
Forschende von Yale und IBM haben laut einer in Nature Machine Intelligence veröffentlichten Studie ein neues Framework vorgestellt, um zu entschlüsseln, was Artificial Intelligence (KI)-Modelle über die Welt tatsächlich „verstehen“. Der von Jonathan Warrell und Kolleginnen und Kollegen entwickelte Ansatz wendet Prinzipien der Wissenschaftsphilosophie an, um systematisch zu analysieren, wie KI-Systeme interne Repräsentationen realer Konzepte erzeugen, ein entscheidender Schritt, um diese leistungsfähigen, aber undurchsichtigen Technologien besser interpretierbar zu machen.
Der Durchbruch kommt zu einem Zeitpunkt, an dem KI-Systeme zunehmend kritische Entscheidungen in Medizin und Gesundheitswesen beeinflussen, wobei das Verständnis, wie Modelle zu ihren Schlussfolgerungen gelangen, über Leben und Tod entscheiden kann. Das Team unter der Leitung von Jonathan Warrell von den NEC Laboratories America und der Yale University, zusammen mit den Co-Erstautoren Michael Gancz von der Stanford University und Hussein Mohsen von der University of Toronto, entwickelte das, was sie ein „Model Semantics“-Framework nennen.
Anders als bestehende Interpretierbarkeitsmethoden, die sich auf einzelne Techniken konzentrieren, bietet dieses Framework eine umfassende Struktur, um zu analysieren, wie KI-Modelle zu realen Phänomenen in Beziehung stehen. Es adaptiert formale Konzepte aus der Wissenschaftsphilosophie, um systematisch zu bewerten, was Deep-Learning-Systeme tatsächlich aus ihren Trainingsdaten gelernt haben.
„Das Framework geht über aktuelle Interpretierbarkeitsmethoden hinaus, indem es diese lediglich als eine Komponente der semantischen Gesamtstruktur eines Modells behandelt“, heißt es in der in Nature Machine Intelligence veröffentlichten Studie. Der Ansatz zerlegt das Konzept der Interpretierbarkeit in formal definierte semantische Komponenten und ermöglicht es Forschenden, die impliziten Bedeutungen innerhalb von KI-Systemen besser zu verstehen.
Die Black Box aufschlüsseln
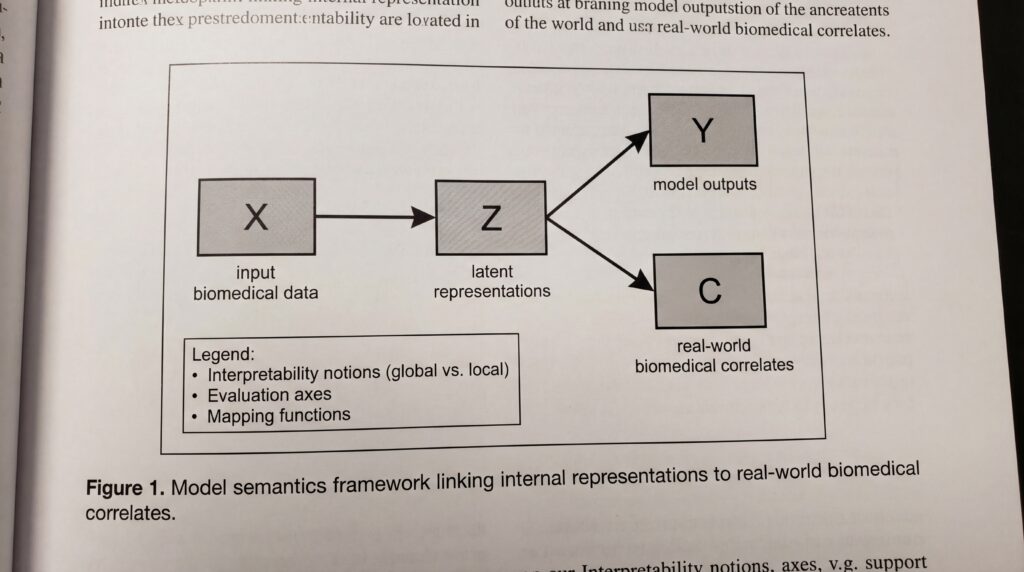
Das Model Semantics-Framework adressiert eine grundlegende Herausforderung der Artificial Intelligence: zu bestimmen, was neuronale Netze über die von ihnen modellierte Welt tatsächlich „wissen“. In der Biomedizin, in der KI zunehmend bei Diagnose, der Wirkstoffentdeckung und Behandlungsplanung unterstützt, ist dieses Verständnis entscheidend, um Sicherheit und Zuverlässigkeit zu gewährleisten.
Das Forschungsteam, zu dem auch Prashant Emani und Mark Gerstein aus den Yale-Fakultäten für Molecular Biophysics and Biochemistry, Computer Science sowie Statistics and Data Science gehören, betont, dass sein Ziel nicht darin besteht, neue Interpretierbarkeitsmethoden zu entwickeln, sondern eine formale Struktur bereitzustellen, um bestehende zu analysieren.
Indem es an die Wissenschaftsphilosophie anknüpft, in der Modellsemantik beschreibt, wie wissenschaftliche Modelle reale Phänomene repräsentieren, bietet das Framework eine systematische Möglichkeit, die realen Korrelate der internen Repräsentationen eines Modells aufzudecken und zu bewerten. Dieses theoretische Fundament könnte sich insbesondere in biomedizinischen Anwendungen als wertvoll erweisen, in denen das Verständnis von Modellentscheidungen die Patientenversorgung direkt beeinflussen kann.
Die Publikation stellt einen bedeutenden theoretischen Fortschritt dar, um KI transparenter und vertrauenswürdiger zu machen, auch wenn die vollständigen praktischen Implikationen für biomedizinische Anwendungen noch einer weiteren detaillierten Analyse bedürfen, sobald die vollständige Methodik der breiteren Forschungsgemeinschaft zur Verfügung steht.
Sources
- doi.org
