
Decoded©
-
« Type de Données » : Une notion indispensable en Data Science
<strong>Les types de données ou Data Types permettent aux ordinateurs de comprendre comment interpréter les données et sous quelle forme les stocker. Il s’agit d’une notion essentielle pour le stockage et l’analyse de données, pour le Data Management et la Data Science. Découvrez tout ce que vous devez savoir.</strong>
Lire la suite -
Modern data stack : Qu’est-ce que c’est ?
<strong>Pour rendre les données intelligibles et compréhensibles, les organisations utilisent une multitude d’outils. Mais au fil des ans et de l’évolution des datas, ces technologies ont fortement évolué. C’est pourquoi, on parle aujourd’hui de modern data stack.</strong>
Lire la suite -
Régression linéaire multiple : Qu’est-ce que c’est ? À quoi ça sert ?
<strong>Plutôt que d’expliquer les relations entre deux variables, la régression linéaire multiple établit des relations entre une variable et plusieurs variables explicatives. Cette approche multidimensionnelle permet d’approfondir davantage les liens entre différents jeux de données, tout en réduisant le risque d’erreur d’interprétation. Découvrez plus en détail le modèle de régression linéaire multiple, ses traductions mathématiques et ses avantages.</strong>
Lire la suite -
La fonction de coût en IA : Tout ce qu’il faut savoir
<strong>Si l’erreur est humaine, elle n’est pas exclusive à l’Homme. Les algorithmes d’apprentissage automatique peuvent aussi faire des erreurs. Mais à la différence de nous, pauvres humains, il est possible de minimiser. Notamment en utilisant la fonction de coût qui permet d’évaluer la performance d’un modèle de machine learning. Alors de quoi s’agit-il exactement? Et comment l’utiliser ? Data Scientest répond à vos questions. </strong>
Lire la suite -
Kaggle : Tout ce qu’il faut savoir sur cette plateforme
<strong>Si vous pratiquez les data sciences depuis quelque temps vous avez sûrement entendu parler de Kaggle. Et ce n’est pas le cas, cela ne va pas tarder. Nous allons ensemble voir ce qu’est Kaggle et pourquoi cet outil est devenu un indispensable du monde des Data Science !</strong>
Lire la suite -
Nightshade : l’outil de défense des artistes contre les IA génératives
<strong>Nightshade, développé par des chercheurs de l’université de Chicago, représente une avancée majeure dans la protection des droits des artistes à l’ère numérique. Cet outil innovant vise à sauvegarder la propriété intellectuelle des créateurs en altérant les pixels des images pour prévenir leur exploitation abusive par des intelligences artificielles génératives.</strong>
Lire la suite -
Comment déterminer la primitive d’une fonction ?
<strong>Le calcul d’intégrales intervient régulièrement en mathématiques, notamment pour le calcul de probabilités, fondamental pour la data science. Généralement, il est nécessaire de connaître une primitive d’une fonction afin de calculer son intégrale. Dans cet article, vous découvrirez la définition des primitives et comment les déterminer.</strong>
Lire la suite -
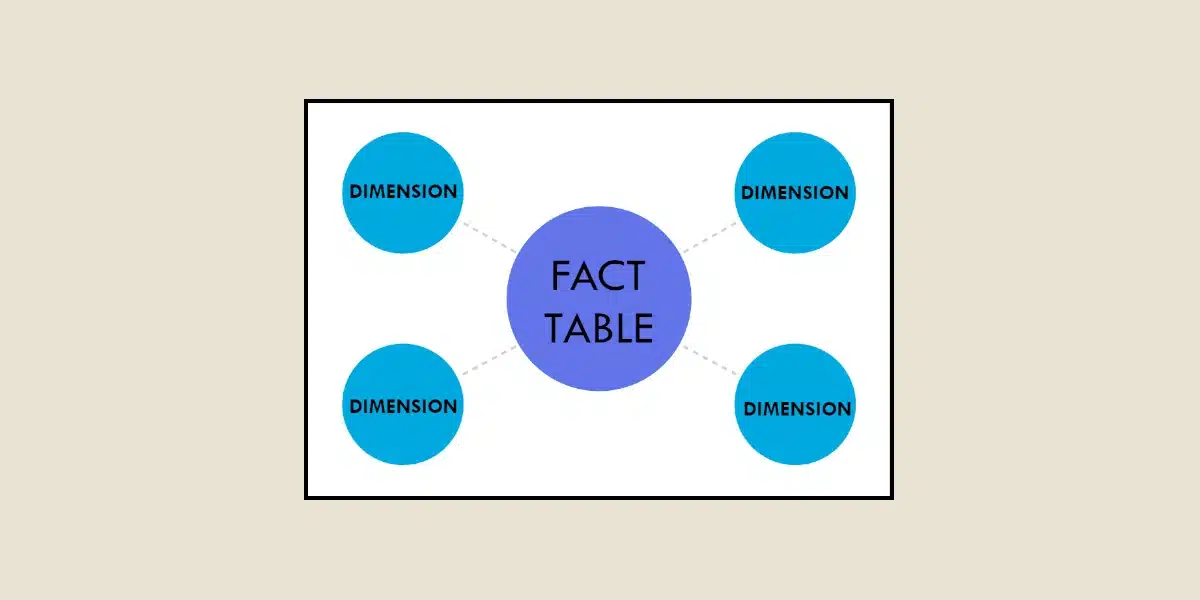
Les tables de dimensions dans un Data Warehouse
<strong>En data science et plus précisément dans les data warehouses, les termes dimension table (table de dimension) et facts table (table de faits) sont des concepts clés dans tout modèle de données, entre autres, à des fins d’analyse.</strong>
Lire la suite -
MlFlow, une plateforme opensource de Machine Learning pour des projets en Data Science optimisés
<strong>Mlflow a été présenté à l’occasion du Spark+AI Summit 2018. Il s’agit d’une plateforme open source développée par Databricks permettant de gérer le cycle de vie des modèles de Machine Learning.</strong>
Lire la suite -
Google Gemini : qu’est-ce que c’est ?
<strong>Depuis l’apparition de GPT 3.5, les progrès autour de l’intelligence artificielle se sont décuplés. Chaque semaine, de nouvelles applications ou algorithmes voient le jour et les grandes entreprises s’engouffrent dans une course à la performance.</strong>
Lire la suite -
PyGTK : l’outil de création d’interface graphique en Python
<strong>PyGTK est un module Python permettant de créer une interface utilisateur graphique (GUI) pour une application. Découvrez tout ce que vous devez savoir sur cet outil et son successeur PyGObject : fonctionnement, avantages et inconvénients, formations…</strong>
Lire la suite -
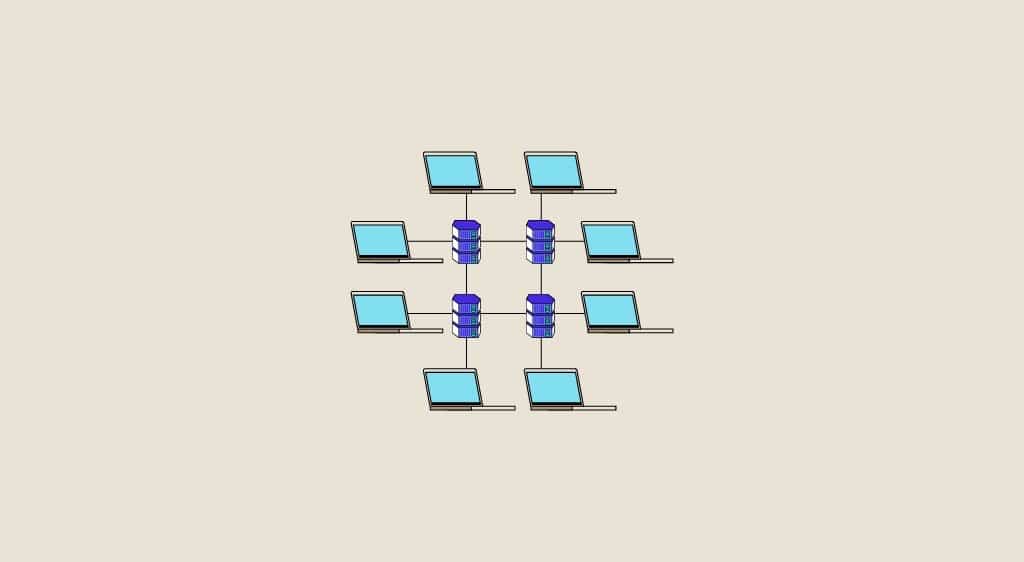
Une architecture distribuée : définition, sa relation avec le Big Data
<strong>Les architectures distribuées sont des systèmes d’informations distribuant et utilisant des ressources disponibles qui ne se trouvent pas au même endroit ou sur la même machine. Dans cet article nous allons expliquer en détail ce que sont ces architectures, nous verrons donc leur avantage par rapport aux autres architectures et comment on les utilise en pratique en Data Science.</strong>
Lire la suite








The newsletter of the future
Get a glimpse of the future straight to your inbox. Subscribe to discover tomorrow’s tech trends, exclusive tips, and offers just for our community.
