

NVIDIA et Amazon Web Services ont lancé Nemotron 3 Nano, un modèle d’IA à 30 milliards de paramètres désormais disponible via la plateforme serverless d’Amazon Bedrock. Ce petit modèle de langage utilise une architecture hybride combinant les technologies Mamba et Transformer pour offrir des capacités de codage et de raisonnement de niveau entreprise tout en réduisant les coûts de calcul pour les entreprises développant des applications d’IA spécialisées.
Ce lancement marque une expansion significative de l’empreinte de NVIDIA sur le marché des services d’IA cloud, en s’appuyant sur le déploiement antérieur des modèles Nemotron 2 Nano 9B et 12B sur AWS. Selon le blog AWS Machine Learning, le modèle excelle sur des benchmarks industriels tels que SWE Bench Verified, AIME 2025, et Arena Hard v2 lorsqu’il est comparé à des modèles de taille similaire.
Bien que contenant 30 milliards de paramètres globaux, le modèle active seulement 3,5 milliards de paramètres durant l’exécution grâce à son architecture Mixture-of-Experts, réduisant considérablement les besoins en calcul. Le modèle prend en charge une fenêtre de contexte allant jusqu’à 1 million de tokens, bien que les configurations par défaut puissent varier en fonction des contraintes de mémoire, selon la documentation du modèle NVIDIA.
Positionnement sur le marché et accès entreprise
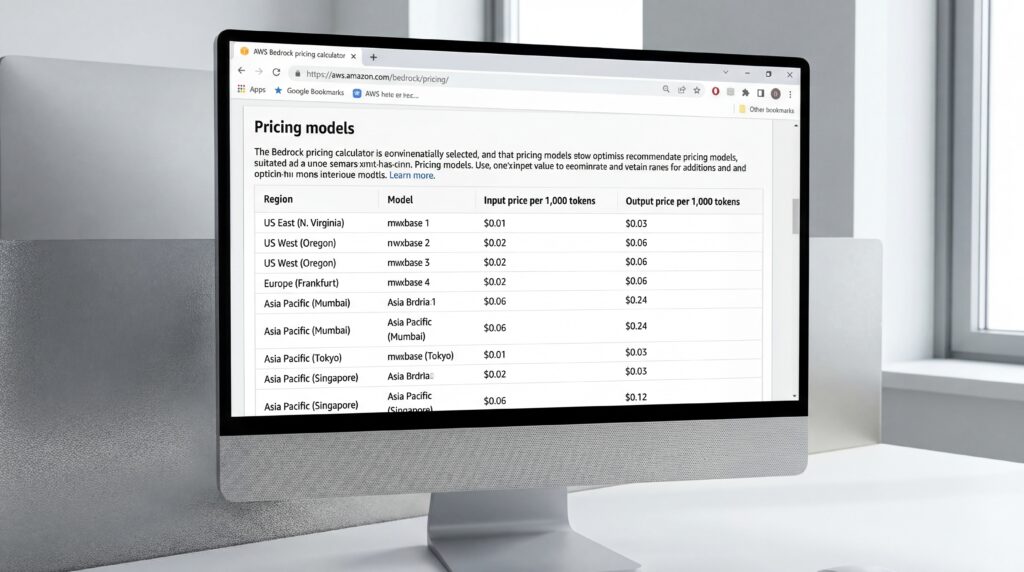
AWS a déployé le modèle dans huit régions mondiales, y compris US East, US West, Asia Pacific, South America et Europe. La mise en œuvre serverless élimine les frais généraux opérationnels et l’investissement MLOps généralement requis pour l’hébergement autonome d’instances GPU, a précisé AWS dans son communiqué.
La tarification suit un modèle de paiement à l’usage, avec des tarifs dans la région Asia Pacific Mumbai fixés à 0,06$ par 1 000 tokens d’entrée et 0,24$ par 1 000 tokens de sortie, selon la page de tarification d’Amazon Bedrock. Cela positionne Nemotron 3 Nano comme une alternative économique face aux modèles concurrents d’Anthropic, Meta et Cohere disponibles sur la plateforme.
L’annonce AWS citait une étude de Artificial Analysis, un cabinet indépendant, pour valider les affirmations concernant la précision et l’efficacité du modèle. Le modèle cible les entreprises clientes qui conçoivent des systèmes d’IA agentifs, des outils de productivité des développeurs et des applications de Retrieval Augmented Generation pour interroger des bases de connaissances internes.
Licence et mise en œuvre technique
NVIDIA distribue Nemotron 3 Nano sous sa Nemotron Open Model License, accordant aux utilisateurs des droits perpétuels, mondiaux, libres de redevances pour la reproduction, la distribution et la création d’œuvres dérivées. La licence exige que les redistributeurs conservent les mentions de droits d’auteur mais fournit le modèle « AS IS » sans garantie, selon la documentation de licence de NVIDIA.
Les développeurs peuvent accéder au modèle via les SDK AWS en utilisant l’identifiant nvidia.nemotron-nano-3-30b. Le modèle fonctionne comme un modèle de langage purement textuel optimisé pour le suivi d’instructions, les chatbots et les workflows légers simultanés gérés par des clusters d’agents d’IA.
Sources
- aws.amazon.com/blogs/machine-learning
- nvidia.com



