
Tous ses articles
-
Reverse Prompt Engineer : Qu’est-ce que c’est ? À quoi ça sert ?
<strong>Que ce soit pour créer du contenu sur les réseaux sociaux, rédiger des emails, du code, des fiches produits, réaliser des plans… les grands modèles linguistiques permettent de gagner un temps précieux. À condition bien sûr de savoir rédiger des prompts efficaces.</strong>
Lire la suite -
Top 10 des pré-requis mathématiques importants en Data Science
<strong>Vous avez toujours été bon en mathématiques depuis l’enfance mais n’avez jamais utilisé vos connaissances à part les calculs mentaux ? Vous vous êtes toujours demandé à quoi cela servait de connaître la dérivée d’une fonction, à part assurer une bonne note à votre examen ? Ou êtes-vous tout simplement fasciné par le monde des mathématiques mais n’arrivez pas à en trouver d’applications concrètes, alors cet article est fait pour vous !</strong>
Lire la suite -
Analyse prédictive : Définition et importance en Data Science
<strong>Anticiper les tendances et évaluer les risques d’un marché sont des éléments essentiels de la stratégie d’une entreprise. Comment procèdent-elles ? Quelles sont les techniques utilisées ? Étudions de plus près ce qu’est l’analyse prédictive.</strong>
Lire la suite -
Le Flocking Algorithm ou la simulation des comportements collectifs
<strong>La nature a tant de choses à nous apprendre. D’ailleurs, les data scientists s’en inspirent pour simuler des comportements de masse. Comment ? Grâce au flocking algorithme. Découvrez le fonctionnement de ce modèle, ses cas d’applications et son implémentation avec Python.</strong>
Lire la suite -
Data Designer : tout savoir sur ce métier
<strong>Le Data Designer est un professionnel chargé de créer des visualisations facilement compréhensibles à partir des résultats des analyses de données. Découvrez tout ce que vous devez savoir sur ce métier, ses responsabilités, les compétences requises, et comment les acquérir !</strong>
Lire la suite -
Pie Charts ou « Camemberts » : Comment utiliser ces diagrammes ?
<strong>Les diagrammes en pie chart (plus communément appelés « camembert » dans la langue de Molière) font certainement partie des types de graphiques les plus connus. Ils sont utilisés pour représenter un petit nombre de variables réparties en “part” ou secteurs dont la taille est fonction de la valeur.</strong>
Lire la suite -
MidJourney : l’IA qui transforme vos idées en images
<strong>MidJourney est une IA générative permettant de créer de magnifiques images à partir de simples descriptions textuelles. Découvrez tout ce que vous devez savoir sur cet outil, et comment apprendre à le maîtriser pleinement !</strong>
Lire la suite -
Refactoring de code ou de base de données : tout savoir
<strong>Le refactoring de code est une technique couramment utilisée en programmation informatique, et notamment pour le Data Engineering. Elle consiste à restructurer le code informatique sans modifier son comportement externe ou sa fonctionnalité. Découvrez tout ce que vous devez savoir sur cette méthode : définition, avantages, techniques, formations…</strong>
Lire la suite -
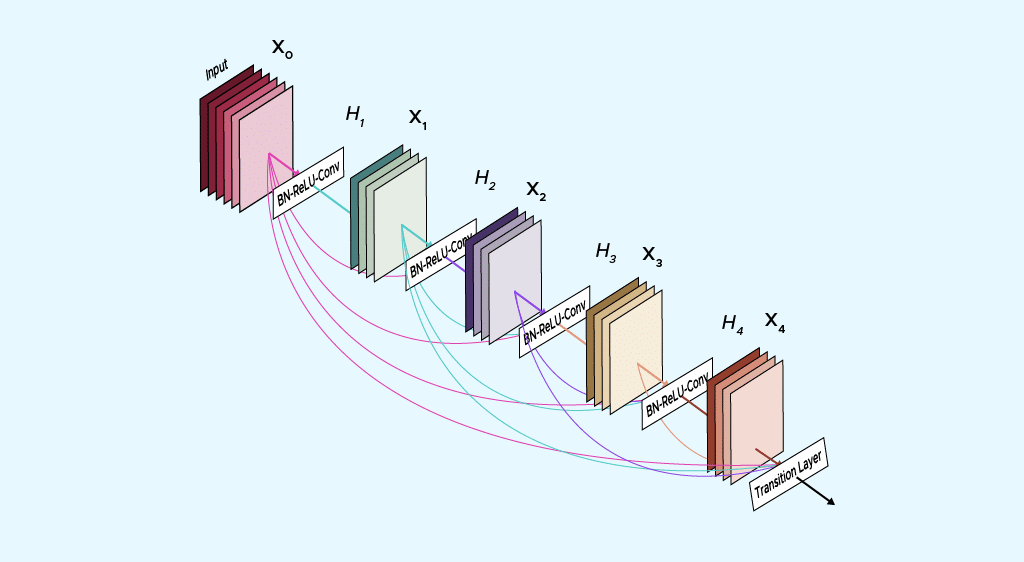
Réseaux de neurones DenseNet : tout ce qu’il y a à savoir
<strong>Vous avez déjà probablement entendu parler des réseaux convolutifs dans les contextes de reconnaissance d’image, de traitement vidéo ou encore dans le ciblage publicitaire et le NLP. Cet article a pour but de délivrer une première approche analytique et une compréhension de l’architecture de ces réseaux, et plus particulièrement sur l’architecture des réseaux DenseNets.</strong>
Lire la suite -
Mariages stables: Principe et cas d’usage sur Parcoursup
<strong>Comment l’algorithme de Parcoursup trouve-t-il des correspondances parfaites entre étudiant.e.s et formations ? Découvrez la théorie des mariages stables derrière cette méthode de sélection et d’affectation.</strong>
Lire la suite -
Natural Language Generation (NLG) : qu’est-ce que c’est ?
<strong>Le Natural Language Generation (NLG) est une technologie d’intelligence artificielle permettant aux machines de créer du texte de manière intelligente et automatisée. Découvrez tout ce qu’il faut savoir sur les différentes techniques et applications existantes, et comment se former pour acquérir une expertise !</strong>
Lire la suite -
Dense neural network : Qu’est-ce que c’est ?
<strong>Au moment de concevoir un réseau neuronal profond, il est possible d’utiliser plusieurs types d’architecture de premier niveau. Parmi lesquels, le dense neural network. Alors de quoi s’agit-il ? Comment ça fonctionne ? Découvrez les réponses dans cet article.</strong>
Lire la suite







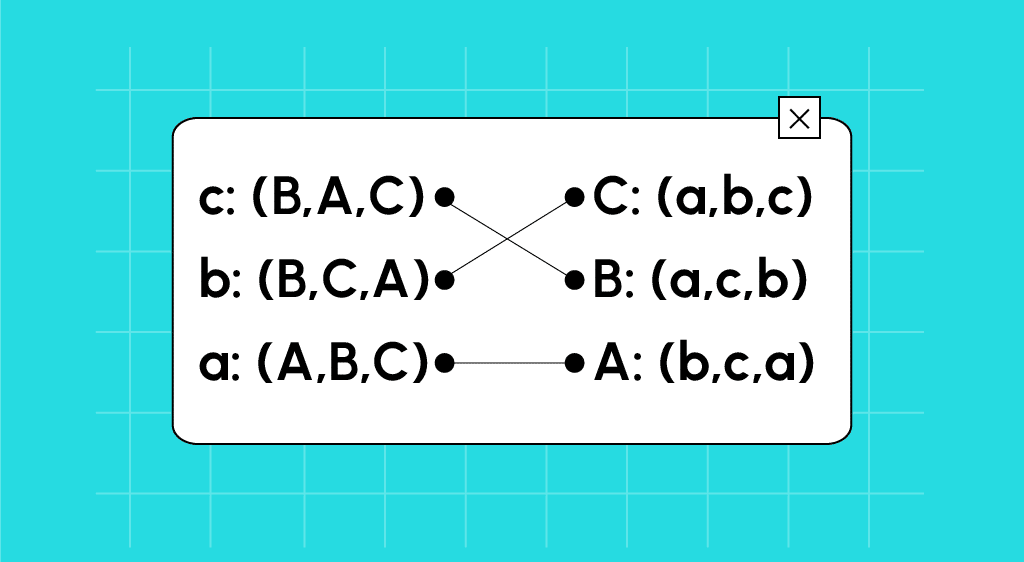

The newsletter of the future
Get a glimpse of the future straight to your inbox. Subscribe to discover tomorrow’s tech trends, exclusive tips, and offers just for our community.



