
Decoded©
-
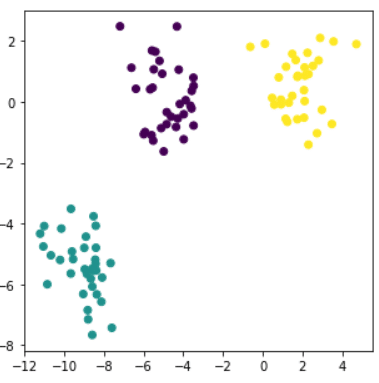
Machine Learning & Clustering : Focus sur l’algorithme CAH
Le clustering est une discipline particulière du Machine Learning ayant pour objectif de séparer vos données en groupes homogènes ayant des caractéristiques communes. C’est un domaine très apprécié en marketing, par exemple, où l’on cherche souvent à segmenter les bases clients pour détecter des comportements particuliers.
Lire la suite -
Modèle SARIMAX : Qu’est-ce que c’est ? Comment l’appliquer aux séries temporelles ?
L’analyse des séries temporelles est une méthodologie cruciale dans de nombreux domaines, tels que la finance, l’économie, la météorologie et la biologie.
Lire la suite -
PL/SQL : Un langage puissant pour la gestion des bases de données Oracle
Dans le domaine des bases de données relationnelles, Oracle se distingue non seulement par la robustesse de ses systèmes de gestion, mais également par les outils avancés qu’il offre aux développeurs pour optimiser, automatiser et sécuriser les opérations sur les données. Au sein de ces outils se trouve PL/SQL (Procedural Language/Structured Query Language), un langage de programmation puissant conçu pour s’intégrer avec SQL, le langage de requête standard pour les bases de données relationnelles.
Lire la suite -
IA Symbolique : Qu’est-ce que c’est ?
L’histoire de l’intelligence artificielle s’est articulée sur deux phases majeures. L’une d’elle a été celle de l’IA symbolique. Que recouvre ce terme mystérieux ? Quels sont les atouts et les limitations d’une telle approche ?
Lire la suite -
TinyML : La révolution de l’IA dans les appareils à faible puissance
Dans un monde où l’intelligence artificielle (IA) devient de plus en plus intégrée dans notre quotidien, une nouvelle frontière se dessine : le Tiny Machine Learning (TinyML). Cette avancée permet de déployer des modèles d’IA sur des appareils à faible puissance et de petite taille, ouvrant ainsi un champ de possibilités inédites.
Lire la suite -
Qu’est ce qu’un dataset ? Comment le manipuler ?
Les datasets (ou jeux de données) sont couramment utilisés en machine learning. Ils regroupent un ensemble de données cohérents qui peuvent se présenter sous différents formats (textes, chiffres, images, vidéos etc…).
Lire la suite -
Computer vision : tout savoir sur cette application du Machine Learning !
Des filtres de Snapchat aux voitures autonomes, en passant par la détection de cancers, la Computer Vision est aujourd’hui partout autour de nous. Elle est aussi efficace qu’elle balaie des domaines variés.
Lire la suite -
Fetch.ai : Fonctionnement, cas d’usage et avenir du projet
Fetch.ai promet une révolution économique sans précédent grâce à un réseau d’agents IA autonomes. Sur le papier, son approche décentralisée pourrait optimiser des secteurs entiers. Pourtant, Fetch.ai n’a pas encore réussi à transformer l’essai. Sa vision d’un vaste écosystème géré par l’intelligence artificielle est judicieuse et devrait tôt ou tard se développer. Le risque étant que des géants comme Google ou Microsoft puissent s’intéresser à le matérialiser eux-mêmes.
Lire la suite -
Data Lake ou Lac de Données : définition et utilisation
Un Data Lake ou lac de données est une plateforme permettant le stockage et l’analyse de données sans contrainte de type ou de structure. Découvrez tout ce que vous devez savoir sur cet outil indispensable pour les Data Scientists : définition, fonctionnement, cas d’usage, formations…
Lire la suite -
Comment faire un graphique sur Excel ?
L’un des moyens les plus efficaces pour représenter des données de manière claire et compréhensible est de créer des diagrammes et des graphiques. Microsoft Excel offre aux utilisateurs de nombreuses possibilités d’analyse. Il est donc possible d’avoir plus de visibilité sur ses données numériques en créant des graphiques sur Excel.
Lire la suite -
Data driven : Définition, avantages, méthodes
À l’ère du Big data, les entreprises collectent des masses de données toujours plus importantes. Mais toutes ne les exploitent pas forcément de manière optimale. Et pourtant, les organisations qui placent les données au cœur de leur stratégie voient généralement leurs performances s’améliorer. Alors quels sont les avantages de l’approche data driven ? Et comment la mettre en place ? C’est ce que nous allons voir dans cet article.
Lire la suite -
Classificateur Naive Bayes : théorie et application
Le classificateur Naive Bayes est une méthode de classification basée sur le théorème de Bayes avec une hypothèse d’indépendance naïve entre les prédicteurs. En dépit de sa simplicité, le classificateur Naive Bayes a prouvé son efficacité dans divers domaines d’application, notamment le filtrage de spam, l’analyse de sentiments et la classification de documents.
Lire la suite









The newsletter of the future
Get a glimpse of the future straight to your inbox. Subscribe to discover tomorrow’s tech trends, exclusive tips, and offers just for our community.
