
Investigadores del MIT y de la Universidad Politécnica de Milán han desarrollado un nuevo método de inteligencia artificial que explica automáticamente cómo los modelos de IA toman decisiones, con el potencial de transformar ámbitos de alto riesgo como el diagnóstico médico. El Mechanistic Concept Bottleneck Model (M-CBM) extrae y nombra los conceptos que los sistemas de IA realmente utilizan para sus predicciones, brindando explicaciones más precisas y comprensibles que los enfoques anteriores que dependían de conceptos definidos por humanos.
El avance aborda un desafío crítico que ha obstaculizado la adopción de la inteligencia artificial en la atención sanitaria y otros sectores delicados: la incapacidad de los sistemas de IA para expresar con claridad su razonamiento. Publicado en la International Conference on Learning Representations (ICLR) 2026, el trabajo demuestra cómo el nuevo sistema puede identificar y nombrar las características visuales específicas que utiliza al diagnosticar lesiones cutáneas o al clasificar especies de aves, según MIT News.
Dirigido por Antonio De Santis de la Universidad Politécnica de Milán y del Computer Science and Artificial Intelligence Laboratory (CSAIL) del MIT, el equipo de investigación desarrolló un proceso de cuatro etapas que transforma de manera radical cómo funcionan las explicaciones de IA. En lugar de forzar a los modelos a utilizar conceptos definidos por humanos que podrían no coincidir con su proceso de toma de decisiones real, el sistema extrae conceptos que la IA ya ha aprendido a considerar relevantes.
Avance técnico
El M-CBM utiliza un Sparse Autoencoder para analizar modelos preentrenados e identificar sus características aprendidas más críticas. A continuación, un modelo lingüístico multimodal genera automáticamente descripciones en lenguaje natural para cada concepto descubierto, tendiendo un puente directo entre representaciones internas complejas y la comprensión humana. El sistema se limita a utilizar solo cinco conceptos por predicción, asegurando que las explicaciones sigan siendo asimilables sin perder precisión.
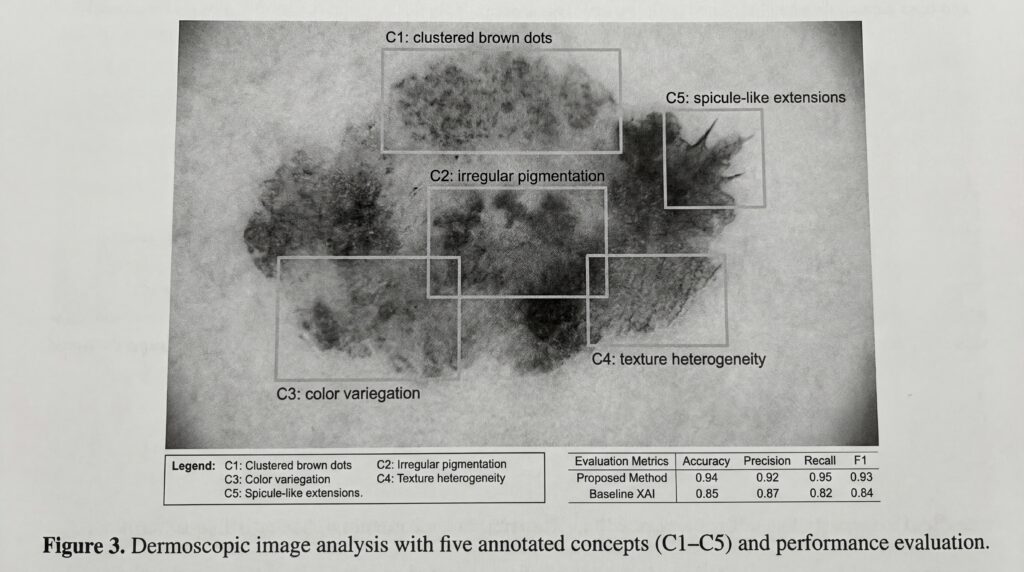
En pruebas sobre análisis de imágenes médicas y tareas de identificación de especies, el M-CBM logró mayor exactitud que los métodos de IA explicable existentes, a la vez que generaba explicaciones más precisas, según el artículo de investigación. Al analizar lesiones cutáneas, por ejemplo, el sistema puede especificar que detectó rasgos como «puntos marrones agrupados», lo que permite a los médicos evaluar si deben confiar en su diagnóstico.
Impacto en el mercado y limitaciones
A pesar del avance, persisten desafíos significativos. «Los modelos opacos que no son interpretables aún superan al nuestro», admitió De Santis, subrayando el persistente dilema entre exactitud e interpretabilidad. El equipo también advirtió sobre una posible fuga informativa, en la que los modelos podrían «usar en secreto conceptos de los que no somos conscientes», lo que podría socavar la fiabilidad de las explicaciones.
Las implicaciones para el despliegue de IA en sanidad son enormes. A medida que aumenta la presión regulatoria para contar con sistemas de IA transparentes en entornos médicos, herramientas como M-CBM podrían acelerar la adopción al proporcionar la rendición de cuentas que exigen los clínicos y reguladores. Los investigadores planean escalar el método empleando modelos lingüísticos más potentes para reducir aún más la brecha de desempeño con los sistemas no interpretables.
Sources
- news.mit.edu
