

Forschende haben P-EAGLE entwickelt, ein neues System, das KI-Sprachmodelle im Vergleich zu gängigen Methoden um bis zu 69 % beschleunigt. Die Technologie, getestet auf NVIDIAs neuesten B200-GPUs, generiert mehrere Textvorhersagen simultan statt nacheinander und beseitigt damit einen massiven Engpass, der KI-Antworten in Anwendungen wie ChatGPT verzögert.
Der Durchbruch behebt ein grundlegendes Problem darin, wie KI-Systeme Text verarbeiten und generieren. Herkömmliche Methoden wie EAGLE-3 müssen jedes vorhergesagte Wort sequenziell generieren und warten, bis eines abgeschlossen ist, bevor das nächste beginnt. P-EAGLE überwindet diese Limitierung, indem sämtliche Vorhersagen in einem einzigen Rechenschritt verarbeitet werden, wie der AWS Machine Learning Blog darlegt.
Dieser Architekturwechsel bringt direkte praktische Vorteile. In Tests mit Aufgabenlasten wie Code-Generierung und Multi-Turn-Konversationen erreichte das System seine Spitzenbeschleunigung von 1,69x bei Aufgaben zur Langform-Code-Generierung. Bei Code-Synthese auf Funktionsebene und Dialog-KI-Benchmarks behauptete die Technologie eine 1,55-fache Verbesserung und bewies damit konsistente Leistung über diverse Anwendungsfälle hinweg.
Technische Innovation
Die entscheidende Neuerung liegt darin, wie P-EAGLE mit fehlenden Informationen während der Textgenerierung verfährt. Während frühere Systeme echte Tokens und interne Zustände aus jedem Schritt benötigten, bevor sie fortfahren konnten, ersetzt P-EAGLE nicht verfügbare Daten durch lernbare Parameter namens „Mask Token Embeddings“ sowie gemeinsame verborgene Zustände. So kann das System mehrere Positionen simultan verarbeiten, ohne auf sequenzielle Ausgaben warten zu müssen.
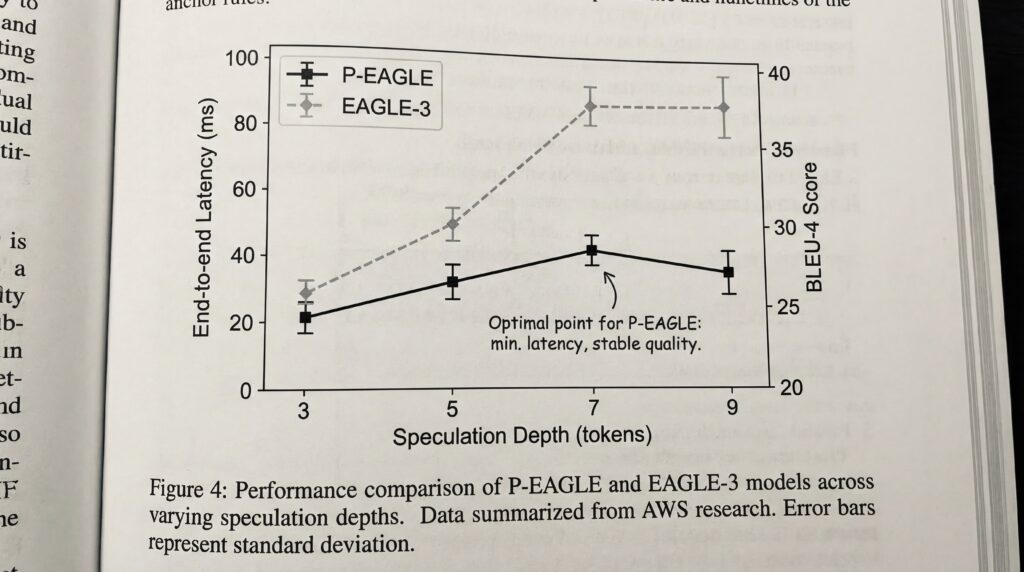
Am allerwichtigsten ist, dass P-EAGLE eine effektiv größere Spekulationstiefe nutzt. Laut AWS-Forschung erreichte das System die optimale Leistung bei einer Spekulationstiefe von exakt sieben Tokens, verglichen mit lediglich drei beim herkömmlichen EAGLE-3. Diese signifikant erhöhte Spekulationstiefe führt unmittelbar zu schnelleren Antwortzeiten für Endnutzerinnen und Endnutzer.
Marktverfügbarkeit und Kompromisse
Die Technologie ist bereits in den vLLM Inference Server unter einer Apache-2.0-Lizenz eingebunden und somit kostenlos für die kommerzielle Nutzung verfügbar. Vortrainierte Modelle, die mit P-EAGLE kompatibel sind, stehen auf Hugging Face für gängige KI-Systeme wie GPT-OSS und Qwen3-Coder bereit.
Der wesentliche Kompromiss ist ein gestiegener Speicherbedarf aufgrund umfangreicherer Aufmerksamkeitsmatrizen der parallelen Architektur. Das AWS-Team entwickelte jedoch einen „Sequence Partition Algorithm“, um die Speicherauslastung während des Trainings zu kontrollieren und das System für den Praxiseinsatz praktikabel zu gestalten.
Entscheidend ist, dass P-EAGLE eine absolut verlustfreie Ausgabequalität beibehält. Es liefert identische Resultate wie Standardmethoden und erreicht dabei höhere Akzeptanzraten für generierten Text, was auf präzisere Vorhersagen mit weniger erforderlichen Korrekturen hindeutet.
Sources
- aws.amazon.com/blogs/machine-learning
