
Tous ses articles
-
Isolation Forest : Comment détecter les anomalies dans une dataset ?
Lire la suite -
Reinforcement Learning : Définition et application
Lire la suite -
Hugging Face ? : Tout ce qu’il faut savoir sur cette startup IA
Lire la suite -
5 fonctions de Scikit-learn indispensables à connaître
Avant de vous faire découvrir ses fonctions utiles, rappelons-nous ce qu’est Scikit-learn et dans quel cas l’utiliser. Scikit-Learn est une bibliothèque Python destinée au Machine Learning, pour l’apprentissage supervisé ou non supervisé. Elle offre également la possibilité d’analyser des modèles avec les moyens statistiques.
Lire la suite -
Service Mesh : Qu’est-ce que c’est ? Comment ça fonctionne ?
Le Service Mesh simplifie et automatise la communication entre les microservices qui composent une application logicielle. Découvrez tout ce que vous devez savoir sur cette technologie, et son rôle dans le domaine de la Data Science !
Lire la suite -
Data Vault : qu’est-ce que c’est ? quels sont les avantages ?
Le Data Vault est une approche innovante de gestion de données, offrant une méthode flexible et évolutive pour la modélisation. Découvrez tout ce qu’il faut savoir, et comment apprendre à maîtriser les différentes formes de stockage de données !
Lire la suite -
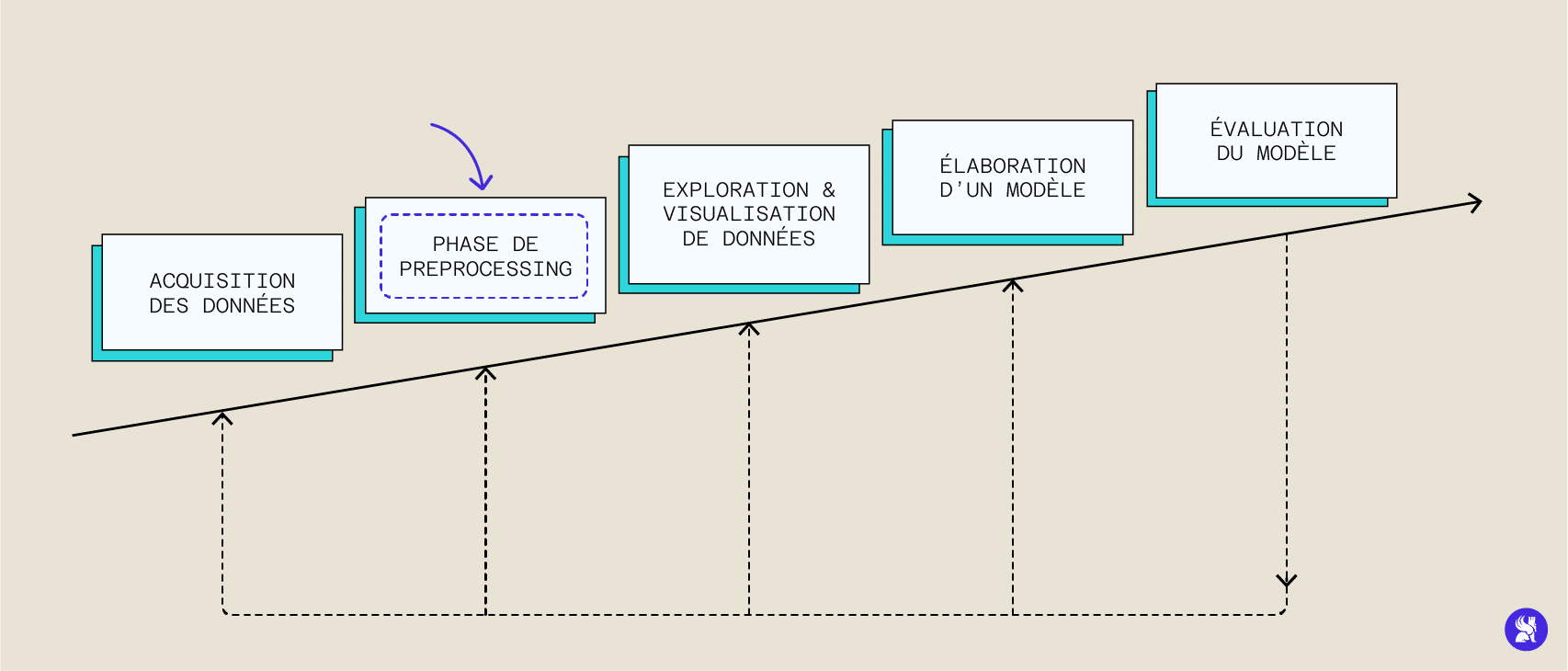
Préprocessing: Qu’est-ce que c’est ? Comment ça marche ?
La multiplication de l’acquisition de données et leur traitement systématique a permis l’essor des méthodes de machine learning nécessitant de nombreuses données pour tourner et s’entraîner. Bien que l’on puisse naïvement penser qu’il suffit d’un grand nombre de données pour avoir un algorithme performant, les données dont nous disposons sont la plupart du temps non adaptées et il faut la plupart du temps les traiter préalablement pour pouvoir ensuite les utiliser : c’est l’étape de preprocessing.
Lire la suite -
Reverse ETL : Qu’est-ce c’est ? À quoi ça sert ?
Si les données brutes se multiplient, les organisations doivent les transformer pour pouvoir exploiter les données disponibles et créer de la valeur. Traditionnellement, les entreprises suivaient le processus ETL pour traiter les données. Mais depuis quelques années, ce modèle change pour laisser place au reverse ETL. Alors de quoi s’agit-il ? Quelles sont les différences entre les deux méthodes ? Et quels sont les avantages du reverse ETL ? Les réponses sont dans cet article.
Lire la suite -
CATIA : tout savoir sur le logiciel de CAO 3D de Dassault Systemes
CATIA (Computer-Aided Three-dimension Interactive Application) est un logiciel créé par Dassault Systemes pour la conception, la modélisation et l’analyse de produits complexes. Il est utilisé par des ingénieurs, des designers et des professionnels de divers secteurs industriels du monde entier. Découvrez tout ce qu’il faut savoir !
Lire la suite -
L’apprentissage semi-supervisé : Tout savoir ce qu’il faut savoir
L’apprentissage semi-supervisé est une technique d’apprentissage automatique qui utilise à la fois des données labellisées et des données non labellisées. Découvrez ci-dessous comment fonctionne cette méthode d’apprentissage.
Lire la suite -
OpenGL : Tour savoir de cette technologie graphique
Programmer une application graphique est fortement simplifié si l’on passe par OpenGL, car alors, vous pouvez disposer d’un programme à même de fonctionner sur des plate-formes très diverses, à défaut d’être optimisé pour chacune d’elles. Comment fonctionne OpenGL et comment peut-on exploiter ses potentiels ?
Lire la suite -
Comparatif des principales bibliothèques Python pour la dataviz
La visualisation de données joue un rôle essentiel dans l’analyse et la communication des informations : en effet elle permet d’avoir un premier aperçu sur nos données et leur composition de façon facilement exploitable et interprétable.
Lire la suite











The newsletter of the future
Get a glimpse of the future straight to your inbox. Subscribe to discover tomorrow’s tech trends, exclusive tips, and offers just for our community.



