

Hugging Face a lancé Storage Buckets le 10 mars 2026, introduisant une solution de stockage d’objets native conçue pour gérer les fichiers de données massifs et fréquemment modifiés, habituels dans les workflows de développement en IA. La nouvelle fonctionnalité, intégrée directement à la plateforme Hugging Face Hub, offre aux développeurs des capacités de stockage de type S3, optimisées pour la gestion des checkpoints de modèles, des logs et des datasets traités, sans les contraintes des systèmes de contrôle de version traditionnels.
Les nouveaux Storage Buckets fonctionnent comme des conteneurs non versionnés au sein des espaces de noms des utilisateurs, ce qui les distingue des dépôts traditionnels fondés sur Git de la plateforme. Selon l’annonce de Hugging Face, le service s’appuie sur Xet, un backend de stockage fondé sur des blocs, qui opère une déduplication axée sur le contenu, en scindant les fichiers en plus petits fragments et en ne conservant que les blocs uniques. Cette architecture profite particulièrement aux clients du plan Enterprise, qui sont facturés en fonction de l’empreinte de stockage dédupliquée plutôt que de la taille brute des fichiers.
La plateforme remédie à un point de friction critique dans les workflows de machine learning, où le modèle de versionnage de Git devient un frein plutôt qu’une aide. Hugging Face a expressément conçu les buckets pour des réécritures et suppressions fréquentes sans créer d’historique de versions, les positionnant comme « la bonne abstraction » pour des artefacts ML mutables par rapport à Git LFS.
Outils pour développeurs et intégration
Les développeurs peuvent interagir avec les Storage Buckets via plusieurs interfaces, y compris la hf CLI avec des commandes pour créer, synchroniser et copier des données. La bibliothèque Python huggingface_hub (version 1.5.0+) et la bibliothèque JavaScript @huggingface/hub (version 2.10.5+) fournissent un accès programmatique, selon la documentation de l’entreprise.
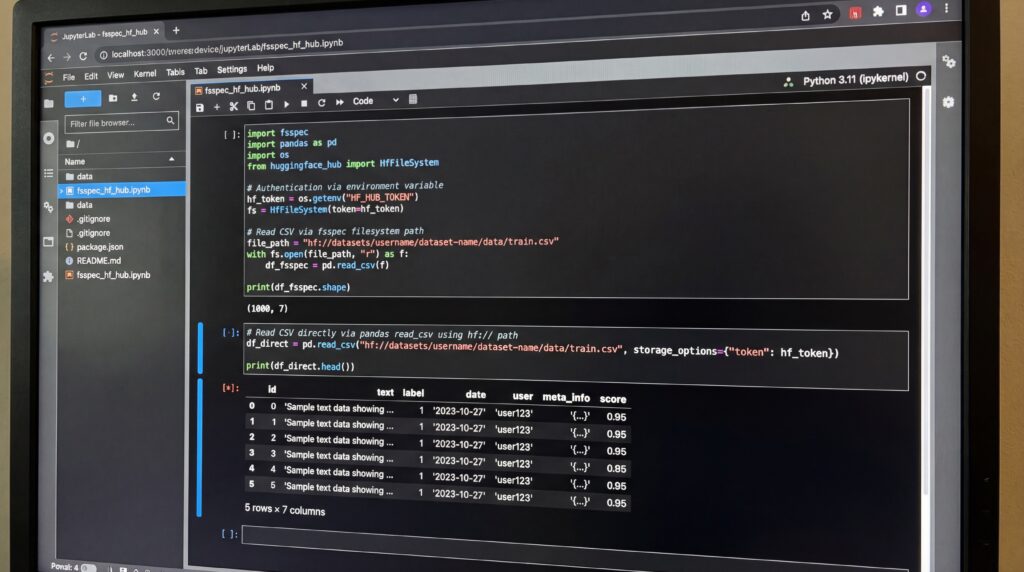
Une innovation technique majeure est la compatibilité fsspec, permettant aux buckets de fonctionner comme un filesystem natif via le protocole hf://. Cette intégration permet aux data scientists de lire directement des fichiers en exploitant des bibliothèques courantes comme Pandas, Polars et Dask sans altérer significativement le code existant.
Le service inclut une fonction « Pre-warming » qui met en cache les données des buckets dans des régions AWS ou GCP spécifiques, réduisant la latence et améliorant le débit pour les opérations d’entraînement distribué en plaçant les données au plus près des ressources de calcul, a précisé Hugging Face.
Positionnement sur le marché
Storage Buckets placent Hugging Face plus directement face aux fournisseurs cloud traditionnels comme AWS S3 et Google Cloud Storage tout en renforçant le verrouillage de son écosystème. L’entreprise envisage un workflow à deux couches: une « working layer » utilisant les Buckets pour des artefacts transitoires et une « publishing layer » avec des dépôts versionnés pour des actifs stables.
La consolidation des actifs de projets ML au sein du Hugging Face Hub élimine la nécessité d’identifiants et de facturation de stockage cloud distincts, réduisant potentiellement la complexité opérationnelle pour les équipes IA. Les éléments futurs de la roadmap incluent la prise en charge de transferts directs entre Buckets et dépôts afin de rationaliser davantage le processus de promotion des actifs.
Sources
- https://huggingface.co/blog



