

Los investigadores desarrollaron P-EAGLE, un nuevo sistema que acelera los modelos de lenguaje de inteligencia artificial hasta en un 69 % en comparación con los métodos actuales. La tecnología, probada en las últimas GPU B200 de NVIDIA, genera múltiples predicciones de texto de forma simultánea en lugar de una por vez, eliminando un cuello de botella importante que ralentiza las respuestas de la IA en aplicaciones como ChatGPT.
El avance aborda un desafío fundamental en la forma en que los sistemas de IA procesan y generan texto. Los métodos tradicionales como EAGLE-3 deben generar cada palabra prevista de manera secuencial, esperando a que termine una antes de comenzar la siguiente. P-EAGLE supera esta limitación al procesar todas las predicciones en un único paso computacional, según la investigación publicada en el AWS Machine Learning Blog.
Este cambio arquitectónico tiene beneficios prácticos inmediatos. Tras evaluarse en cargas de trabajo que incluyen generación de código y conversaciones de varios turnos, el sistema alcanzó su máxima aceleración de 1.69x en tareas de generación de código de formato extenso. La tecnología mantuvo una mejora de 1.55x tanto en la síntesis de código a nivel de función como en benchmarks de IA conversacional, demostrando un desempeño constante en diversas aplicaciones.
Innovación técnica
La innovación clave radica en cómo P-EAGLE maneja la información faltante durante la generación de texto. Mientras que los sistemas anteriores requerían tokens reales y estados internos de cada paso antes de continuar, P-EAGLE sustituye los datos no disponibles por parámetros entrenables llamados «mask token embeddings» y estados ocultos compartidos. Esto permite al sistema procesar múltiples posiciones simultáneamente sin esperar salidas secuenciales.
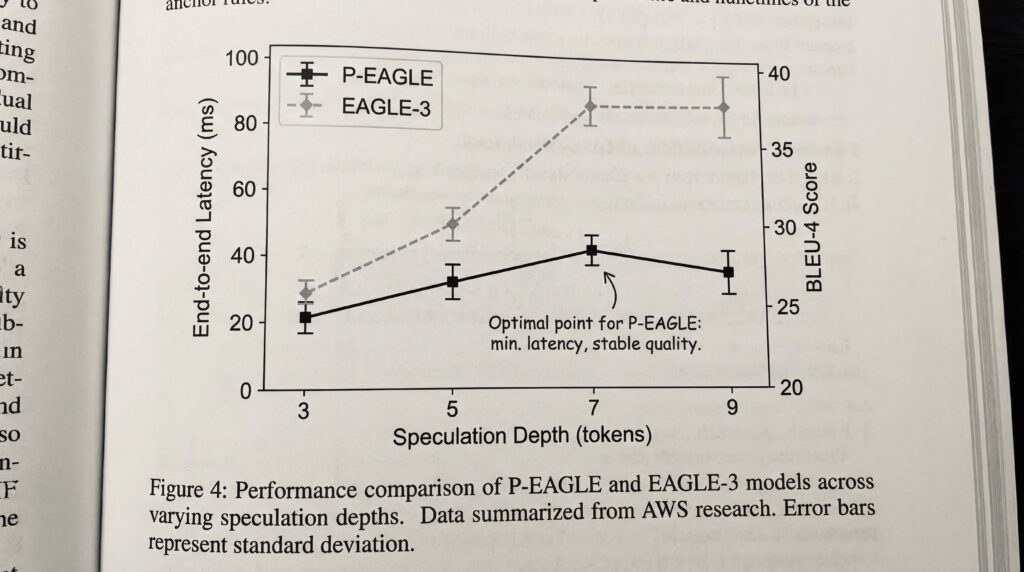
Quizá lo más significativo sea que P-EAGLE puede aprovechar efectivamente una mayor profundidad especulativa. El sistema alcanzó el rendimiento óptimo con una profundidad especulativa de siete tokens, frente a solo tres en el EAGLE-3 tradicional, según la investigación de AWS. Esta capacidad de especulación más profunda se traduce directamente en tiempos de respuesta más rápidos para los usuarios finales.
Disponibilidad en el mercado y contrapartidas
La tecnología ya está integrada en el servidor vLLM bajo una licencia Apache 2.0, lo que la hace disponible de forma gratuita para uso comercial. Los modelos preentrenados compatibles con P-EAGLE están disponibles en Hugging Face para sistemas de IA populares, incluidos GPT-OSS y Qwen3-Coder.
El principal inconveniente es un mayor consumo de memoria por las matrices de atención más grandes de la arquitectura paralela. Sin embargo, el equipo de AWS desarrolló un «algoritmo de partición secuencial» para gestionar la memoria requerida durante el entrenamiento, lo que hace que el sistema sea práctico para su despliegue en el mundo real.
Cabe destacar que P-EAGLE mantiene una calidad sin pérdidas, produciendo resultados idénticos a los métodos estándar y logrando mayores tasas de aceptación para el texto generado, lo que indica predicciones más precisas con menos correcciones necesarias.
Sources
- aws.amazon.com/blogs/machine-learning
