

Databricks a annoncé la disponibilité générale de Serverless Workspaces pour Microsoft Azure le 13 mars 2026, éliminant la nécessité pour les clients de gérer l’infrastructure cloud lors de l’exécution des workloads Data, Analytique et IA. Le nouveau modèle de déploiement, disponible dans plusieurs régions Azure, permet aux organisations de créer des environnements Databricks en quelques secondes avec redimensionnement automatique et facturation à la seconde, bien qu’il requière Unity Catalog et n’offre aucune option réseau gérée par le client.
Ce nouveau modèle de déploiement représente une évolution fondamentale dans la manière dont les entreprises gèrent l’infrastructure Data, en transférant les ressources de calcul des réseaux virtuels Azure gérés par le client vers un environnement multi-tenant géré par Databricks. Selon le blog Databricks, cette évolution architecturale élimine le besoin de configurer des VNet, d’allouer des plages d’IP ou de gérer des règles de pare-feu et des passerelles NAT.
L’offre serverless prend en charge tous les principaux workloads Databricks, incluant notebooks, workflows, Databricks SQL, Delta Live Tables et Model Serving, le tout propulsé par le moteur Photon haute performance. Le service a été déployé dans 12 régions Azure, dont Australia East, Canada Central, Central US, East US, East US 2, France Central, Germany West Central, North Europe, UK South, West Europe, West US et West US 3.
Structure tarifaire et implications sur les coûts
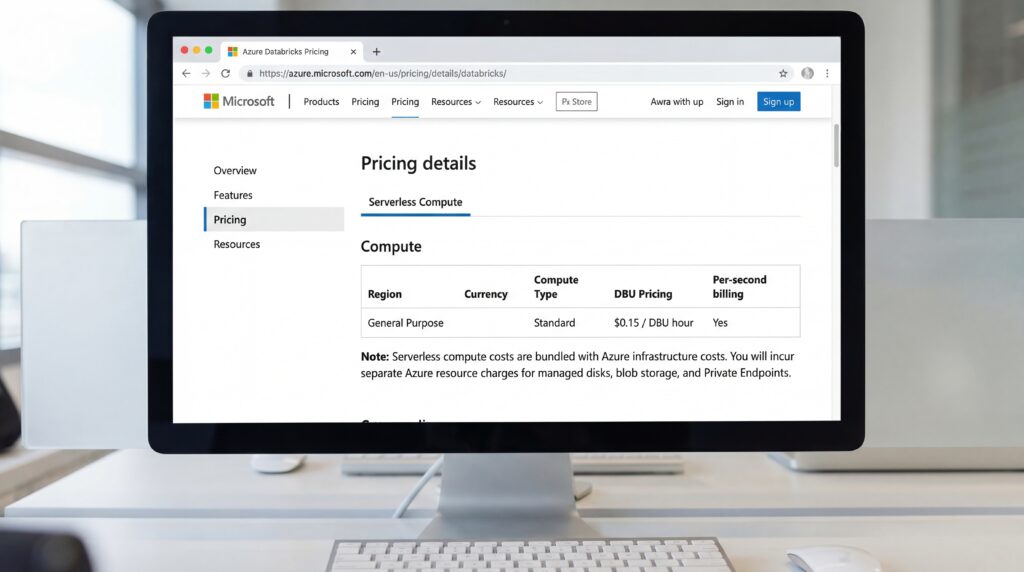
Le modèle économique diffère sensiblement des clusters provisionnés classiques. Les organisations paient un tarif de Databricks Compute Unit (DBU) plus élevé qui inclut les coûts d’infrastructure Azure sous-jacents, éliminant les frais distincts des machines virtuelles, selon la documentation Tarification d’Azure Databricks. La facturation à la seconde garantit que les entreprises ne paient que pour le temps de calcul actif, ce qui peut générer des économies substantielles pour les workloads intermittents.
La documentation Microsoft Learn précise que, bien que les coûts de calcul soient intégrés, les clients demeurent responsables des ressources Azure associées telles que disques gérés, stockage Blob et des composants réseau comme les Private Endpoints. Pour les workloads à la demande variable ou en pics, le modèle serverless pourrait s’avérer plus rentable que le maintien de clusters inactifs.
Limitations techniques et défis de migration
Malgré ses avantages, l’architecture serverless comporte des contraintes notables. Les organisations ne peuvent pas sélectionner des types d’instances VM spécifiques, car Databricks gère automatiquement l’allocation des ressources. L’exigence d’Unity Catalog implique que les entreprises doivent adopter le framework de gouvernance Databricks avant d’accéder aux fonctionnalités serverless.
Point crucial, il n’existe aucun chemin de mise à niveau direct des Workspaces Classic vers Serverless. Selon la documentation Databricks, les organisations doivent redéployer leurs ressources vers de nouveaux environnements serverless, même si Unity Catalog garantit un accès cohérent aux données entre les deux modèles. L’absence d’injection de VNet gérée par le client signifie que les entreprises nécessitant des règles de pare-feu spécifiques ou des connexions locales doivent conserver des Workspaces Classic pour ces workloads.
Ce lancement permet à Databricks de rivaliser sur le marché des plateformes Data Cloud, où l’administration simplifiée et la facturation à l’usage sont devenues des différenciateurs clés. Pour les équipes Data aux prises avec la surcharge d’infrastructure, le modèle serverless promet d’accélérer le Time-to-Value tout en maintenant une sécurité de niveau entreprise grâce à l’intégration Azure Active Directory et aux contrôles d’accès RBAC d’Unity Catalog.
Sources
- databricks.com/blog
- azure.microsoft.com
- learn.microsoft.com



