Un peu d’histoire
ImageNet
ImageNet est une gigantesque base de données de plus de 14 millions d’images labellisées réparties dans plus de 1000 classes, en 2014. En 2007, une chercheuse du nom de Fei-Fei Li a commencé à travailler sur l’idée de créer un tel jeu de données. Certes la modélisation est un aspect très important pour obtenir des bonnes performances, mais disposer de données de grande qualité l’est tout autant pour avoir un apprentissage de qualité. Les données ont été collectées et étiquetées depuis le web par des humains. Elles sont donc open source et n’appartiennent pas à une entreprise en particulier. Depuis 2010 s’organise, chaque année, une compétition ImageNet Large Scale Visual Recognition Challenge dont le but est de challenger des modèles de traitement d’images. La compétition s’effectue sur un sous-ensemble d’ImageNet composé de : 1,2 million d’images d’entraînement, 50000 pour validation et 150000 pour tester le modèle.L’architecture
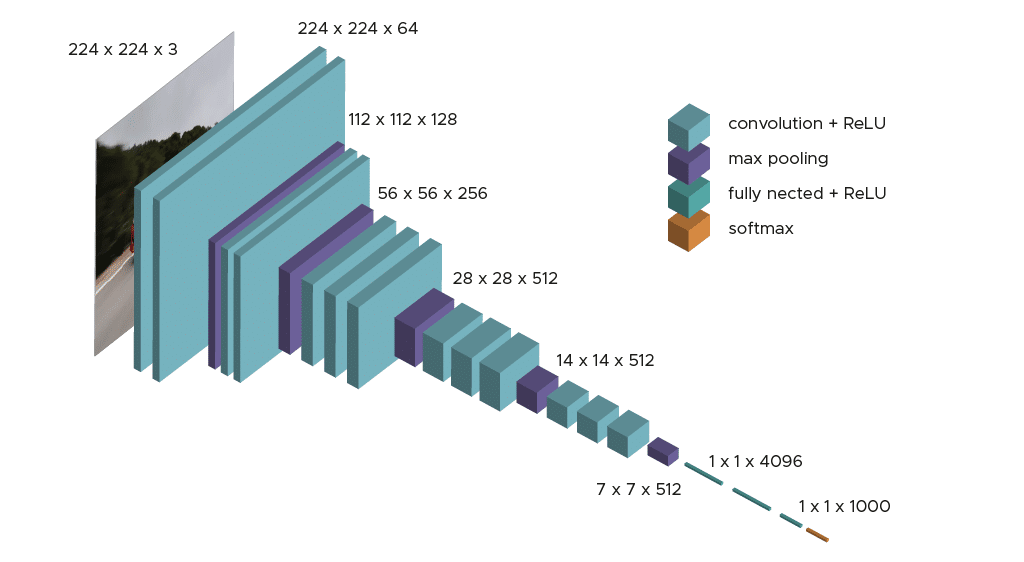
Dans les faits, il existe deux algorithmes disponibles : VGG16 et VGG19. Dans cet article, nous allons nous concentrer sur l’architecture du premier. Si les deux architectures sont très proches et respectent la même logique, VGG19 présente un plus grand nombre de couches de convolution. Le modèle ne demande qu’un prétraitement spécifique qui consiste à soustraire la valeur RGB moyenne, calculée sur l’ensemble d’apprentissage, de chaque pixel. Durant l’apprentissage du modèle, l’input de la première couche de convolution est une image RGB de taille 224 x 224. Pour toutes les couches de convolution, le noyau de convolution est de taille 3×3: la plus petite dimension pour capturer les notions de haut, bas, gauche/droite et centre. C’était une spécificité du modèle au moment de sa publication. Jusqu’à VGG16 beaucoup de modèles s’orientaient vers des noyaux de convolution de plus grande dimension (de taille 11 ou bien de taille 5 par exemple). Rappelons que ces couches ont pour but de filtrer l’image en ne gardant que des informations discriminantes comme des formes géométriques atypiques. Ces couches de convolution s’accompagnent de couche de Max-Pooling, chacune de taille 2×2, pour réduire la taille des filtres au cours de l’apprentissage. En sortie des couches de convolution et pooling, nous avons 3 couches de neurones Fully-Connected. Les deux premières sont composées de 4096 neurones et la dernière de 1000 neurones avec une fonction d’activation softmax pour déterminer la classe de l’image. Comme vous avez pu le constater l’architecture est claire et simple à comprendre ce qui est aussi une force de ce modèle.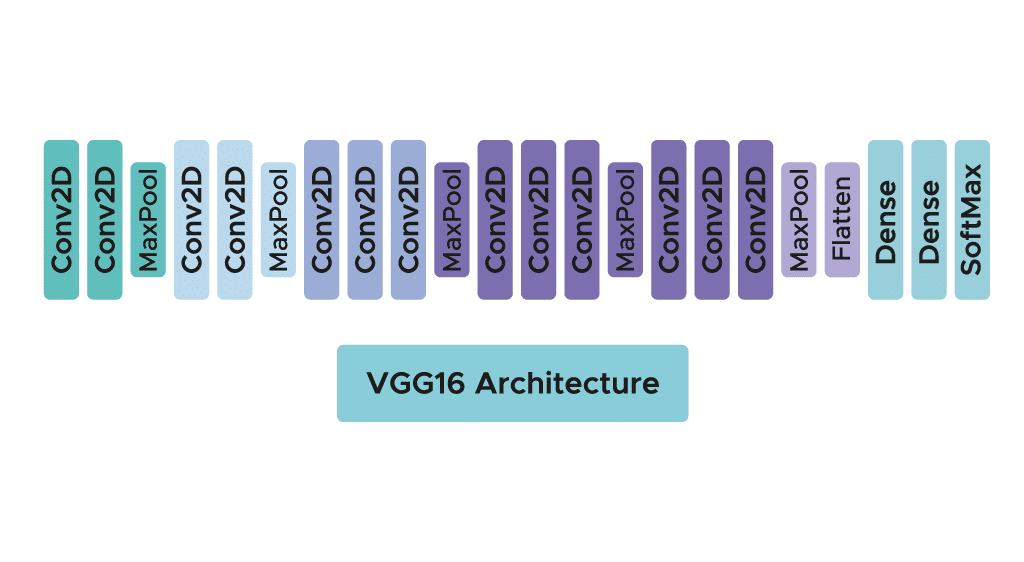
Résultats obtenus sur ImageNet
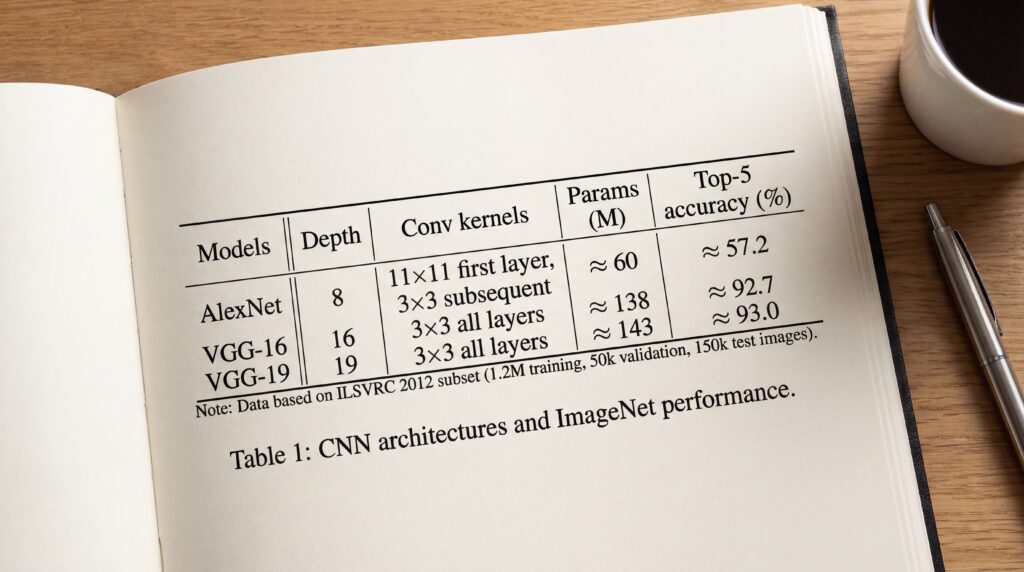
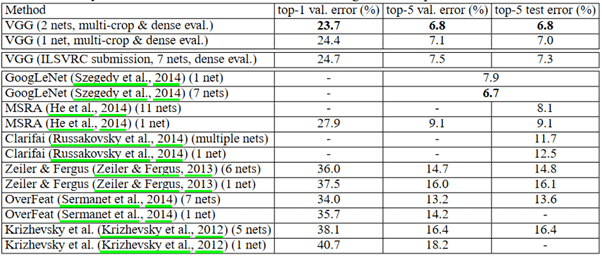 La figure ci-dessus compare les résultats de différents modèles de 2014 ou bien des années précédentes. Nous pouvons voir que VGG donne les meilleurs résultats aussi bien sur le jeu de validation que sur le jeu de test. Remarquons également que le modèle donne de bien meilleurs résultats que lors des sessions 2012 et 2013.
La figure ci-dessus compare les résultats de différents modèles de 2014 ou bien des années précédentes. Nous pouvons voir que VGG donne les meilleurs résultats aussi bien sur le jeu de validation que sur le jeu de test. Remarquons également que le modèle donne de bien meilleurs résultats que lors des sessions 2012 et 2013.
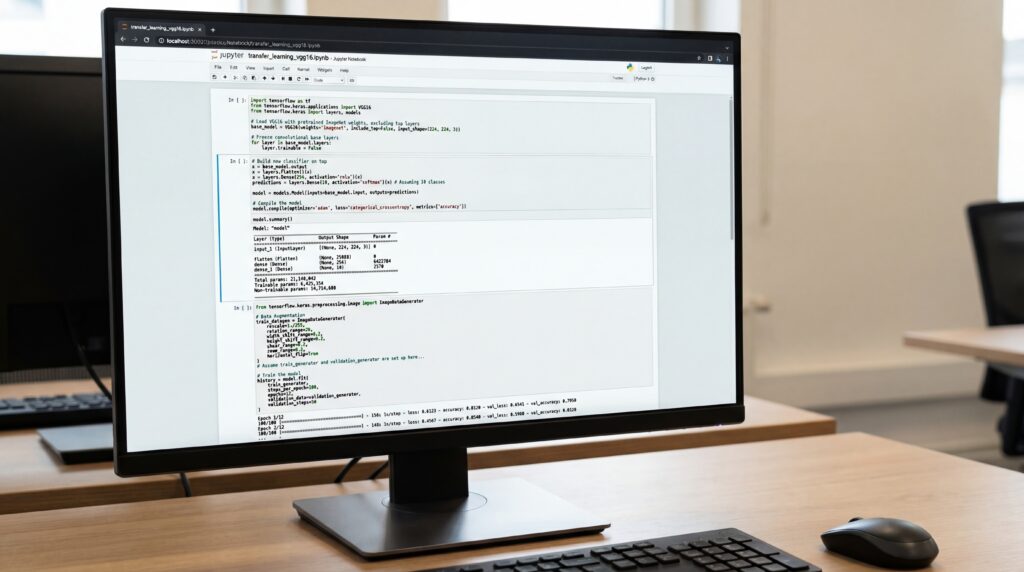
Et le Transfer learning dans tout ça ?