

.elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
What is Phi-4 exactly?
Phi-4 is a small language model (SLM) created by Microsoft, with 14 billion parameters. Originally available on Azure AI Foundry, it is now accessible as open source on Hugging Face under the MIT license. This model stands out for its superior performance compared to Google Gemini Pro 1.5 and OpenAI GPT-4, particularly in complex tasks like mathematical reasoning, while consuming fewer computing resources than large language models (LLM). Phi-4 is designed using a mix of synthetic data, public domain websites, academic literature, and question-answer datasets. It has been optimized to deliver high-quality results with advanced reasoning. Microsoft has focused on the model’s robustness and security, using supervised fine-tuning (SFT) techniques and direct preference optimization (DPO) to ensure precise adherence to instructions and solid security measures. Phi-4 is particularly suited to environments with memory and compute constraints, as well as scenarios requiring low latency. Overall, it represents a significant advancement in language model research, offering a powerful and resource-efficient alternative for generative AI applications.How does Phi-4 perform?
In a landscape where the power of language models is often associated with their size, Phi-4 challenges this trend by proving that a compact model can rival much larger architectures. Thanks to extensive optimization, it achieves a high level of performance in understanding and reasoning while maintaining a reduced footprint. Where other models require tens of billions of active parameters to deliver comparable results, Phi-4 emerges as a perfect balance between efficiency and power. This strategic positioning meets a growing demand for more accessible and resource-efficient AI, without compromising quality. Its optimized architecture allows not only faster execution but also better adaptability to resource-limited environments, such as embedded applications or low-energy servers. By reducing dependency on massive infrastructures, Phi-4 paves the way for the democratization of artificial intelligence, where high performance and energy efficiency are no longer incompatible. It illustrates a new generation of models capable of meeting industrial and academic needs while remaining agile and scalable..elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=”.svg”]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}
What distinguishes Phi-4 from similar models?
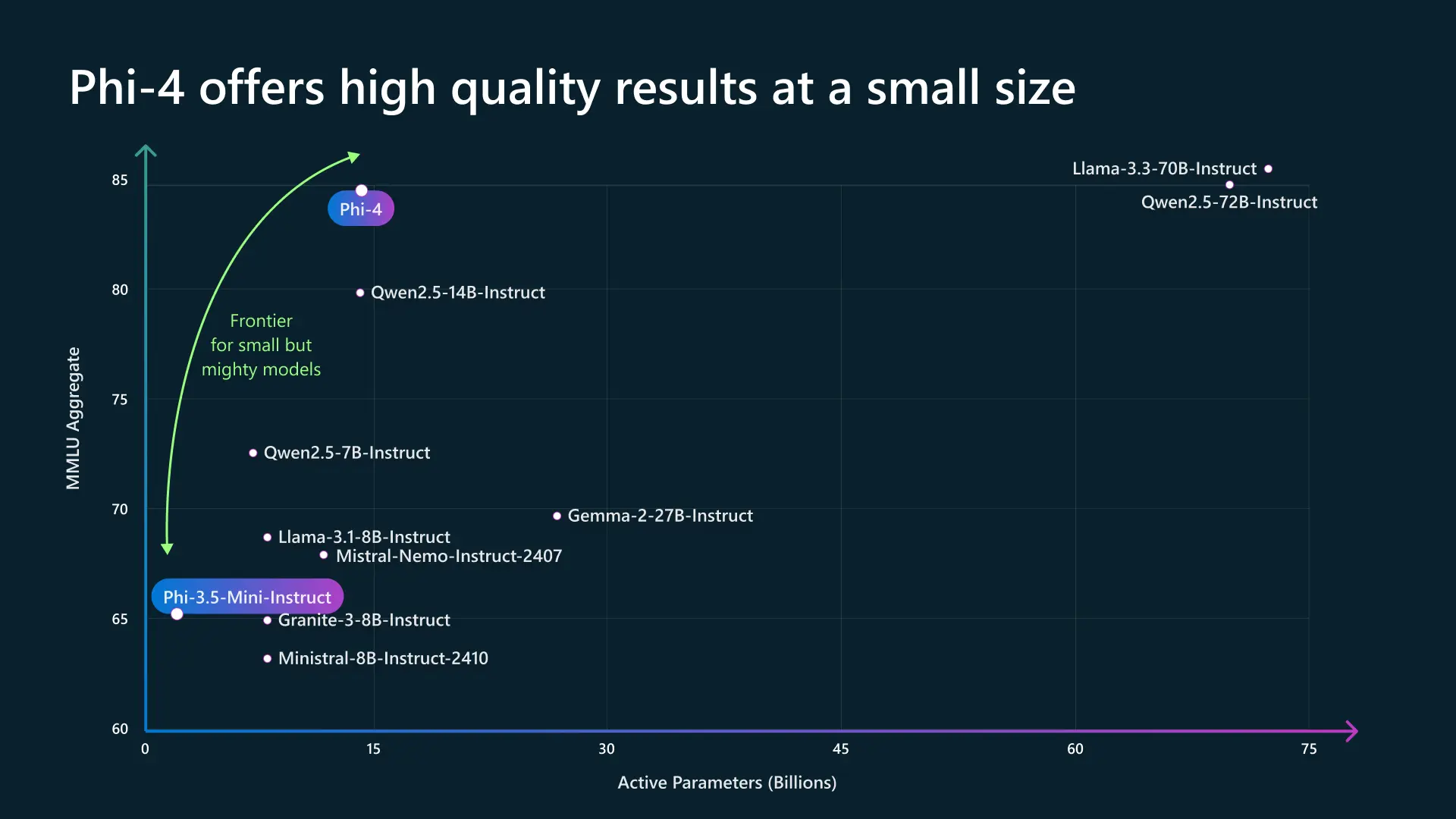
Phi-4 stands out with its excellent optimization, competing with slightly larger models (like Qwen2.5-14B or Mixtral) while remaining lightweight and efficient. Its MMLU score of 85 makes it a very competitive model in the SLM (Small Language Models) category.| Model | Active Parameters (B) | MMLU Score | Type | Main Advantages | Disadvantages |
| Phi-4 | ~10B | ~85 | Optimized, compact model | Excellent performance for its size, efficient in inference, good reasoning | Less powerful than larger models like GPT-4 or Llama 3-70B |
| Mixtral (Mistral AI) | 12.9B (MoE, 2 active experts) | ~82-83 | MoE (Mixture of Experts) | Very good balance between performance and efficiency, fast and optimized | Heavier in inference than Phi-4 |
| Qwen2.5-14B-Instruct | 14B | ~80 | Dense model | Good understanding of natural language, strong in general tasks | Less optimized than Phi-4, requires more power |
| Llama 3.1-8B-Instruct | 8B | ~70 | Dense model | Lightweight and efficient, good compromise for certain tasks | Inferior in overall performance to Phi-4 |
| Mistral-8B-Instruct | 8B | ~68-70 | Dense model | Very efficient in inference, open-source | Lower MMLU score than Phi-4, less versatile |
| Granite-3-8B-Instruct | 8B | ~65-67 | Dense model | Compact and fast | Less performant than Phi-4 in reasoning and analysis |

Use Case: Phi-4 addressing a mathematical logic problem
Imagine a student preparing for a mathematics exam and tackling a complex problem: “A snail climbs a 10-meter wall. Each day, it ascends 3 meters but slides down 2 meters at night. How many days will it take to reach the top?” A classic model might simply provide an answer by mechanically calculating:- Day 1: It climbs to 3 m, slides down to 1 m
- Day 2: It climbs to 4 m, slides down to 2 m
- And so on.
- It identifies the recurring pattern: each day, the snail effectively progresses by a net of 1 meter.
- It optimizes reasoning: after 7 days, it reaches 7 meters.
- It detects an exception: on the eighth day, it climbs directly 3 meters and reaches the top without sliding back.
- Hence, it correctly concludes that it takes 8 days for the snail to reach the top.

























