

IBM hat im März 2026 sein Granite 4.0 1B Speech-Modell vorgestellt, ein kompaktes multilinguales Spracherkennungssystem, das deutlich leistungsfähiger ist als viel größere Konkurrenten, obwohl es nur eine Milliarde Parameter besitzt. Das Modell, das bei der Einführung die OpenASR-Bestenliste anführte, führt automatische Spracherkennung sowie bidirektionale Übersetzung für sechs Sprachen aus, während es effizient auf Edge-Geräten und ressourcenbeschränkter Hardware läuft, unter der Apache-2.0-Lizenz.
Das Modell erreicht seine bahnbrechende Leistung durch eine ausgeklügelte Architektur aus drei Teilen, die einen 16-block Conformer encoder, einen spezialisierten Sprachprojektor und IBMs vortrainiertes Granite-Sprachmodell mit 128.000 token context length kombiniert, laut der technischen Dokumentation des Unternehmens auf Hugging Face. Dieses Design ermöglicht es dem System, Audiodatenströme effizient zu verarbeiten, während es jene Genauigkeit beibehält, die typischerweise mit Modellen verbunden ist, welche doppelt so groß sind.
Technische Innovation
IBM führte mehrere neuartige Merkmale ein, die Granite 4.0 1B Speech von der Konkurrenz abheben. Das System integriert keyword list biasing, wodurch es in der Lage ist, spezifische Begriffe wie Firmennamen und technische Abkürzungen zuverlässig zu erkennen, die herkömmliche Spracherkennungssysteme laut IBM-Blogbeitrag oft verwirren. Zusätzlich verwendet das Modell speculative decoding, um die Inferenzzeiten zu beschleunigen, was es besonders geeignet für Echtzeit-Anwendungen macht.
Das Modell unterstützt automatische Spracherkennung für Englisch, Französisch, Deutsch, Spanisch, Portugiesisch und Japanisch, wobei es bidirektionale Übersetzung zwischen Englisch und diesen Sprachen anbietet.
Unternehmensanwendungen
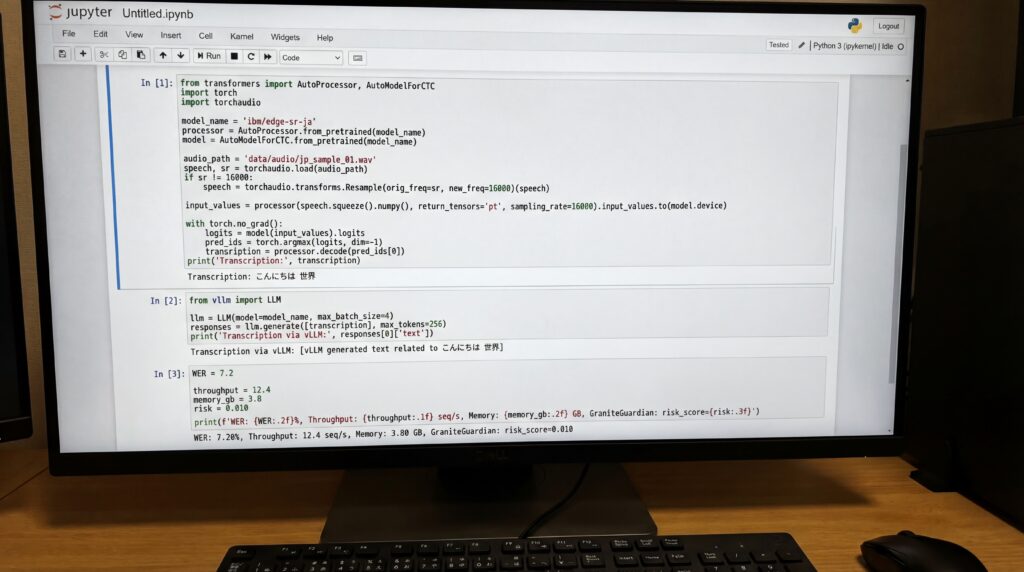
IBM hat das Modell speziell für Unternehmensumgebungen entworfen, in denen rechnerische Ressourcen begrenzt sind. Das System läuft nativ in der beliebten transformers library sowie dem vLLM-Framework für Inferenz mit hohem Durchsatz, laut der Dokumentation des Unternehmens. Diese Kompatibilität stellt sicher, dass Entwickler die Technologie problemlos in bestehende Arbeitsabläufe integrieren können, ohne umfangreiche Änderungen vornehmen zu müssen.
Für sicherheitskritische Anwendungen hat IBM Schutzmaßnahmen eingebaut, die bei fehlerhaften oder manipulierten Eingaben standardmäßig auf reine Transkription zurückgreifen. Das Unternehmen empfiehlt, das Modell mit seinem Granite Guardian Risikoerkennungssystem für eine verbesserte Sicherheit in Unternehmensbereitstellungen zu koppeln, gemäß den technischen Spezifikationen.
Der Trainingsprozess kombinierte öffentlich zugängliche Datensätze mit speziell generierten synthetischen Daten, um die Leistung bei japanischer Spracherkennung und domänenspezifischer Terminologie zu verbessern, wie IBM berichtete. Dieser Hybridansatz ermöglichte es dem Unternehmen, wettbewerbsfähige Word Error Rate-Werte bei Standard-Englisch-Benchmarks zu erzielen, während die kompakte Größe des Modells für Edge-Deployments beibehalten wurde.
Sources
- https://huggingface.co/blog
