
Des chercheurs du MIT et de l’Université polytechnique de Milan ont mis au point une nouvelle technique qui amène les systèmes d’intelligence artificielle à expliquer leurs décisions en découvrant et en étiquetant automatiquement les concepts qu’ils utilisent pour faire des prédictions. Le modèle mécaniste goulot conceptuel, présenté à l’International Conference on Learning Representations, transforme des modèles d’IA « boîte noire » en systèmes plus transparents qui atteignent une exactitude supérieure à celle des méthodes d’IA explicable précédentes, tout en fournissant un raisonnement plus clair pour leurs résultats.
Cette avancée répond à un défi crucial pour le déploiement de l’IA dans des applications sensibles où comprendre la logique qui sous-tend les prédictions peut être aussi important que l’exactitude elle-même. L’approche de l’équipe de recherche réinvente fondamentalement la façon dont les systèmes d’IA génèrent des explications en extrayant les concepts directement des modèles eux-mêmes plutôt qu’en s’appuyant sur des catégories définies par des humains, selon l’article publié à ICLR 2026.
Comment fonctionne la technologie
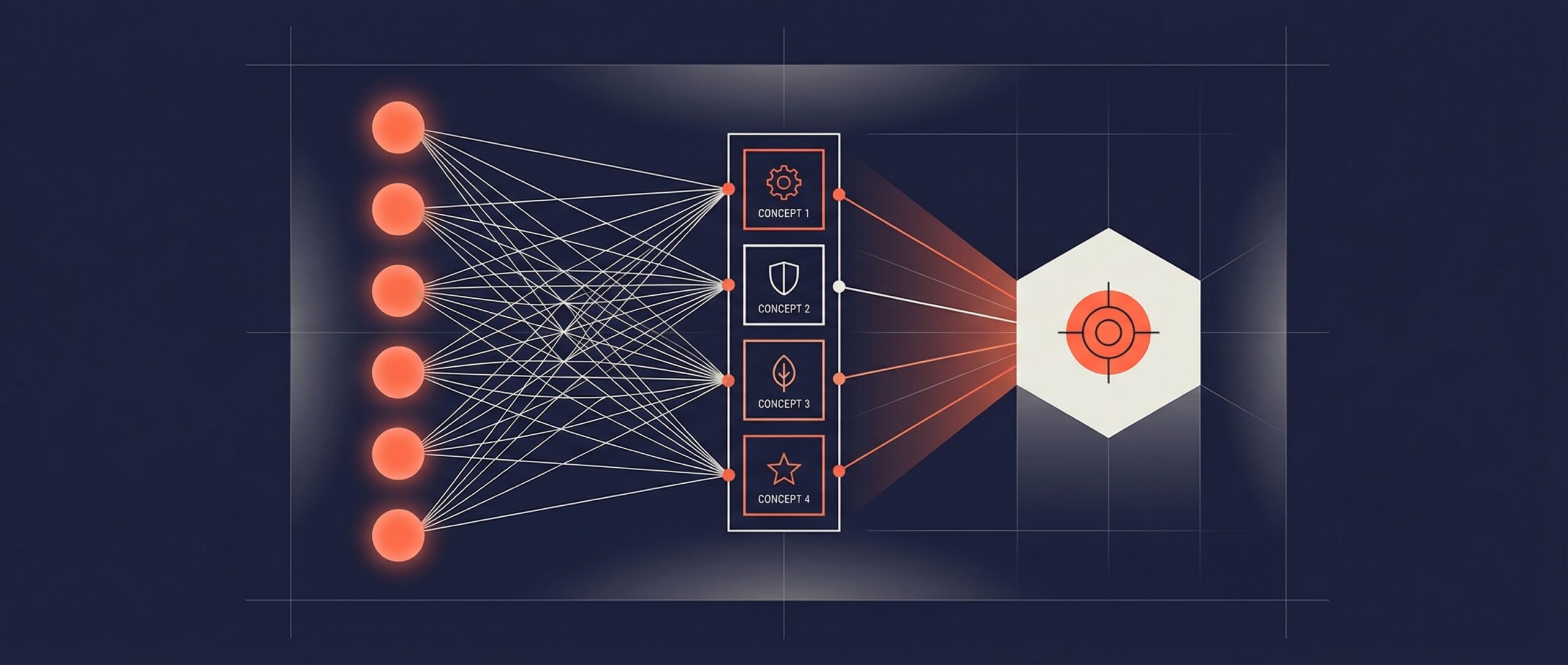
Le M-CBM emploie un processus en trois étapes pour transformer des modèles d’IA opaques en systèmes interprétables. Premièrement, un modèle d’apprentissage profond très spécialisé appelé auto-encodeur parcimonieux analyse les caractéristiques internes de modèles pré-entraînés afin d’identifier les motifs les plus importants utilisés pour les prédictions, comme détaillé par MIT News.
Ensuite, un grand modèle linguistique multimodal décrit automatiquement ces concepts découverts par la machine en langage naturel, tels que « points bruns regroupés » ou « pigmentation variée », et annote en conséquence des jeux de données d’images entiers. Enfin, le système entraîne un « module goulot conceptuel » qui contraint le modèle à fonder ses prédictions exclusivement sur ces concepts extraits et étiquetés, chaque décision n’utilisant que les cinq concepts les plus pertinents afin d’assurer la clarté.
Cette approche élimine les « fuites d’informations », problème courant où les modèles s’appuient secrètement sur des informations allant au-delà de leur raisonnement déclaré, rendant les explications plus fidèles au véritable processus de décision, selon les chercheurs.
Performances et compromis
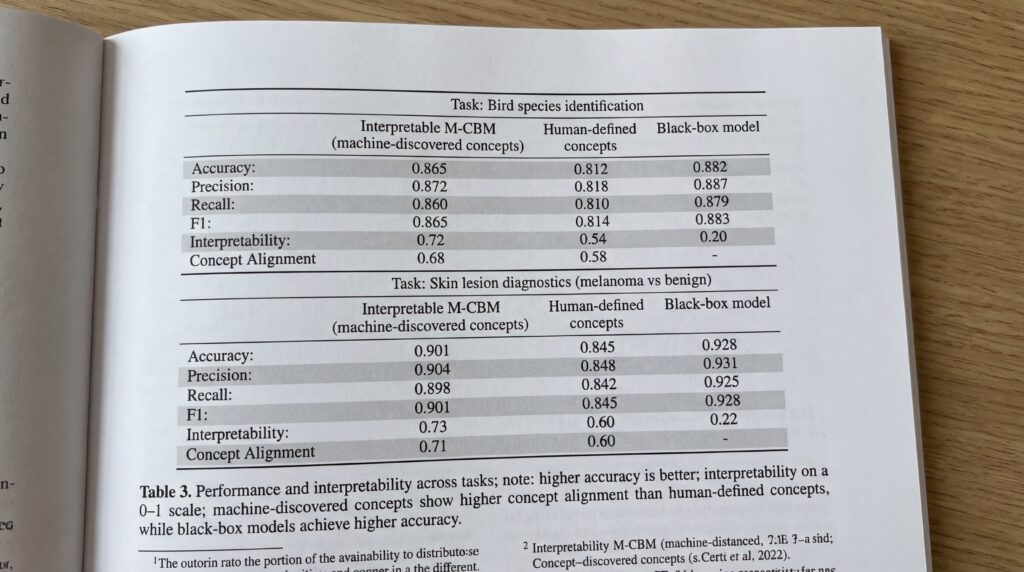
Des tests menés sur l’identification des espèces d’oiseaux et le diagnostic des lésions cutanées ont montré que M-CBM a atteint la meilleure exactitude parmi les modèles d’IA interprétables. Selon l’étude, les concepts découverts par la machine se sont révélés plus directement applicables aux tâches que ceux définis par des humains.
Cependant, les chercheurs reconnaissent un défi persistant. « Les boîtes noires non interprétables surpassent encore les nôtres », ont-ils noté, soulignant la tension persistante entre l’explicabilité et la puissance prédictive brute. Cela signifie que les cliniciens pourraient devoir choisir entre un modèle opaque plus précis et un M-CBM légèrement moins précis qui peut expliquer son raisonnement lors du diagnostic de mélanomes potentiels.
À l’avenir, l’équipe prévoit de mettre l’approche à l’échelle en utilisant des LLM multimodaux plus grands et de développer des méthodes réduisant davantage les fuites d’informations. Les travaux établissent « un pont naturel vers l’IA symbolique et les graphes de connaissances », laissant entrevoir un potentiel de création de systèmes d’IA plus structurés et plus robustes, particulièrement précieux pour la santé, la finance et d’autres secteurs nécessitant une prise de décision transparente.
Sources
- news.mit.edu












