
Forschende des MIT und der Polytechnischen Universität Mailand haben eine neue Technik entwickelt, die KI-Systeme ihre Entscheidungen erklären lässt, indem sie automatisch die Konzepte entdeckt und benennt, die diese für Vorhersagen nutzen. Das Mechanistic Concept Bottleneck Model, vorgestellt auf der International Conference on Learning Representations, verwandelt „Black-Box“-KI-Modelle in transparentere Systeme, die eine höhere Genauigkeit als bisherige Erklärbare-KI-Methoden erreichen und zugleich klarere Begründungen für ihre Resultate liefern.
Dieser Durchbruch behandelt eine zentrale Herausforderung beim Einsatz von KI in sensiblen Anwendungen, bei denen das Verständnis der Begründung hinter Vorhersagen ebenso wichtig sein kann wie die Genauigkeit selbst. Der Ansatz des Forschungsteams konzipiert grundlegend neu, wie KI-Systeme Erklärungen erzeugen, indem er Konzepte direkt aus den Modellen selbst extrahiert, anstatt sich auf manuell definierte Kategorien zu verlassen, laut dem auf ICLR 2026 veröffentlichten Fachartikel.
So funktioniert die Technologie
Das M-CBM verwendet einen dreistufigen Prozess, um intransparente KI-Modelle in interpretierbare Systeme zu verwandeln. Zuerst analysiert ein spezialisiertes Deep-Learning-Modell namens Sparse Autoencoder die internen Merkmale vortrainierter Modelle, um die wichtigsten für Vorhersagen genutzten Muster zu identifizieren, wie von MIT News erläutert.
Als Nächstes beschreibt ein multimodales Large Language Model diese maschinell entdeckten Konzepte automatisch in natürlicher Sprache, etwa „clustered brown dots“ oder „variegated pigmentation“, und annotiert dementsprechend ganze Bilddatensätze. Schließlich trainiert das System ein Concept-Bottleneck-Modul, welches das Modell dazu zwingt, Vorhersagen ausschließlich auf diese extrahierten und gekennzeichneten Konzepte zu stützen, wobei jede Entscheidung lediglich die fünf relevantesten Konzepte heranzieht, um Verständlichkeit zu gewährleisten.
Dieser Ansatz beseitigt „Information Leakage“, ein häufiges Problem, bei dem Modelle verdeckt auf Informationen jenseits ihrer ausgewiesenen Begründung zurückgreifen, wodurch die Erklärungen dem tatsächlichen Entscheidungsprozess genauer entsprechen, wie die Forschenden berichten.
Leistung und Kompromisse
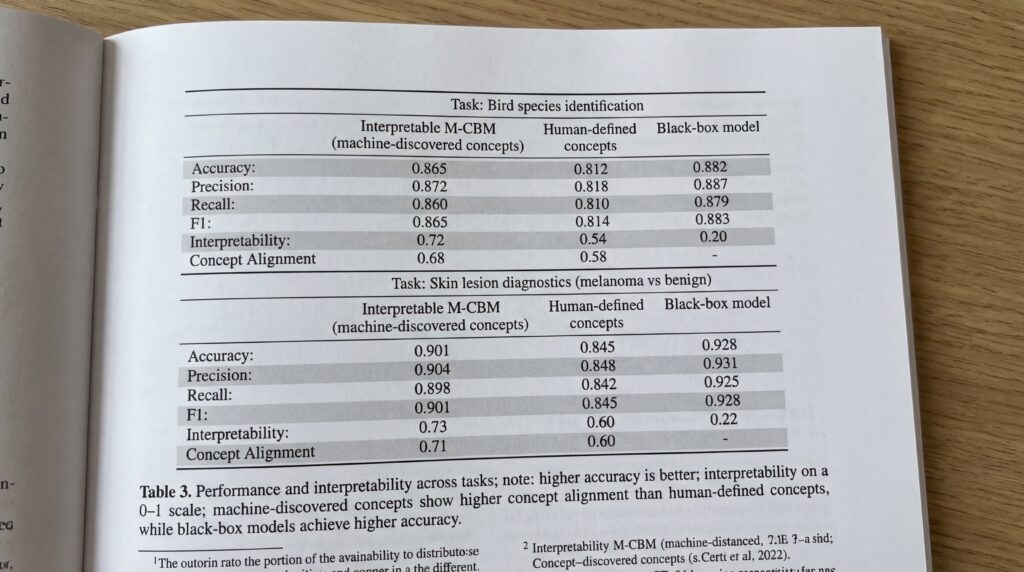
Tests zur Identifikation von Vogelarten und Diagnostik von Hautläsionen zeigten, dass M-CBM die höchste Genauigkeit unter interpretierbaren KI-Modellen erreichte. Laut der Studie erwiesen sich die maschinell entdeckten Konzepte als direkter auf Aufgaben anwendbar als manuell definierte.
Die Forschenden räumen jedoch eine fortbestehende Herausforderung ein. „Black-Box-Modelle, die nicht interpretierbar sind, übertreffen unsere weiterhin“, merkten sie an und hoben die anhaltende Spannung zwischen Erklärbarkeit und reiner Vorhersagekraft hervor. Dies bedeutet, dass Klinikärztinnen und -ärzte möglicherweise zwischen einem genaueren Black-Box-Modell und einem etwas weniger genauen M-CBM wählen müssen, welches seine Begründung bei der Diagnose potenzieller Melanome erklären kann.
Mit Blick nach vorne plant das Team, den Ansatz mit größeren multimodalen LLMs zu skalieren und Methoden zu entwickeln, um Information Leakage weiter zu reduzieren. Die Arbeit schafft „eine natürliche Brücke zu symbolischer KI und zu Wissensgraphen“ und weist auf Potenzial hin, strukturiertere und robustere KI-Systeme zu entwickeln, die insbesondere für das Gesundheitswesen, das Finanzwesen und andere Sektoren mit Bedarf an transparenter Entscheidungsfindung wertvoll sind.
Sources
- news.mit.edu
