

Bevor ein Machine-Learning-Modell in Produktion gehen kann, muss zunächst das am besten geeignete Modell bestimmt werden, die optimalen Parameter ausgewählt werden usw. Dies sind redundante Vorgänge, die auf verschiedene Projekte angewendet werden. Wäre es nicht einfacher, diese Prozesse zu automatisieren? Hier kommt TPOT ins Spiel.
Was ist TPOT ?
TPOT ist eine Open-Source-Bibliothek, die für die Automatisierung von Machine Learning verwendet wird. Basierend auf der Scikit-learn-Bibliothek, die genetische Programmierung verwendet, untersucht TPOT tausende verschiedener Pipelines und findet diejenige, die für ein bestimmtes Dataset am besten geeignet ist. Angenommen, du hast einen Datensatz, für den die Anwendung eines Machine-Learning-Modells relevant ist. Deine ersten Schritte werden sich um die Erforschung der Daten und ihre Vorbereitung drehen. Der nächste Schritt besteht darin, das beste Machine-Learning-Modell auszuwählen, indem du deine Daten an verschiedene Modelle anpasst und nach dem besten Satz von Hyperparametern suchst. Technisch gesehen wirst du die gleichen Bibliotheken in verschiedenen Projekten verwenden. Das wird dich viel Zeit kosten und nicht unbedingt deine Fähigkeiten verbessern, da du immer wieder denselben Code schreibst.Warum sollte man TPOT verwenden ?
Automatische Machine-Learning-Tools (AutoML) sind die Antwort auf eine einfache Frage: Wie kann man die Erstellung und das Training von Modellen weniger zeitaufwendig gestalten? AutoML ermöglicht es, wie der Name schon sagt, einen Großteil des Prozesses der Modellerstellung zu automatisieren, ohne dabei an Qualität einzubüßen, sodass sich der Data Scientist auf die Analyse konzentrieren kann. Seine Pipeline besteht aus mehreren Prozessen, die es ermöglichen werden, ein leistungsfähiges Machine-Learning-Modell zu erstellen (Feature Engineering, Modellgenerierung, Optimierung der Hyperparameter). Zur Erinnerung: Bei Machine Learning kodifiziert und automatisiert eine Pipeline den Workflow, der es ermöglicht, dass Daten in ein Modell umgewandelt und korreliert werden, das dann analysiert werden kann. Das Laden der Daten in das Modell ist dann vollständig automatisiert. Eine Pipeline kann auch verwendet werden, um den Workflow unseres Modells in unabhängige, wiederverwendbare Teile zu unterteilen, wodurch die Erstellung vereinfacht und Doppelarbeit vermieden wird. Eine gute Pipeline wird die Erstellung und Produktion von Machine-Learning-Modellen effizienter und skalierbarer (skalierbar) machen. Darüber hinaus ist TPOT sehr flexibel, da du es mit PyTorch an Modelle für neuronale Netze anpassen kannst. TPOT unterstützt insbesondere die Verwendung von Dask, um parallele Trainings zu realisieren.Wie funktioniert TPOT ?
TPOT, oder Tree-based Pipeline Optimization, verwendet eine auf binären Entscheidungsbäumen basierende Struktur, um ein Pipeline-Modell darzustellen. Dies beinhaltet die Vorbereitung von Daten, die Modellierung von Algorithmen, die Einstellung von Hyperparametern und die Auswahl des Modells. Nachfolgend ein Beispiel für eine Pipeline, das die von TPOT automatisierten Elemente zeigt: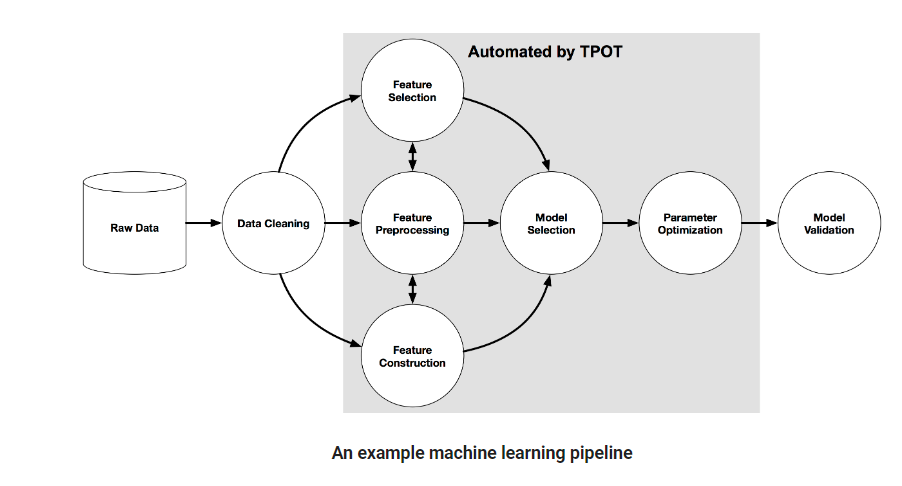
| Gradient Boosting Algorithmen |
| Dijkstra Algorithmus |
| t-sne-Algorithmus |
| CAH Algorithmus ML Clustering |
| 3 ML Algorithmen die du kennen solltest |
Die beste Pipeline finden mit TPOT
Nachdem wir nun verstanden haben, was TPOT ist und warum es nützlich ist, werden wir uns ansehen, wie man es einrichtet und benutzt. ?Zur Erinnerung: TPOT basiert auf scikit-learn, was den Code vertraut macht, wenn du diese Bibliothek schon einmal benutzt hast.- Beginne mit dem Importieren der TPOT-Module und anderer Module, die du brauchst, um dein Modell zu definieren: ‚pip install tpot‘. Während des Schrittes der Datenumwandlung musst du die Zielvariable unbedingt umbenennen und ihr den Namen ‚class‘ geben.
- Da TPOT nur Daten im numerischen Format berücksichtigt, ist es notwendig, die notwendigen Transformationen auf die erklärenden Variablen anzuwenden.
- Nachdem du deinen Datensatz in einen Trainings- und einen Testsatz aufgeteilt hast, kannst du deinen TPOT-Klassifikator und seine Parameter definieren.
- Um TPOT auf deinen Datensatz anzuwenden, musst du nur die Methode .fit() verwenden. Sobald die Berechnung abgeschlossen ist, siehst du als Output die beste Pipeline für deinen Datensatz.
- Du kannst dann die Methode .score() verwenden, um die Leistung des Modells zu messen, das TPOT ausgewählt hat.
