
Tous ses articles
-
Le Big Data pour les Nuls
Le Big Data désigne les ressources dont les caractéristiques en termes de volume, de vélocité et de variété imposent l’utilisation de technologie et de méthodes analytiques particulières pour générer de la valeur. Découvrez tout ce qu’il y a à savoir au sujet du Big Data.
Lire la suite -
Data Architecture : définition et importance en data science
La Data Architecture englobe toutes les pratiques et les règles d’une entreprise autour de l’utilisation des données. Découvrez tout ce que vous devez savoir à ce sujet : définition, principes, frameworks, formations.
Lire la suite -
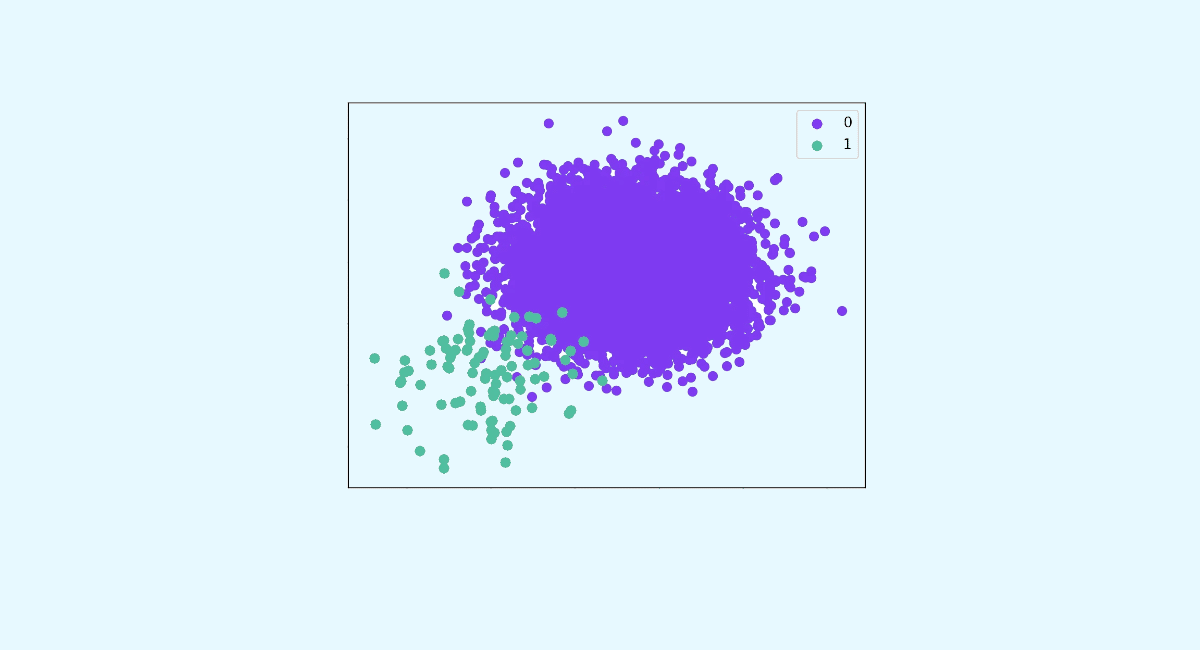
Gestion des problèmes de Classification déséquilibrée – Partie I
Comment gérer les problèmes de Classification déséquilibrée ? Partie I La classification sur données déséquilibrées est un problème de classification où l’échantillon d’apprentissage contient une forte disparité entre les classes à prédire. Ce problème revient fréquemment dans les problèmes de classification binaire, et notamment la détection d’anomalies. Cet article sera divisé en deux parties : […]
Lire la suite -
Requêtes SQL : Les 5 commandes principales à connaître
Pour communiquer avec les bases de données, les développeurs ou data analysts utilisent largement le langage SQL (Structured Query Language). Grâce à ces différentes commandes, il est possible de manipuler les tables en toute simplicité. Alors quelles sont les principales requêtes SQL et à quoi servent-elles ? Découvrez les réponses.
Lire la suite -
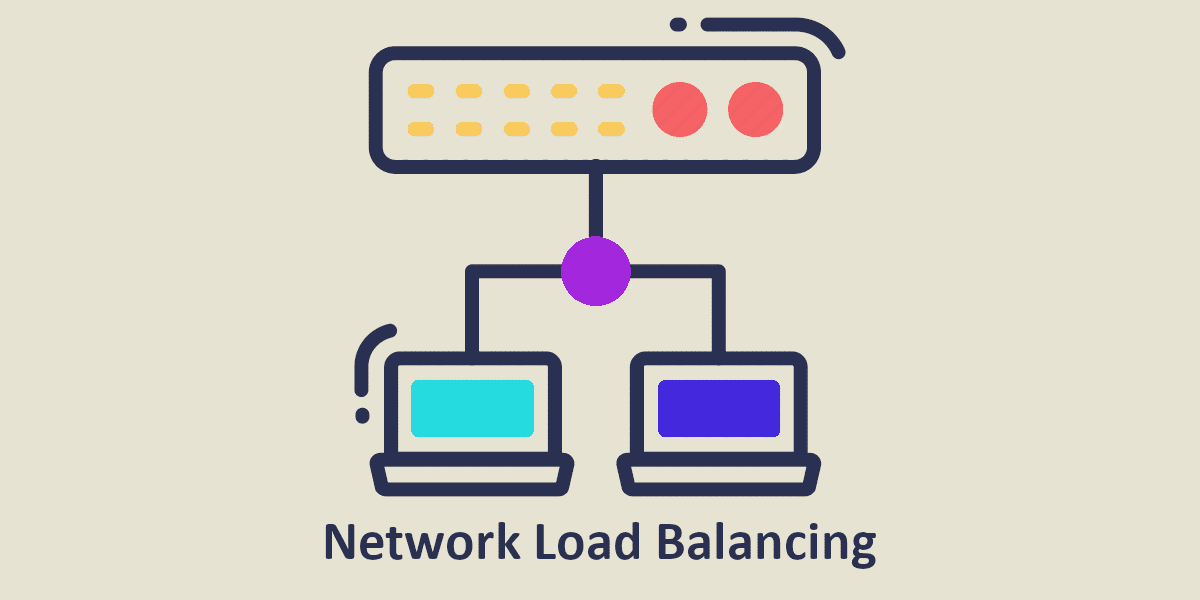
Network Load Balancing (NBL) : Qu’est-ce que c’est ? À quoi ça sert ?
Qu’est ce que le Network Load Balancing (NLB) ? Lorsque vous naviguez sur Internet, il y a tout un processus sous-jacent entièrement transparent pour vous. Ce processus est responsable de l’acheminement de vos requêtes (recherches par exemple) vers le serveur distant – situé potentiellement à l’autre bout du monde – hébergeant le site web. La […]
Lire la suite -
Qu’est ce qu’un framework ?
C’est un mot que nous rencontrons souvent en informatique, mais de quoi s’agit-il exactement ? Sa simple traduction en cadre de travail n’est pas très significative, mais nous donne l’idée de son utilisation. En effet, un framework nous donne un cadre pour nos projets informatiques, permettant de simplifier leur conception. Nous allons explorer ce concept dans cet article.
Lire la suite -
DataViz : Définition, objectifs et usages
La Data Visualization, souvent appelée « Dataviz », est l’ensemble des techniques qui permettent la transformation visuelle et la synthétisation de données brutes pour les faire parler. Le saviez-vous ? La « Dataviz » est un procédé de transmission de l’information qui remonte à plusieurs siècles. Au XVIIIe siècle, l’ingénieur et économiste William Playfair invente […]
Lire la suite -
Apache Pig : tout savoir sur le langage de programmation d’Hadoop
Apache Pig est le langage de programmation permettant d’utiliser Hadoop et MapReduce. Découvrez tout ce que vous devez savoir : présentation, cas d’usage, avantage, formations…
Lire la suite -
Formation ServiceNow : pourquoi et comment maîtriser la plateforme cloud de services IT ?
<strong>Une formation ServiceNow est le moyen idéal pour apprendre à maîtriser pleinement cette plateforme cloud de gestion des services IT. Découvrez comment un tel cursus peut apporter une nouvelle corde à votre arc de professionnel de l’informatique !</strong>
Lire la suite -
Liste vs Tuple sur Python : quelles différences ?
<strong>Aujourd’hui, nous allons parler des data structures. Le problème avec les variables est qu’on ne peut y stocker qu’une seule valeur.</strong>
Lire la suite -
Filtrage dans Power Query : Le guide complet
<strong>Le filtrage dans Power Query permet de filtrer les données en fonction de conditions spécifiques sur Excel et Power BI, et peut être intégré à d’autres outils Microsoft pour encore plus de possibilités. Découvrez tout ce que vous devez savoir sur ce processus très utile pour l’analyse de données !</strong>
Lire la suite -
Missingno : la librairie Python pour les données manquantes
<strong>L’une des étapes les plus importantes d’un projet en Data Science, avant d’entamer la conception des modèles de Machine Learning, est le nettoyage de notre jeu de données. Cela implique la suppression des doublons, l’encodage de certaines variables, mais aussi et surtout le remplacement des valeurs manquantes.</strong>
Lire la suite










The newsletter of the future
Get a glimpse of the future straight to your inbox. Subscribe to discover tomorrow’s tech trends, exclusive tips, and offers just for our community.



