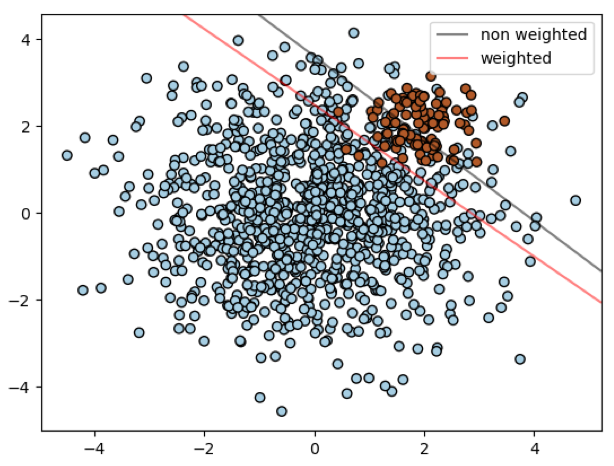
Classification of unbalanced data is a classification problem where the training sample contains a strong disparity between the classes to be predicted. This problem is frequently encountered in binary classification problems, especially in anomaly detection.
This paper will be divided into two parts: The first one focuses on the choice of metrics specific to this type of data, and the second one details the range of useful methods to obtain a successful model.
Part I: Choosing the right metrics
What is an evaluation metric?
An evaluation metric quantifies the performance of a predictive model. Choosing the right metric is almost mandatory when evaluating Machine Learning models, and the quality of a classification model depends directly on the metric used to evaluate it.
About classification problems, metrics generally consist in comparing the real classes to the classes predicted by the model. They can also be used to interpret the predicted probabilities for these classes.
One of the key performanceconcepts for classification is the confusion matrix, which is a tabular visualization of the model predictions against the true labels. Each row of the confusion matrix represents the instances of a real class and each column represents the instances of a predicted class.
Let’s take the example of a binary classification, where we have 100 positive instances and 70 negative instances.
The confusion matrix below corresponds to the results obtained by our model:
It gives an overview of the correct and false predictions.
To summarize this matrix in a metric, it is possible to use the rate of good predictions or accuracy. Here it is equal to (90+57)/170 = 0.86.
The choice of an appropriate metric is not obvious for any Machine Learning model, but it is particularly difficult for unbalanced classification problems.
In the case of data with a strong majority class, classical algorithms are often biased because their loss functions try to optimize metrics such as the rate of good predictions, without taking in account the data allocation.
In the worst case, minority classes are treated as outliers of the majority class and the learning algorithm simply generates a trivial classifier that classifies each example into the majority class. The model will appear to perform well but this will only reflect the overrepresentation of the majority class. This is called paradoxical accuracy.
In most cases, the minority class represents the greatest interest and that we would like to be able to identify, as in the example of fraud detection.
The imbalance level varies but the use cases are recurrent: disease screening test , failure detection, search engine, spam filtering, marketing targeting…
Practical application: Churn Rate
Let’s assume that a service company wants to predict its churn rate.
Little reminder: the churn rate’s ratio is the following : lost customers / total number of customers, measured over a given period, usually one year.
The company wants to predict for each customer whether he will end his contract at the end of the year.
We have a dataset containing personal information and contract characteristics of each customer of the company for the year X, as well as a variable to know if he renewed his contract at the end of the year.
In our data, the number of ‘churners’ corresponds to 11% of the total number of customers.
We decide to train a first logistic regression model on our prepared and normalized data.
Surprise! Our code displays a good prediction rate of 0.90!
This is a very good score, but our goal is to predict the possible departure of customers. Does this result mean that out of 10 churners, 9 will be identified as such by the model? No!
The only interpretation that can be made is that 9 out of 10 customers have been well classified by the model.
To successfully detect naive behavior in a model, the most effective tool is always the confusion matrix.
A first look at the confusion matrix shows us that the good prediction rate obtained is largely influenced by the good behavior of the model on the dominant class (0).
In order to evaluate the model related to the desired behavior on a class, it is possible to use a series of metrics from the confusion matrix, such as precision, recall, and f1-score, defined below.
Thus for a given class:
A high precision and a high recall -> The class has been well managed by the model
High precision and low recall -> The class is not well detected but when it is, the model is very reliable.
Low precision and high recall -> The class is well detected, but also includes observations of other classes.
Low precision and low recall -> the class has not been handled well at all
The F1 score measures both precision and recall.
In the case of binary classification, the sensitivity and specificity correspond respectively to the recall of the positive and negative classes.
Another metric, the geometric mean (G-mean), is useful for unbalanced classification problems: it is the root of the product of sensitivity and specificity.
These different metrics are easily accessible thanks to the imblearn package.
The classification_report_imbalanced() function allows displaying a report containing the results on all the metrics of the package.
We obtain the following table:
The table shows that the recall and f1-score for class 1 are bad, while for class 0 they are high. In addition, the geometric mean is also low.
Thus, the trained model does not fit our data.
In Part II, we will discover methods that will allow us to obtain much better results.
You want to improve your skills to build efficient and reliable models from unbalanced data sets? Discover all our learning modules!
Take your future into your own hands. Choose your desired start date, and begin your application by filling out the appointment form.
Bootcamp
Tuesday 8 September 2026
Analytics Engineer
Remote
English
Bootcamp
Tuesday 3 November 2026
Analytics Engineer
Remote
English
Upcoming starting dates
Take your future into your own hands. Choose your desired start date, and begin your application by filling out the appointment form.
No upcoming dates
THE TEaM
They won’t leave until you land your dream job and celebrate with you 🍾
Liora is more than a training. It’s a whole team walking forward with you, step by step, until you get hired. Mentors, coaches, instructors… all committed to your success.
Estelle
Career Associate
Vincent
Career Associate
Magali
Career Associate
Bilal
Career Associate
Kahina
Career Associate
THE SUPPORT
Support built for your success
Our structured support and expert training open real career opportunities in data, cyber, and tech.
Premium resources just for you
A private platform with exclusive insights on market shifts and career strategy.
A Slack space to log in, ask questions, and grow with fellow learners.
Stay updated with expert tips on trends, events, and career moves.
Individual career coaching, tailored for you
From day one, our Career Team supports you with personalized coaching. We help you:
Shape your career path around your goals and experience.
Find the right opportunities and fine-tune your job search strategy.
Get personalized advice to level up your job hunt.
High-impact career workshops
Our expert-led group sessions help you prepare for the job market: from polishing your CV and LinkedIn to nailing interviews, building a smart job search strategy, crafting your pitch, and building your network.
A strong network that opens doors
We connect you with recruiters through job fairs, speed-dating sessions, and curated industry events.
The impact of our support in numbers
52k€
Average gross salary of our alumni
Real proof that our programs lead to high-quality, high-paying jobs in data, tech, and AI.
9.53/10
Satisfaction for individual coaching
With 1000+ coachings delivered each year, our live support gives you direct access to industry experts to ask, unblock, and accelerate your job hunting process.
9.1/10
Satisfaction for group workshops
Hands-on sessions that help you improve your CV, LinkedIn, interview skills, and job search strategy.
71%
Employment rate
within 6 months of graduating a clear sign of how effective our training and career support really are.
70+
career-focused workshops every year
covering key topics like employability, networking, career transitions, and personal branding tailored to every learner.
4
recruitment fairs per year
Whether online or in person, these exclusive events create real connections between our talent and recruiters.
They benefited from our Career Support
Great Training Bootcamp! Thanks to the way Datascientest teaches and the constant support provided by the teachers, I was able to get the practical da…
James
I learned a lot in the program it is really an amazing platform to grow with your career and start with potential. I really felt helped and received a…
Rajini Sharma
I am really amazed by the human quality of the Hack A Boss team, Selene, Dmitry, Pablo and Daniel are amazing people who are willing to help and teach…
Simon Cariou
I recently finished my Bootcamp for Data Analyst and I am very happy with the knowledge I gained and experience it gave me. The modules were very clea…
Matea Mutz
I find this platform is the best because it's an intelligent way of learning in this era, just text content plus some needed short tutorial videos. al…
Ahmed
I am really amazed by the human quality of the Hack A Boss team, Selene, Dmitry, Pablo and Daniel are amazing people who are willing to help and teach…
Lautaro Martinez
Just finished training yesterday (3 + 2 days). Group interactivity was effective, the instructor was very responsive. His experience in business as co…
Stéphane Bourain
Finance Controller
I would like to share with you a great experience lived recently by following "Data Analyst Training". I have learnt lots of skills (Python, Data Anal…
Khalid
Very high-quality training. Thank you for the presentation. I strongly recommend this training provider. It covers nearly all the key aspects needed t…
Mohamed Haijoubi
Data Engineer
I completed a Data Engineer training program at DataScientest, and overall, the course is well-structured — a balanced mix of projects, theory, and …
Moustafa B
SRE Lead
Now certified and very satisfied with the Data Scientist training, I’ve decided to continue my journey with DataScientest by enrolling in the MLOps …
Alexandre L
An excellent training provider for Data-related careers. The courses are well-designed, and you’re quickly challenged through exams after each modul…
Rémy
The training offers a solid overview of various Machine Learning techniques, and access to a wealth of content — including coaching sessions, alumni…
Anonymous
The bootcamp program is really intensive, specially for a person who has no programming background, but the course is definitely worth it. It helped m…
Shiva
As part of my career transition, I pursued my DevOps training through a work-study program at DataScientest. I chose to follow both courses with DataS…
Nicolas Utter
Content Creator
Awesome education, awesome people.
Alexander P
I'm delighted to share my experience with this bootcamp! After completing my bachelor's degree, I was searching for a way to work with computers and d…
Dotun Olujide
A lot of things to learn and a lot of information! was an amazing experience.
Tiago R
I’d like to share my feedback following the high-quality training I completed on Microsoft Power BI, delivered by DataScientest. This experience was…
Anonymous
Excellent course with practical focus! Really enhanced my data science skills, directly applicable to my research. Highly recommend DataScientest for …
Lina Livdane
Overall impression is good. The course content is well-organized, thoroughly designed and challenging as well. In the end, I believe I am well-prepare…
Khoa Tran
I really enjoyed the course material and the fact that everything was remote. Well I haven’t finished the MLOps part yet. The data science part was …
Marius
Onboarding was smooth & lessons on your own & remote were particularly adequate to me
Clément Dué
Loved the format which was perfect for me – as a young parent. Additionally, I found the resources (platform) to be very good, and the instructors to …
Christian Müller
AI Scientist
I successfully completed my Data Analyst training last month and was very satisfied — within just six months, I was able to learn the key fundamenta…
Henry
Angelika Tabak
DataScientist.com is always interested in maintaining a good reputation and producing good graduates. But don’t be afraid, the instructors are very …
Baris Ersoy
PL/SQL Developer
I’m really glad I chose DataScientest. Balancing work, family, languages – and now data – learning is challenging, and their flexible format makes i…
Debora Ferreira
Probably the best Data & AI training course out there. Loved the structure, depth and hands-on approach of the Data Science & MLOps course. I …
Benjamin S.
Data Scientist
The content of the module undoubtedly covers the most important aspects of Machine Learning and MLOps. The final project allows you to put into practi…
Darwin Oca
As a seasoned software engineer with many years of experience, I was looking to refresh my IT skills and deepen my knowledge in data-related technolog…

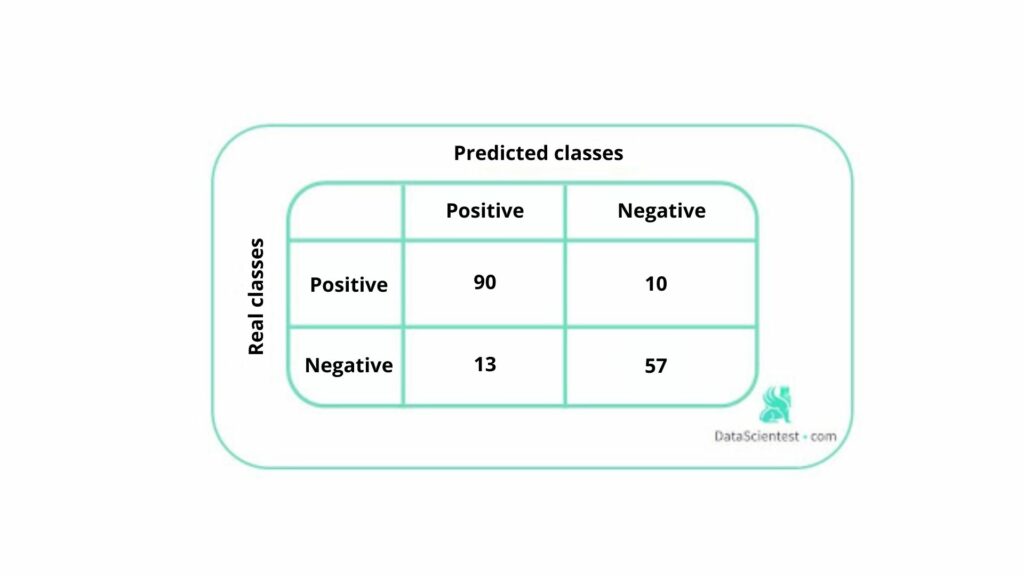 It gives an overview of the correct and false predictions.
To summarize this matrix in a metric, it is possible to use the rate of good predictions or accuracy. Here it is equal to (90+57)/170 = 0.86.
The choice of an appropriate metric is not obvious for any Machine Learning model, but it is particularly difficult for unbalanced classification problems.
In the case of data with a strong majority class, classical algorithms are often biased because their loss functions try to optimize metrics such as the rate of good predictions, without taking in account the data allocation.
In the worst case, minority classes are treated as outliers of the majority class and the learning algorithm simply generates a trivial classifier that classifies each example into the majority class. The model will appear to perform well but this will only reflect the overrepresentation of the majority class. This is called paradoxical accuracy.
In most cases, the minority class represents the greatest interest and that we would like to be able to identify, as in the example of fraud detection.
The imbalance level varies but the use cases are recurrent: disease screening test , failure detection, search engine, spam filtering, marketing targeting…
It gives an overview of the correct and false predictions.
To summarize this matrix in a metric, it is possible to use the rate of good predictions or accuracy. Here it is equal to (90+57)/170 = 0.86.
The choice of an appropriate metric is not obvious for any Machine Learning model, but it is particularly difficult for unbalanced classification problems.
In the case of data with a strong majority class, classical algorithms are often biased because their loss functions try to optimize metrics such as the rate of good predictions, without taking in account the data allocation.
In the worst case, minority classes are treated as outliers of the majority class and the learning algorithm simply generates a trivial classifier that classifies each example into the majority class. The model will appear to perform well but this will only reflect the overrepresentation of the majority class. This is called paradoxical accuracy.
In most cases, the minority class represents the greatest interest and that we would like to be able to identify, as in the example of fraud detection.
The imbalance level varies but the use cases are recurrent: disease screening test , failure detection, search engine, spam filtering, marketing targeting…
 Thus for a given class:
Thus for a given class:
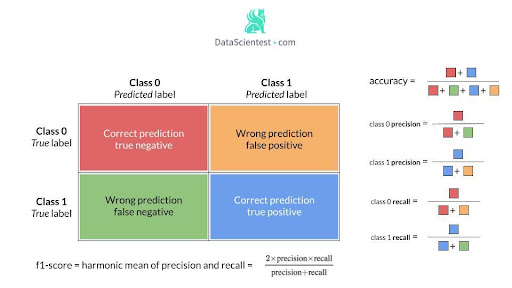 The table shows that the recall and f1-score for class 1 are bad, while for class 0 they are high. In addition, the geometric mean is also low.
Thus, the trained model does not fit our data.
In Part II, we will discover methods that will allow us to obtain much better results.
You want to improve your skills to build efficient and reliable models from unbalanced data sets? Discover all our learning modules!
The table shows that the recall and f1-score for class 1 are bad, while for class 0 they are high. In addition, the geometric mean is also low.
Thus, the trained model does not fit our data.
In Part II, we will discover methods that will allow us to obtain much better results.
You want to improve your skills to build efficient and reliable models from unbalanced data sets? Discover all our learning modules!

























