

Microsoft Research hat am 12. März 2026 AgentRx präsentiert, ein Open-Source-Framework, das automatisch diagnostiziert, weshalb KI-basierte Agenten bei komplexen Aufgaben scheitern. Das Werkzeug ermittelt den genauen Schritt, an dem der Prozess eines Agenten nicht mehr wiederherstellbar ist, und erzielte in Tests mit 115 fehlgeschlagenen KI-gesteuerten Abläufen eine um 23,6 % höhere Genauigkeit als bisherige Verfahren.
Das System betrachtet die Ausführung von KI-basierten Agenten als überprüfbares Systemprotokoll und bietet Entwicklerinnen und Entwicklern einen evidenzbasierten, lückenlosen Prüfpfad zur Behebung komplexer Fehler, erklärt Microsoft Research.
AgentRx arbeitet mit einer dreistufigen diagnostischen Pipeline. Zunächst erstellt es ausführbare Bedingungen, die korrektes Agentenverhalten definieren, indem es Regeln aus spezifischen Werkzeugschemata wie gängigen OpenAPI-Spezifikationen sowie aus in natürlicher Sprache formulierten fachlichen Richtlinien kombiniert. Anschließend spielt das Framework den vollständigen Ablauf des Agenten systematisch erneut ab und bewertet jede Aktion anhand dieser Vorgaben. Bei Verstößen identifiziert es den ersten nicht mehr behebbaren Schritt als „kritischen Fehler“, sodass sich Entwicklerinnen und Entwickler auf den genauen Ursprung statt auf nachgelagerte Effekte konzentrieren können.
Performance-Validierung
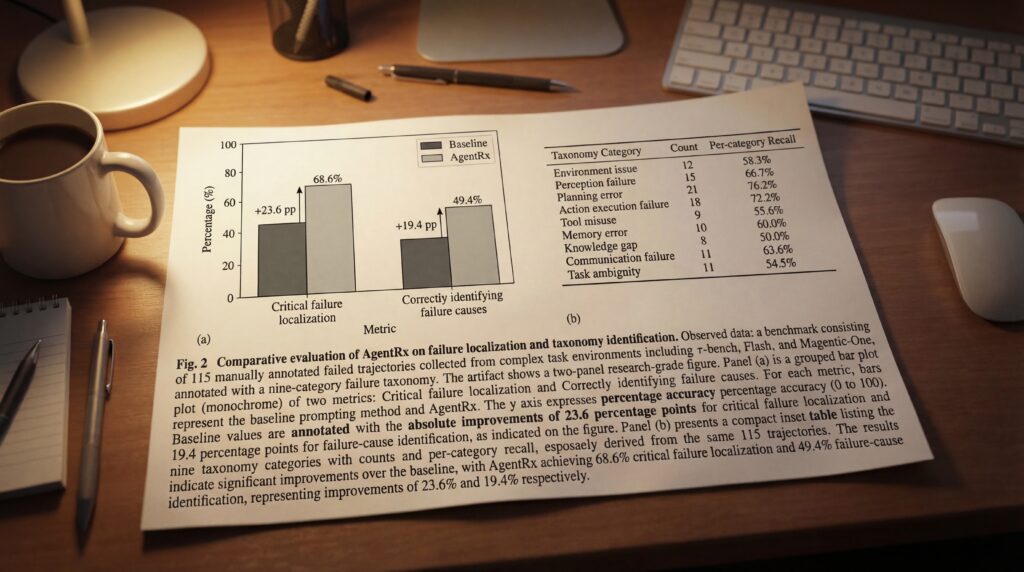
Microsoft Research entwickelte den AgentRx Benchmark, um die Wirksamkeit des Frameworks zu überprüfen, und erstellte einen Datensatz aus 115 manuell annotierten, fehlgeschlagenen Abläufen aus komplexen Aufgaben-Umgebungen, darunter τ-bench, Flash und Magentic-One. Der Annotierungsprozess ergab eine detaillierte Fehlertaxonomie mit neun Kategorien, die unter anderem Probleme wie etwa mangelnde Plantreue und die Erfindung von nicht in den Beobachtungen enthaltenen Informationen umfasst.
Tests zeigten deutliche Verbesserungen gegenüber bestehenden LLM-basierten Prompting-Ansätzen auf. AgentRx erzielte eine absolute Verbesserung von 23,6 % bei der Lokalisierung des kritischen Fehlers und eine absolute Verbesserung von 19,4 % bei der korrekten Identifikation der zugrundeliegenden Fehlerursachen gemäß der Taxonomie, berichtete Microsoft Research.
Marktauswirkungen
Die Open-Source-Veröffentlichung sowohl des Frameworks als auch des annotierten Benchmarks positioniert Microsoft an der Spitze der Bestrebungen, die Fehlerbehebung bei KI-basierten Agenten systematischer und evidenzgetriebener zu gestalten. Das Werkzeug adressiert einen kritischen Engpass in der KI-Entwicklung, da Unternehmen zunehmend autonome Agenten für komplexe Aufgaben einsetzen.
Durch präzise, überprüfbare Diagnosen ermöglicht AgentRx Entwicklerinnen und Entwicklern, transparentere und verlässlichere KI-gestützte Systeme zu entwickeln. Microsoft Research lud die Community ein, diese Werkzeuge für ihre eigenen agentenbasierten Arbeitsabläufe zu nutzen und zur wachsenden Wissensdatenbank rund um kritische Fehlerbedingungen beizutragen.
Obwohl das Framework auf den getesteten Architekturen vielversprechende Ergebnisse liefert, bleibt die Leistungsfähigkeit bei Agentensystemen oder spezifischen Fehlermustern, die im Benchmark nicht abgebildet sind, unerforscht, was Chancen für die Weiterentwicklung und den Ausbau der diagnostischen Fähigkeiten eröffnet.
Sources
- microsoft.com/en-us/research/blog
