

Researchers have developed P-EAGLE, a new system that speeds up artificial intelligence language models by up to 69% compared to current methods. The technology, tested on NVIDIA’s latest B200 GPUs, generates multiple text predictions simultaneously rather than one at a time, eliminating a major bottleneck that slows down AI responses in applications like ChatGPT.
The breakthrough addresses a fundamental challenge in how AI systems process and generate text. Traditional methods like EAGLE-3 must generate each predicted word sequentially, waiting for one to complete before starting the next. P-EAGLE overcomes this limitation by processing all predictions in a single computational step, according to research published in the AWS Machine Learning Blog.
This architectural shift has immediate practical benefits. When tested on workloads including code generation and multi-turn conversations, the system achieved its peak 1.69x speedup on long-form code generation tasks. The technology maintained a 1.55x improvement on both function-level code synthesis and conversational AI benchmarks, demonstrating consistent performance across diverse applications.
Technical Innovation
The key innovation lies in how P-EAGLE handles missing information during text generation. While previous systems required actual tokens and internal states from each step before proceeding, P-EAGLE substitutes unavailable data with learnable parameters called “mask token embeddings” and shared hidden states. This allows the system to process multiple positions simultaneously without waiting for sequential outputs.
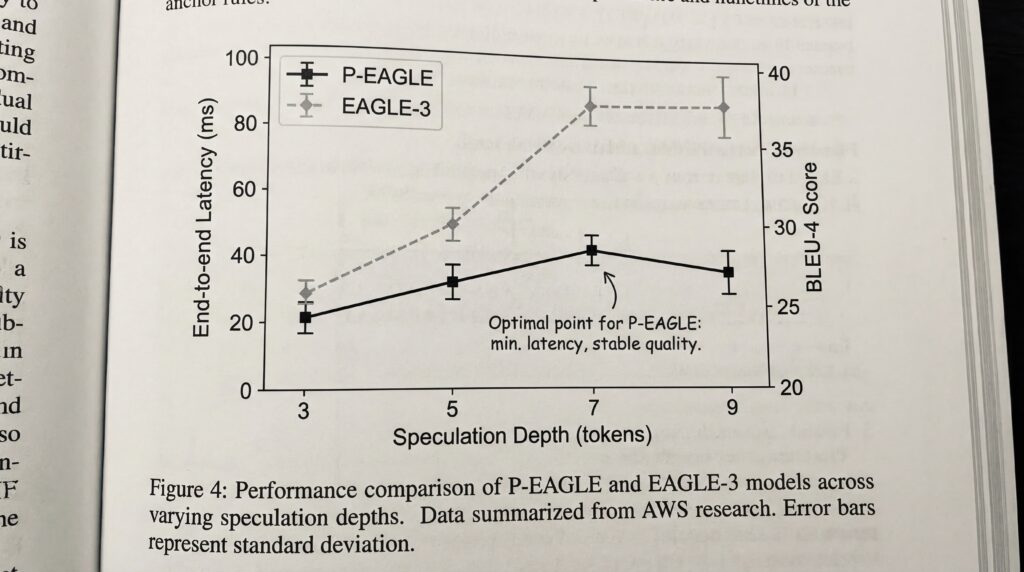
Perhaps most significantly, P-EAGLE can effectively utilize deeper speculation depths. The system achieved optimal performance at a speculation depth of seven tokens, compared to just three for traditional EAGLE-3, according to the AWS research. This deeper speculation capability directly translates to faster response times for end users.
Market Availability and Trade-offs
The technology is already integrated into the vLLM inference server under an Apache 2.0 license, making it freely available for commercial use. Pre-trained models compatible with P-EAGLE are available on Hugging Face for popular AI systems including GPT-OSS and Qwen3-Coder.
The primary trade-off is increased memory consumption due to the parallel architecture’s larger attention matrices. However, the AWS team developed a “sequence partition algorithm” to manage memory usage during training, making the system practical for real-world deployment.
Importantly, P-EAGLE maintains lossless output quality, producing identical results to standard methods while achieving higher acceptance rates for generated text, indicating more accurate predictions with fewer corrections needed.
Sources
- aws.amazon.com/blogs/machine-learning

























