
Tous ses articles
-
Data Control Language (DCL) : Qu’est-ce que c’est ?
Dans le domaine des bases de données, il est tout aussi essentiel de gérer les droits d’accès que de stocker et de manipuler les données elles-mêmes. Il est primordial de veiller à ce que seules les personnes autorisées puissent accéder ou modifier des données confidentielles.Pour ce faire, le Langage de Contrôle des Données ou DCL occupe une place primordiale. Le DCL (Structured Query Language) est un sous-ensemble du langage SQL qui permet de gérer les autorisations et les accès aux données dans une base de données relationnelle.
Lire la suite -
Data Coding Scheme : tout savoir les schémas de codage de données
Le Data Coding Scheme permet de structurer les données, pour qu’elles puissent être interprétées par les systèmes informatiques. Découvrez son rôle clé pour le stockage et la transmission, et ses nombreuses applications !
Lire la suite -
Docker Hub : tout savoir sur la plateforme de stockage d’images Docker
Docker Hub permet de centraliser la gestion des conteneurs et de simplifier leur distribution. Grâce à cette plateforme, les équipes DevOps peuvent accéder facilement aux images de conteneurs, les personnaliser, les mettre à jour et les partager pour une meilleure collaboration. Découvrez ses fonctionnalités, ses avantages et pourquoi il s’agit d’un outil fondamental pour les développeurs d’applications conteneurisées !
Lire la suite -
Data Manipulation Language (DML) : Qu’est-ce que c’est ?
Dans le monde de la gestion des données, le SQL reste un pilier incontournable. Et au cœur de ce langage se trouve le DML, un ensemble d’instructions destinées aux professionnels ayant pour mission d’exploiter cette denrée précieuse qu’est l’information.
Lire la suite -
Golang vs Python : différences et points communs entre ces deux langages
Lorsque l’on parle de programmation pour les projets de science des données, deux langages viennent souvent à l’esprit : Go (ou Golang) et Python. Ce sont des choix populaires parmi les développeurs et les data scientists, mais ils ont des caractéristiques très différentes.
Lire la suite -
Data Mashup : Qu’est-ce que c’est ? Comment ça marche ?
Le « Data Mashup » fait référence au processus d’intégration de données provenant de diverses sources en un seul ensemble cohérent et analysable.
Lire la suite -
Données manquantes : Comment les gérer efficacement en data science ?
Dans le monde réel, les jeux de données parfaitement complets sont l’exception. Que ce soit lors de la saisie manuelle, de l’extraction automatique ou de la fusion de plusieurs sources, les données manquantes sont omniprésentes. Mal gérées, elles peuvent fausser les analyses, réduire la performance des modèles et introduire des biais importants.
Lire la suite -
Emplois en Data Science : quelles compétences techniques et non techniques recherchent les recruteurs ?
Lorsqu’un employeur cherche à recruter un Data Scientist, il regarde en premier lieu les expériences et les projets auxquels le candidat a participé. Mais dans un second temps, il observe les différentes compétences développées au cours de sa formation et de sa carrière. Les recruteurs portent leur attention sur les compétences techniques comme les langages de programmation ou les infrastructures cloud maîtrisées, mais aussi sur les compétences non techniques (aussi appelées soft skills). Alors, quelles sont les compétences techniques et non techniques recherchées par les employeurs ? La Data News vous répond.
Lire la suite -
Formation LLMOps : devenez expert en applications IA basées sur les LLM
Une formation LLMOps vous permettra d’acquérir toutes les compétences requises pour construire des applications basées sur les modèles d’intelligence artificielle de type LLM (Larges Modèles de Langage) et à les mettre en production ! Découvrez tout ce qu’il faut savoir…
Lire la suite -
Ingénieur DataOps : Ficher métier complète
Pour les entreprises souhaitant rester compétitives, une gestion efficace des données est impérative. Aujourd’hui, de nombreux organismes sont à la recherche de personnes capables de maîtriser ces techniques de gestion, de traitement et d’optimisation des données. En d’autres termes, ces organismes sont à la recherche d’ingénieurs Dataops.
Lire la suite -
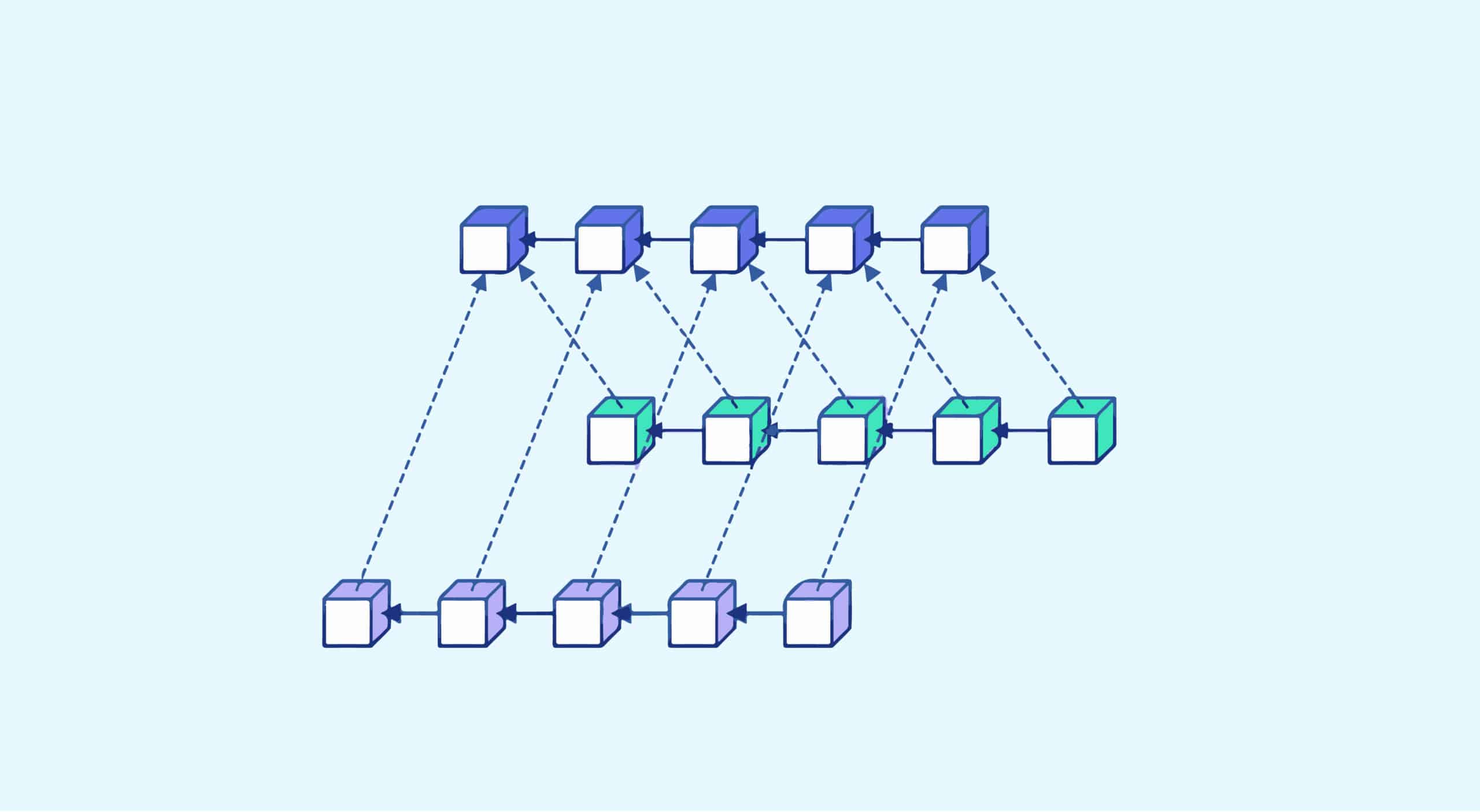
Sharding : définition, utilisation, avantages et inconvénients
Le mot « sharding » signifie « éclater » en anglais. Dans le domaine de la data, le sharding est une méthode qui permet de partitionner un ensemble de données venant d’une même base de données. On fractionne ainsi notre base de données en plusieurs sous-ensembles de données également appelées « datasets ».
Lire la suite -
4 types de biais statistique à éviter dans vos analyses
Le biais statistique peut être défini comme tout ce qui conduit à une différence systématique entre les vrais paramètres d’une population et les statistiques utilisées pour estimer ces paramètres. Il existe une longue liste de types de biais de statistique.
Lire la suite










The newsletter of the future
Get a glimpse of the future straight to your inbox. Subscribe to discover tomorrow’s tech trends, exclusive tips, and offers just for our community.



