
Researchers at Yale and IBM have unveiled a new framework to decode what artificial intelligence models actually “understand” about the world, according to a study published in Nature Machine Intelligence. The approach, developed by Jonathan Warrell and colleagues, applies philosophy of science principles to systematically analyze how AI systems create internal representations of real-world concepts—a critical step toward making these powerful but opaque technologies more interpretable.
The breakthrough comes as AI systems increasingly influence critical decisions in medicine and healthcare, where understanding how models arrive at their conclusions can be a matter of life and death. The team, led by Jonathan Warrell from NEC Laboratories America and Yale University, along with co-lead authors Michael Gancz from Stanford University and Hussein Mohsen from the University of Toronto, developed what they call a “model semantics” framework.
Unlike existing interpretability methods that focus on individual techniques, this framework provides a comprehensive structure for analyzing how AI models relate to real-world phenomena. It adapts formal concepts from the philosophy of science to systematically evaluate what deep learning systems have actually learned from their training data.
“The framework moves beyond current interpretability methods by treating them as just one component of a model’s overall semantic structure,” according to the study published in Nature Machine Intelligence. The approach deconstructs the concept of interpretability into formally defined semantic components, allowing researchers to better understand the implicit meanings within AI systems.
Breaking Down the Black Box
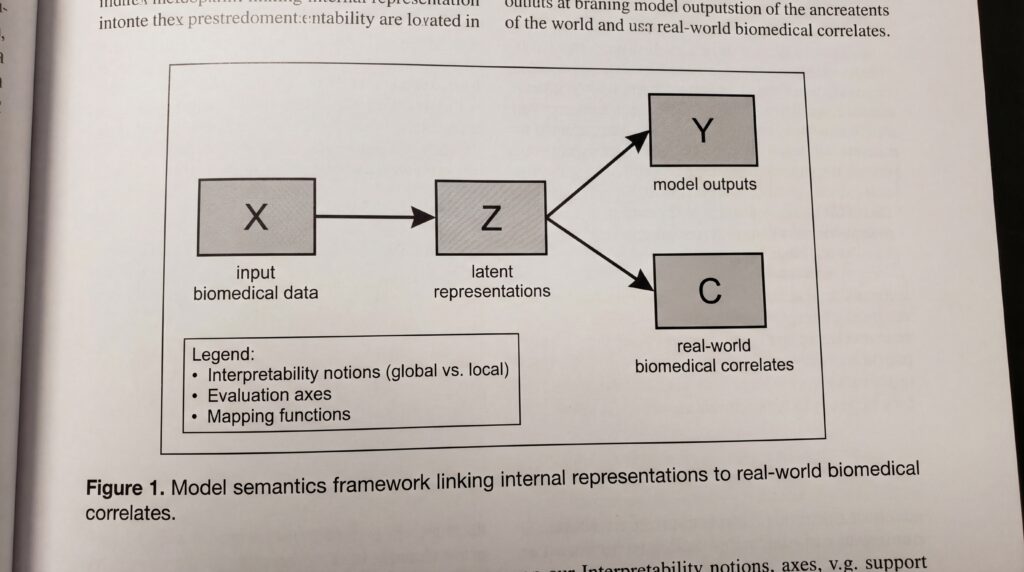
The model semantics framework addresses a fundamental challenge in artificial intelligence: determining what neural networks actually “know” about the world they model. In biomedicine, where AI increasingly assists with diagnosis, drug discovery, and treatment planning, this understanding is crucial for ensuring safety and reliability.
The research team, which also includes Prashant Emani and Mark Gerstein from Yale’s departments of Molecular Biophysics and Biochemistry, Computer Science, and Statistics and Data Science, emphasizes that their goal is not to create new interpretability methods but to provide a formal structure for analyzing existing ones.
By borrowing from the philosophy of science, where model semantics refers to how scientific models represent real-world phenomena, the framework offers a systematic way to uncover and evaluate the real-world correlates of a model’s internal representations. This theoretical foundation could prove particularly valuable in biomedical applications, where understanding model decisions can directly impact patient care.
The publication represents a significant theoretical advance in making AI more transparent and trustworthy, though the full practical implications for biomedical applications await further detailed analysis as the complete methodology becomes available to the broader research community.
Sources
- doi.org

























