

Episode 2 : L’escroc Rennais
Hier, un article honteux traitant d’un modèle de prédiction du classement final de ligue 1 vous a été proposé !
Vous aurez évidemment remarqué l’absurdité de ce modèle avec la 10e place du SRFC, actuel détenteur de la Coupe de France, 3e au classement de Ligue 1, qualifié pour les barrages de la LDC (avant application du Fair Play financier) et merveille footballistique en général.
Essayons de voir si nous pouvons construire un modèle de prédiction un peu plus réaliste à l’aide de la Data Science, de données disponibles librement et d’un peu plus de réflexion.
Tout d’abord, nous avons besoin d’un jeu de données comprenant les matchs de la saison en cours (avec leurs résultats pour les matchs passés).
En scrappant un peu, on arrive à un jeu de données intéressant, suffisamment propre et qui nous permettra de construire un modèle pertinent.
Notre modèle va simplement consister à prendre les résultats des matchs aller et de les appliquer au match retour non joué. Par exemple, le 18/08/19, lors de la 2e journée du championnat, le match Rennes-Paris a terminé sur le score de 2-1 en faveur de Rennes (après une ouverture du score de Cavani, M’Baye Niang à la 44e puis Romain Del Castillo à la 48e renverse le cours du match et offre à Rennes la 3e place du classement).
Nous prendrons donc le score de 1-2 pour le match retour Paris-Rennes qui aurait dû être gagné par Rennes lors de la 37e journée à la mi-mai.
Bref, ce modèle nous donnerait le classement suivant :
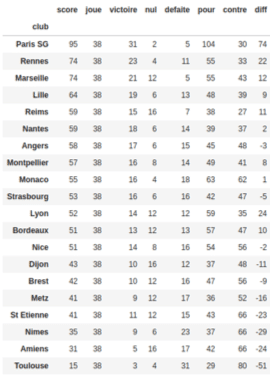
Il paraît tout de suite plus logique même si les premières places ont l’air d’avoir été inversées.
Alors bien sûr Thibault,data scientist chez DataScientest , se plaint de la place de Lyon et du maintien en Ligue 1 de l’ASSE mais c’est un modèle très sommaire…
Mais maintenant que nous avons la matrice pour multiplier les modèles, j’ai bien envie de voir si on peut améliorer le modèle : en intégrant des données sur les joueurs et les saisons passées, en ajoutant un modificateur domicile/visiteur, en prenant la dynamique des équipes sur les derniers matchs…
Ce sera l’occasion de réfléchir à comment créer des modèles de prédiction sans nécessairement utiliser de Machine Learning mais en réfléchissant sur la modélisation de différent phénomènes…
Dans un projet de Data Science, il est important d’avoir un premier modèle, aussi simple soit-il, très rapidement, pour deux raisons :
- créer un cadre pour l’analyse des résultats d’un modèle ou pour la mise en production
- avoir un modèle de base qui sert de minimum à dépasser
Ici, si ce modèle était pertinent, on ne jouerait que la moitié des saisons… Mais il nous permet déjà d’avoir une première approche à un problème bien plus complexe.
Et si jamais la saison reprend on pourra évaluer la précision du modèle mais on se sera amusés à pousser un sujet un peu trivial dans ses retranchements…



