

Amazon Web Services hat am Montag zwei neue Monitoring-Tools für seine Bedrock KI-Plattform eingeführt und Entwicklern Echtzeiteinblicke in die Leistung und Ressourcennutzung ihrer generativen KI-Anwendungen ermöglicht. Die CloudWatch-Metriken TimeToFirstToken und EstimatedTPMQuotaUsage messen Antwortzeiten für Streaming-KI-Anfragen und verfolgen den Token-Verbrauch, um Serviceunterbrechungen zu verhindern. So können Teams zuverlässigere KI-gestützte Anwendungen bauen, ohne zusätzliches clientseitiges Monitoring.
Die neuen Funktionen kommen zu einer Zeit, in der Unternehmen zunehmend mit Leistungsengpässen und Kostenüberschreitungen in ihren KI-Deployments zu kämpfen haben, insbesondere bei der Nutzung ressourcenintensiver Modelle wie Anthropics Claude, das eine 5-fache Burndown Rate auf Output-Tokens anwendet. Das bedeutet, dass 100 Output-Tokens tatsächlich 500 Tokens der verfügbaren Quote verbrauchen, eine Berechnung, die für Entwickler zuvor intransparent war.
TimeToFirstToken misst die serverseitige Latenz in Millisekunden, vom Zeitpunkt, an dem Bedrock eine Streaming-Anfrage erhält, bis zur Generierung des ersten Antwort-Tokens. Dadurch entstehen reine Leistungssignale, die nicht von Netzwerkbedingungen beeinflusst werden. Die Metrik funktioniert ausschließlich mit Streaming-APIs, darunter ConverseStream und InvokeModelWithResponseStream.
EstimatedTPMQuotaUsage verfolgt, wie Inferenzanfragen Tokens pro Minute Quoten verbrauchen, wobei modellspezifische Burndown Multiplikatoren und andere interne Faktoren berücksichtigt werden. Die Berechnung variiert je nach Durchsatzmodell: On-Demand Durchsatz addiert Input-Tokens, Cache Schreibvorgänge und multiplizierte Output-Tokens, während bereitgestellter Durchsatz unterschiedliche Gewichtungen für zwischengespeicherte Operationen anwendet.
Proaktives Performance-Management
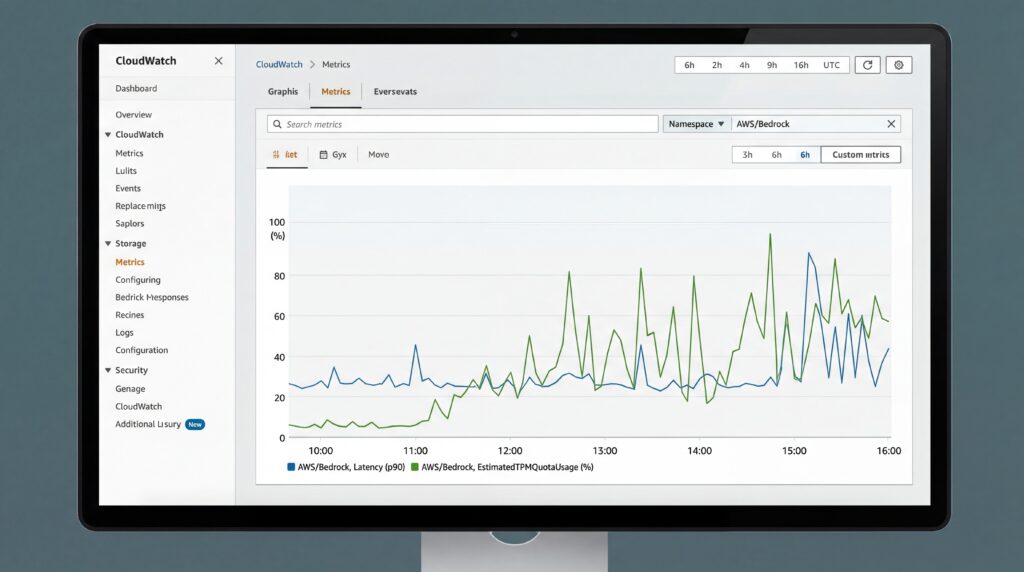
Dem AWS Machine Learning Blog zufolge werden die Metriken für alle erfolgreichen Inferenzanfragen automatisch im CloudWatch-Namespace AWS/Bedrock ausgegeben, und zwar ohne zusätzliche Kosten über die Standard-Modellnutzung hinaus. Diese serverseitige Transparenz macht die clientseitige Instrumentierung überflüssig, die viele Teams zuvor selbst aufgebaut haben.
Engineering-Teams können nun Service Level Objectives festlegen und automatisierte Alarme erstellen. Für latenzsensitive Anwendungen könnten Teams Benachrichtigungen konfigurieren, wenn Antwortzeiten des 90. Perzentils 500 Millisekunden überschreiten. Hochdurchsatz-Anwendungen können Warnungen auslösen, wenn der Verbrauch sich 80% der verfügbaren Quote nähert, um Serviceunterbrechungen vorzubeugen, bevor sie auftreten.
Die Metriken integrieren sich in Infrastructure as Code Tools wie CloudFormation und Terraform und ermöglichen es Teams, Monitoring-Strategien programmatisch zu definieren. Frühwarnsignale von EstimatedTPMQuotaUsage können Circuit Breaker auslösen oder Anfrageraten reduzieren, bevor Drosselungsfehler Nutzer beeinträchtigen.
Wettbewerbliche Auswirkungen
Die Veröffentlichung positioniert AWS wettbewerbsfähiger gegenüber Rivalen wie Microsoft Azure und Google Cloud, die eigene Monitoring-Lösungen für KI-Plattformen anbieten. Während generative KI von der Experimentierphase in produktive Deployments übergeht, wird operative Transparenz entscheidend für die Einführung in Unternehmen.
Der Zeitpunkt entspricht der wachsenden Unternehmensnachfrage nach besseren Tools für KI-Kostenmanagement und Leistungsoptimierung, insbesondere da Unternehmen ihre generative KI über Pilotprogramme hinaus auf geschäftskritische Anwendungen skalieren, die Millionen von Nutzern bedienen.
Sources
- aws.amazon.com/blogs
