

Hugging Face hat am 10. März 2026 die Storage Buckets eingeführt und damit eine native Objektspeicher-Lösung vorgestellt, die darauf ausgelegt ist, die in KI-Entwicklungs-Workflows üblichen, massiven und sich häufig ändernden Dateien zu verwalten. Das neue Feature, direkt in die Hugging Face Hub-Plattform integriert, bietet Entwicklern S3-ähnliche Speicherfunktionen, optimiert für das Verwalten von Modell-Checkpoints, Logs und verarbeiteten Datensätzen, ohne die Einschränkungen traditioneller Versionskontrollsysteme.
Die neuen Storage Buckets arbeiten als nicht versionierte Container innerhalb der Namespaces der Nutzer und unterscheiden sich damit von den traditionellen, Git-basierten Repositories der Plattform. Laut der Ankündigung von Hugging Face nutzt der Service Xet, ein Chunk-basiertes Speicher-Backend, das inhaltsbasierte Deduplizierung durchführt, Dateien in kleinere Stücke zerlegt und nur einzigartige Blöcke speichert. Von dieser Architektur profitieren insbesondere Enterprise-Plan-Kunden, die auf Basis des deduplizierten Speicherbedarfs und nicht nach den ursprünglichen Dateigrößen abgerechnet werden.
Die Plattform adressiert einen der kritischsten Schwachpunkte in Machine-Learning-Workflows, bei dem Gits Versionierungsmodell eher hinderlich als hilfreich ist. Hugging Face hat die Buckets ausdrücklich für häufige Überschreibungen und Löschungen ohne das Anlegen von Versionshistorien entworfen und positioniert sie im Vergleich zu Git LFS als „die richtige Abstraktion“ für veränderliche ML-Artefakte.
Developer Tools und Integration
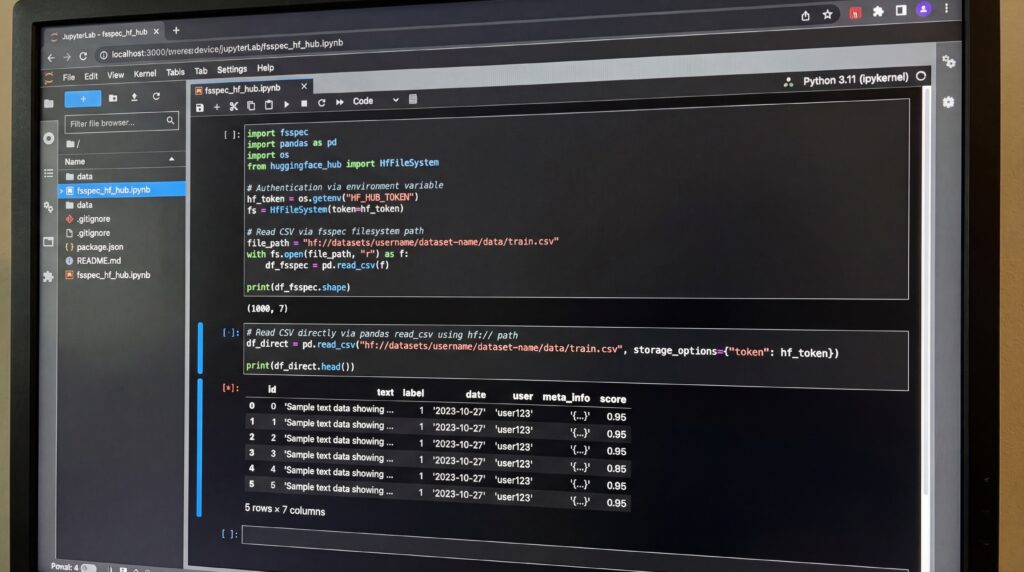
Entwickler können über mehrere Schnittstellen mit Storage Buckets interagieren, darunter die hf CLI mit Befehlen zum Erstellen, Synchronisieren und Kopieren von Daten. Die huggingface_hub Python Library (Version 1.5.0+) und die @huggingface/hub JavaScript Library (Version 2.10.5+) bieten laut der Unternehmensdokumentation programmatischen Zugriff.
Eine zentrale technische Neuerung ist die fsspec-Kompatibilität, die es den Buckets ermöglicht, über das hf://-Protokoll als natives Dateisystem zu fungieren. Diese Integration erlaubt es Data Scientists, Dateien direkt mit gängigen Bibliotheken wie Pandas, Polars und Dask zu lesen, ohne bestehenden Code wesentlich zu ändern.
Der Service umfasst ein „Pre-Warming“-Feature, das Bucket-Daten in bestimmten AWS- oder GCP-Regionen zwischenspeichert, wodurch die Latenz verringert und der Durchsatz für verteilte Trainings-Workloads verbessert wird, indem Daten näher an Rechenressourcen platziert werden, so Hugging Face.
Marktpositionierung
Storage Buckets positionieren Hugging Face direkter gegenüber herkömmlichen Cloud-Anbietern wie AWS S3 und Google Cloud Storage und verstärken zugleich das Ökosystem-Lock-in. Das Unternehmen sieht einen zweistufigen Workflow vor: eine „Working Layer“, die Buckets für transiente Artefakte nutzt, und eine „Publishing Layer“ mit versionierten Repositories für dauerhafte Assets.
Die Konsolidierung der ML-Projekt-Assets im Hugging Face Hub erübrigt die Notwendigkeit separater Cloud-Speicher-Zugangsdaten und Abrechnungen und kann die operative Komplexität für KI-Teams verringern. Künftige Entwicklungsziele umfassen Unterstützung für direkte Transfers zwischen Buckets und Repositories, um den Asset-Freigabeprozess weiter zu verschlanken.
Sources
- https://huggingface.co/blog
