

Amazon Web Services launched two new monitoring tools for its Bedrock AI platform on Monday, giving developers real-time visibility into their generative AI applications’ performance and resource usage. The CloudWatch metrics—TimeToFirstToken and EstimatedTPMQuotaUsage—measure response times for streaming AI requests and track token consumption to prevent service disruptions, enabling teams to build more reliable AI-powered applications without additional client-side monitoring.
The new capabilities arrive as enterprises increasingly struggle with performance bottlenecks and cost overruns in their AI deployments, particularly when using resource-intensive models like Anthropic’s Claude, which applies a 5x burndown rate on output tokens. This means 100 output tokens actually consume 500 tokens of the available quota, a calculation that was previously opaque to developers.
TimeToFirstToken measures server-side latency in milliseconds from when Bedrock receives a streaming request to when it generates the first response token, providing pure performance signals unaffected by network conditions. The metric works exclusively with streaming APIs including ConverseStream and InvokeModelWithResponseStream.
EstimatedTPMQuotaUsage tracks how inference requests consume Tokens Per Minute quotas, accounting for model-specific burndown multipliers and other internal factors. The calculation varies by throughput model: on-demand throughput adds input tokens, cache writes, and multiplied output tokens, while provisioned throughput applies different weights to cached operations.
Proactive Performance Management
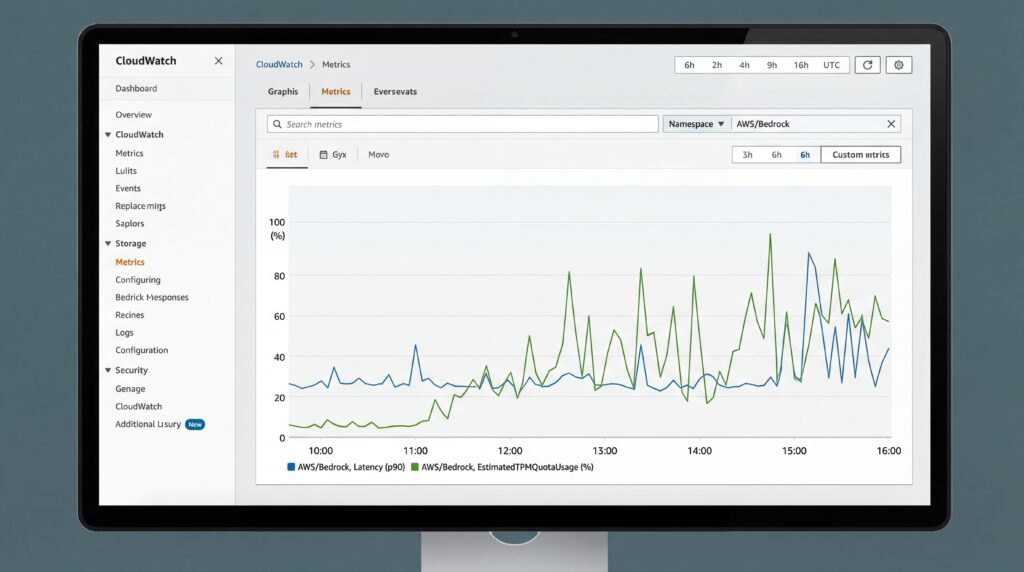
According to the AWS Machine Learning Blog, the metrics are automatically emitted to the AWS/Bedrock CloudWatch namespace for all successful inference requests at no additional cost beyond standard model usage. This server-side visibility eliminates the need for client-side instrumentation that many teams previously built themselves.
Engineering teams can now set Service Level Objectives and create automated alarms. For latency-sensitive applications, teams might configure alerts when 90th percentile response times exceed 500 milliseconds. High-throughput applications can trigger warnings when consumption approaches 80% of available quota, preventing service disruptions before they occur.
The metrics integrate with Infrastructure as Code tools like CloudFormation and Terraform, enabling teams to define monitoring strategies programmatically. Early warning signals from EstimatedTPMQuotaUsage can trigger circuit breakers or reduce request rates before throttling errors impact users.
Competitive Implications
The release positions AWS more competitively against rivals like Microsoft Azure and Google Cloud, which offer their own AI platform monitoring solutions. As generative AI moves from experimentation to production deployments, operational visibility becomes crucial for enterprise adoption.
The timing aligns with growing enterprise demand for better AI cost management and performance optimization tools, particularly as companies scale their generative AI implementations beyond pilot programs to mission-critical applications serving millions of users.
Sources
- aws.amazon.com/blogs

























