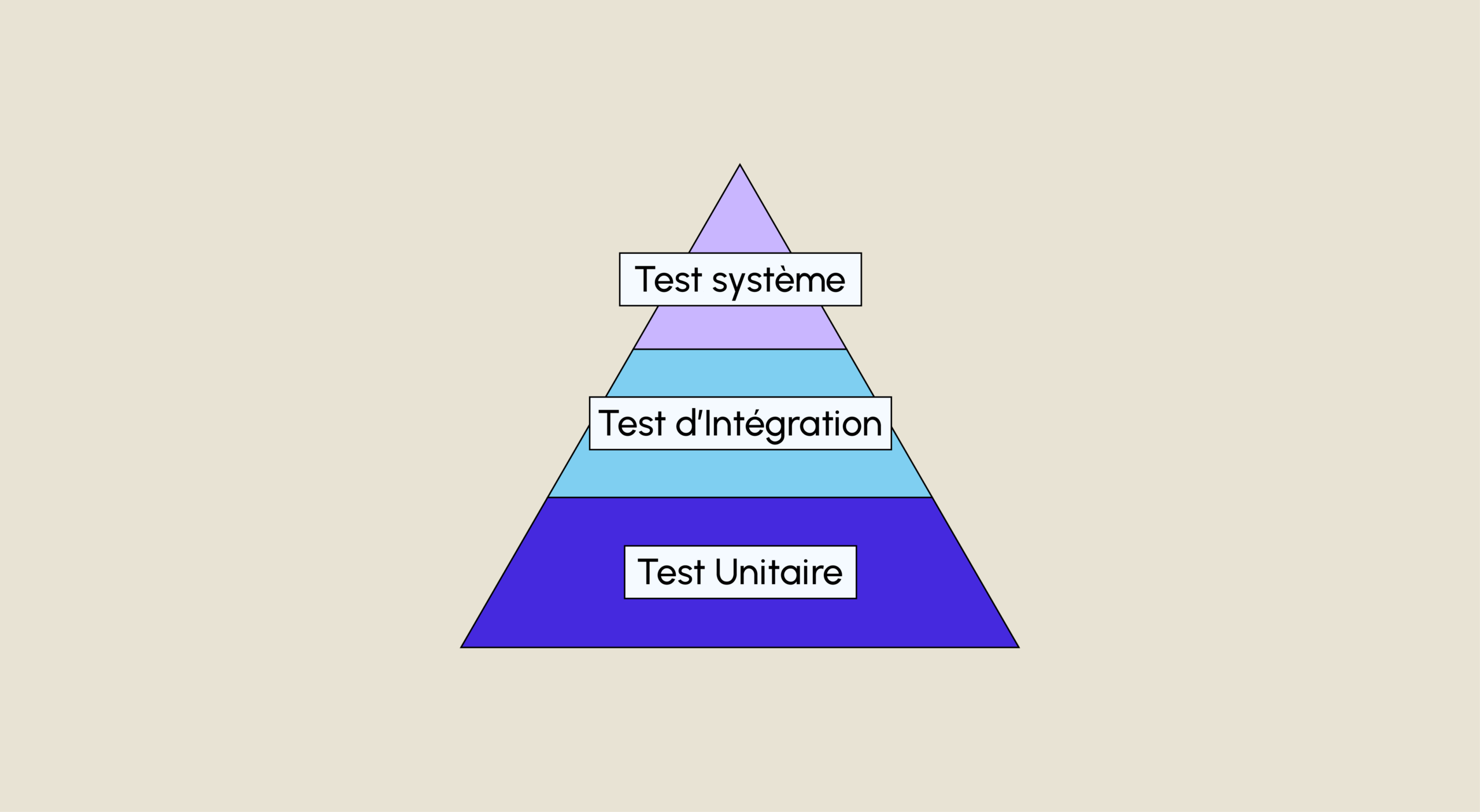
Le Test unitaire en analyse de données
Définition de Test Unitaire Le test unitaire, en programmation informatique, désigne la procédure qui permet de s’assurer du bon fonctionnement d’un logiciel ou d’un code source (respectivement d’une partie d’un logiciel ou d’une partie d’un code). Après avoir été longtemps considéré comme une tâche de second plan, le test unitaire est devenu une pratique courante […]
Lire la suite -
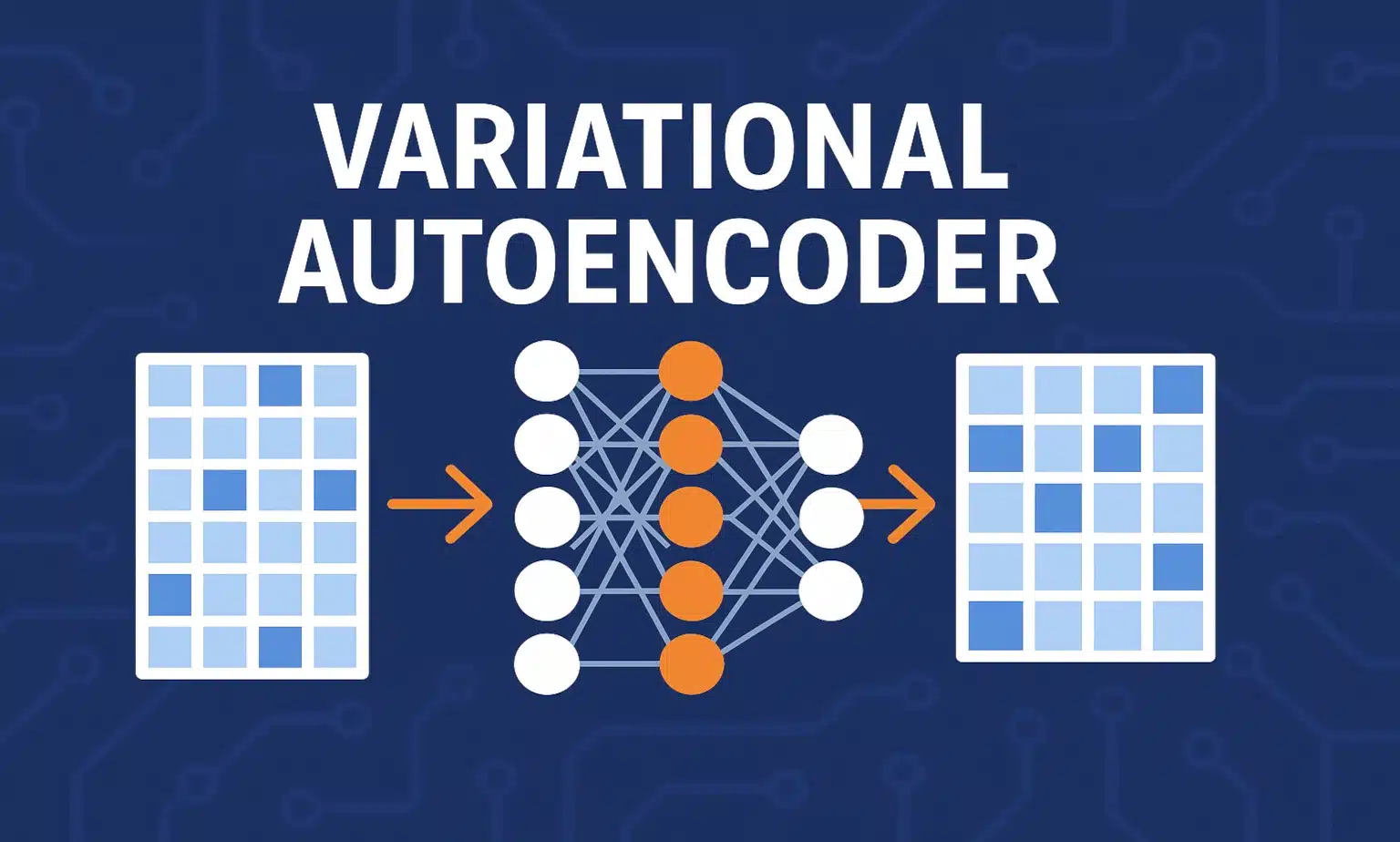
Variational Autoencoder (VAE) : Qu’est-ce que c’est ?
Les autoencodeurs sont des réseaux de neurones non supervisés conçus pour compresser puis reconstruire des données. Leur architecture repose sur deux parties : un encodeur, qui réduit la dimensionnalité, et un décodeur, qui tente de reconstruire l’entrée initiale.
Lire la suite -
Développeur IA : En quoi ça consiste ? Quelles caractéristiques ?
À l’heure de l’essor de l’intelligence artificielle, les développeurs IA sont de plus en plus recherchés par les entreprises. Découvrez tout ce que vous devez savoir sur ce métier, les compétences nécessaires, et comment les acquérir par le biais d’une formation !
Lire la suite -
SQL Server Management Studio : Tout savoir de cet outil Microsoft
SQL Server Management Studio (SSMS) est un environnement de développement et d’administration intégré conçu spécifiquement pour Microsoft SQL Server. Il permet de travailler plus efficacement avec les bases de données SQL Server, que ce soit pour la conception, le développement, la maintenance ou la surveillance. Découvrez tout ce qu’il faut savoir !
Lire la suite -
Python : pourquoi et comment utiliser les annotations ?
Les annotations Python offrent des informations additionnelles sur les variables ou les fonctions. Elles permettent notamment d’améliorer la lisibilité du code, ou de détecter les erreurs par le biais d’un IDE ou de bibliothèques tierces. Découvrez tout ce que vous devez savoir sur les annotations Python, et comment apprendre à les utiliser.
Lire la suite








The newsletter of the future
Get a glimpse of the future straight to your inbox. Subscribe to discover tomorrow’s tech trends, exclusive tips, and offers just for our community.



