

Amazon Web Services lanzó este lunes dos nuevas herramientas de monitorización para su plataforma de IA Bedrock, brindando a los desarrolladores visibilidad en tiempo real sobre el rendimiento y el uso de recursos en sus aplicaciones de IA generativa. Las métricas de CloudWatch, TimeToFirstToken y EstimatedTPMQuotaUsage, miden los tiempos de respuesta ante solicitudes de IA en streaming y rastrean el consumo de tokens para evitar interrupciones del servicio, lo cual permite a los equipos crear aplicaciones de IA más fiables sin supervisión adicional del lado del cliente.
Las nuevas capacidades llegan en un momento en que las empresas lidian cada vez más con cuellos de botella de rendimiento y sobrecostos en sus implementaciones de IA, especialmente al utilizar modelos de alto consumo de recursos como Claude de Anthropic, que aplica un 5x burndown rate a los tokens de salida. Esto significa que 100 tokens de salida en realidad consumen 500 tokens de la cuota disponible, un cálculo que antes resultaba opaco para los desarrolladores.
TimeToFirstToken mide la latencia del lado del servidor en milisegundos desde que Bedrock recibe una solicitud en streaming hasta que genera el primer token de respuesta, brindando señales de rendimiento puras no afectadas por las condiciones de la red. La métrica funciona exclusivamente con APIs de streaming, incluyendo ConverseStream e InvokeModelWithResponseStream.
EstimatedTPMQuotaUsage rastrea cómo las solicitudes de inferencia consumen las cuotas de Tokens Per Minute (TPM), teniendo en cuenta burndown multipliers específicos del modelo y otros factores internos. El cálculo varía según el modelo de throughput: on-demand throughput suma los tokens de entrada, las escrituras en caché y los tokens de salida multiplicados, mientras que provisioned throughput aplica ponderaciones diferentes a las operaciones en caché.
Gestión proactiva del rendimiento
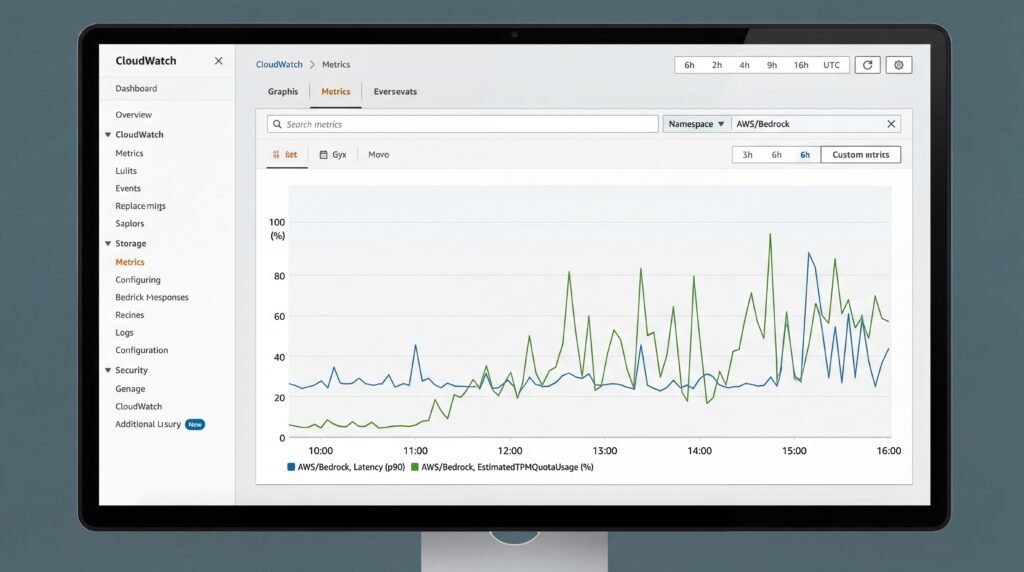
Según el AWS Machine Learning Blog, las métricas se emiten automáticamente en el namespace AWS/Bedrock de CloudWatch para todas las solicitudes de inferencia exitosas, sin un costo adicional más allá del uso estándar del modelo. Esta visibilidad del lado del servidor elimina la necesidad de instrumentación del lado del cliente que muchos equipos antes desarrollaban por su cuenta.
Los equipos de ingeniería ahora pueden establecer Service Level Objectives y crear alarmas automatizadas. Para aplicaciones sensibles a la latencia, los equipos podrían configurar alertas cuando el percentil 90 de los tiempos de respuesta supere los 500 milisegundos. Las aplicaciones de alto throughput pueden activar advertencias cuando el consumo se acerque al 80 % de la cuota disponible, para evitar interrupciones del servicio antes de que ocurran.
Las métricas se integran con herramientas de Infrastructure as Code como CloudFormation y Terraform, lo cual permite a los equipos definir estrategias de monitorización de forma programática. Las señales de alerta temprana de EstimatedTPMQuotaUsage pueden activar circuit breakers o reducir las tasas de solicitud antes de que los errores de throttling afecten a los usuarios.
Implicaciones competitivas
El lanzamiento posiciona a AWS de forma más competitiva frente a rivales como Microsoft Azure y Google Cloud, que ofrecen sus propias soluciones de monitorización para plataformas de IA. A medida que la IA generativa pasa de la experimentación a los despliegues en producción, la visibilidad operativa se vuelve crucial para la adopción empresarial.
El momento coincide con la creciente demanda empresarial de mejores herramientas de gestión de costos de IA y optimización del rendimiento, especialmente a medida que las compañías escalan sus implementaciones de IA generativa más allá de los programas piloto hacia aplicaciones de misión crítica que atienden a millones de usuarios.
Sources
- aws.amazon.com/blogs
