
Des chercheurs de Yale et d’IBM ont dévoilé un nouveau cadre pour décoder ce que les modèles d’intelligence artificielle « comprennent » réellement du monde, selon une étude publiée dans Nature Machine Intelligence. L’approche, développée par Jonathan Warrell et ses collègues, applique des principes de philosophie des sciences pour analyser de manière systématique la façon dont les systèmes d’IA créent des représentations internes de concepts du monde réel, une étape essentielle pour rendre ces technologies puissantes mais opaques plus interprétables.
Cette avancée survient alors que les systèmes d’IA influencent de plus en plus de décisions cruciales en médecine et santé, où comprendre comment les modèles parviennent à leurs conclusions peut devenir une question de vie ou de mort. L’équipe, dirigée par Jonathan Warrell de NEC Laboratories America et de l’Université Yale, avec les co-premiers auteurs Michael Gancz de l’Université Stanford et Hussein Mohsen de l’Université de Toronto, a développé ce qu’elle nomme un cadre de « sémantique des modèles ».
Contrairement aux méthodes d’interprétabilité existantes qui se concentrent sur des techniques individuelles, ce cadre fournit une structure complète pour analyser la manière dont les modèles d’IA se rapportent aux phénomènes du monde réel. Il adapte des concepts formels de la philosophie des sciences afin d’évaluer systématiquement ce que les systèmes d’apprentissage profond ont réellement appris à partir de toutes leurs données d’entraînement.
« Le cadre va au-delà des méthodes d’interprétabilité actuelles en les traitant comme un simple composant de la structure sémantique globale d’un modèle », selon l’étude publiée dans Nature Machine Intelligence. L’approche déconstruit le concept d’interprétabilité en composants sémantiques formellement définis, permettant aux chercheurs de mieux comprendre les significations implicites au sein des systèmes d’IA.
Décortiquer la boîte noire
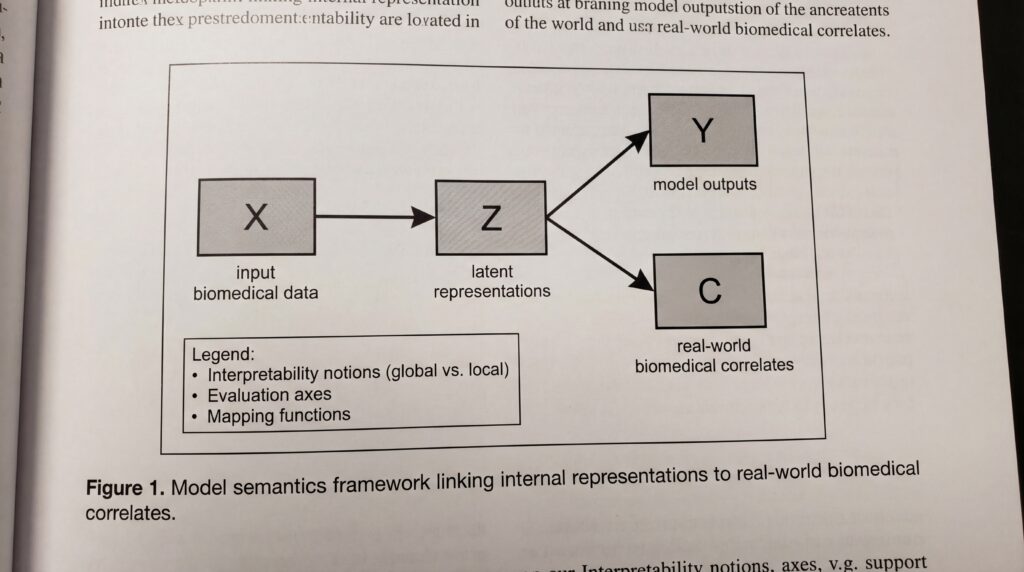
Le cadre de la sémantique des modèles répond au défi fondamental de l’IA : déterminer ce que les réseaux de neurones « savent » réellement du monde qu’ils modélisent. En biomédecine, où l’IA assiste de plus en plus le diagnostic, la découverte de médicaments et la planification des traitements, cette compréhension est cruciale pour garantir la sécurité et la fiabilité.
L’équipe de recherche, qui comprend également Prashant Emani et Mark Gerstein des départements de Biophysique moléculaire et Biochimie, d’Informatique, et de Statistiques et Data Science de Yale, souligne que son objectif n’est pas de créer de nouvelles méthodes d’interprétabilité, mais de fournir une structure formelle pour analyser celles qui existent déjà.
En s’inspirant de la philosophie des sciences, où la sémantique des modèles renvoie à la manière dont les modèles scientifiques représentent des phénomènes du monde réel, le cadre propose une façon systématique de révéler et d’évaluer les corrélats réels des représentations internes d’un modèle. Ce socle théorique pourrait s’avérer particulièrement précieux pour les applications biomédicales, où la compréhension des décisions des modèles peut avoir un impact direct sur la prise en charge des patients.
Cette publication constitue une avancée théorique significative pour rendre l’IA plus transparente et digne de confiance, même si toutes les implications pratiques pour les applications biomédicales nécessitent encore des analyses approfondies à mesure que la méthodologie intégrale sera mise à la disposition de la communauté des chercheurs au sens large.
Sources
- doi.org



