
Decoded©
-
Text Mining: Definition, Techniken, Anwendungsfälle
Text Mining ist die Verwendung von Machine Learning für die Textanalyse. Hier erfährst du alles, was du wissen musst: Definition, Funktionsweise, Techniken, Vorteile, Anwendungsfälle…
Weiterlesen -
Autoencoders – Modelle für unüberwachtes Lernen
Heute beschäftigen wir uns mit einer Familie von nicht überwachten Lernmethoden, dem Autocodierern. Autoencoder : Definition Selbst-Encoder sind besondere neuronale Netze, die genau die gleiche Anzahl an Neuronen auf ihrer Eingabe- und Ausgabeschicht haben. Das Ziel eines Auto-Encoders ist es, eine Ausgabe zu haben, die der Eingabe so nahe wie möglich kommt! Das Lernen ist […]
Weiterlesen -
Relationale Datenbanken: Alles, was man wissen muss
Datenbankverwaltungssysteme (DBMS) sind Computerprogramme, die es den Benutzern ermöglichen, mit einer Datenbank zu interagieren. Dazu muss das DBMS über ein Modell verfügen, das definiert, wie die Daten organisiert werden. Das relationale Modell ist ein sehr beliebter Ansatz zur Organisation von Daten.
Weiterlesen -
Künstliche Intelligenz verstehen: So arbeiten KI-Agenten
Wenn Sprachmodelle wie GPT das Zeitalter der künstlichen Intelligenz durch frei zugängliche Apps wie ChatGPT oder Midjourney eingeleitet haben, stellen Künstliche Intelligenz-Agenten den nächsten Schritt dar. Die KI beantwortet nicht mehr nur unsere Fragen, sondern ist in der Lage, komplexe Aufgaben auf intelligente und hartnäckige Weise zu erledigen…
Weiterlesen -
Staging Area: Was beinhaltet dieser Schritt im ETL-Prozess?
/*! elementor – v3.14.0 – 26-06-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
Weiterlesen -
CTR (Click Through Rate) : Was ist das? Wozu dient sie?
CTR entspricht dem englischen Anagramm des Begriffs „Click through rate„. Im Deutschen heißt die Übersetzung „Klickrate“ (oder TCR). Es handelt sich um einen Leistungsindikator, mit dem die Effektivität einer digitalen Marketingkampagne bewertet werden kann. Dies gilt sowohl für den Inhalt als auch für das Design und die Platzierung (an wen sie gerichtet ist).
Weiterlesen -
AiXBT: Krypto-KI-Agent zwischen Hype, Token und Kritik
Der anfängliche Erfolg von AiXBT ließ vermuten, dass es sich um einen äußerst leistungsfähigen Krypto-KI-Agenten handelt. Zwar hat die anfängliche Begeisterung im Laufe der Monate etwas nachgelassen, doch sie ist weiterhin spürbar. Denn AiXBT hat zweifellos einen Weg geebnet, dem bald weitere Anwendungen folgen dürften.
Weiterlesen -
SQL WHERE Befehl: Ein umfassender Leitfaden
Der SQL WHERE Befehl wird in Abfragen verwendet, um Daten herauszufiltern, die eine bestimmte Bedingung erfüllen. Dadurch können nur die gewünschten Zeilen aus einer Tabelle in einer Datenbank abgerufen werden. Mit diesem Befehl ist es möglich, eine Teilmenge der Daten nach bestimmten Kriterien auszuwählen. Erfahre mehr über die Syntax des WHERE-Befehls in SQL, seine Anwendungsfälle und seine Vergleichsoperatoren, um deine Abfragen effizienter durchzuführen.
Weiterlesen -
CRUD: Definition, Funktionsweise
CRUD ist ein englisches Computerakronym, das eng mit der Verwaltung digitaler Daten verknüpft ist und sich auf die Funktionsweise gespeicherter Daten bezieht. Es umfasst vier grundlegende Operationen, die sich auf die Verwaltung der Relevanz von Daten und Anwendungen beziehen: Create, Read, Update und Delete.
Weiterlesen -
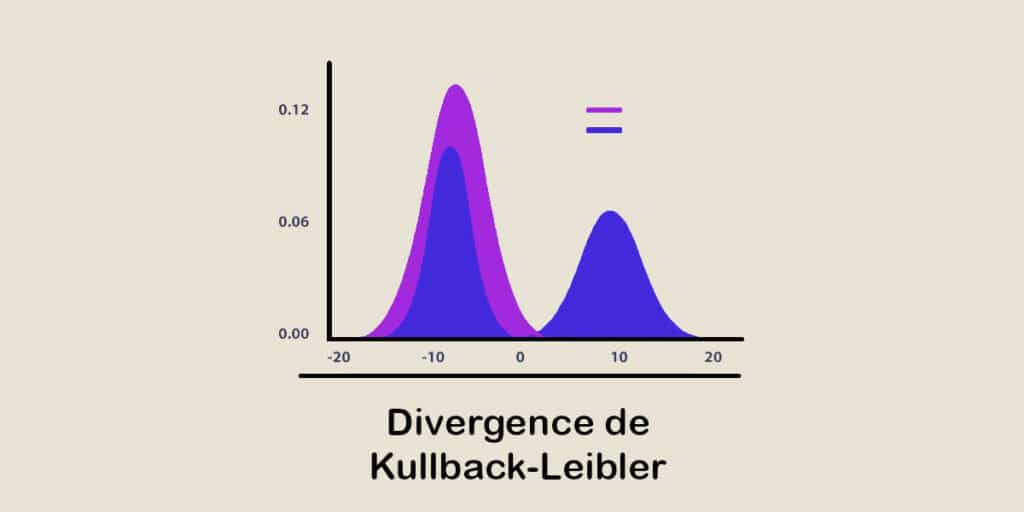
Kullback-Leibler-Divergenz: Ein entscheidendes Ähnlichkeitsmaß in der Data Science
Die Kullback-Leibler-Divergenz ist ein Maß für die Ähnlichkeit zwischen zwei Wahrscheinlichkeitsverteilungen und wird häufig in der Datenanalyse und im Machine Learning verwendet. Finde heraus, was du alles wissen musst!
Weiterlesen -
AKI oder Allgemeine Künstliche Intelligenz: Was ist das?
Für das Beste oder Schlechteste könnte das Auftreten einer autonomen Superintelligenz früher oder später zur Realität werden. Die Konsequenzen für unsere Zivilisation könnten jenseits unserer Vorstellungskraft liegen…
Weiterlesen -
CSV (comma separated values): Alles über dieses zeitlose Format für tabellarische Dateien
/*! elementor – v3.15.0 – 02-08-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
Weiterlesen








The newsletter of the future
Get a glimpse of the future straight to your inbox. Subscribe to discover tomorrow’s tech trends, exclusive tips, and offers just for our community.
